2635
Automated Billing Code Prediction from MRI Log Data1University of Erlangen-Nuremberg, Erlangen, Germany, 2Siemens Healthineers, Erlangen, Germany, 3Inselspital, University of Bern, Bern, Switzerland, 4Technical University of Applied Sciences Amberg-Weiden, Amberg, Germany
Synopsis
We developed an algorithm that is capable of retrieving MRI billing codes from MRI log data. This proof-of-concept work is applied to Tarmed, the Swiss fee-for-service tariff system for outpatient services, and is tested on two MRI scanners, a MAGNETOM Aera and a MAGNETOM Skyra (Siemens Healthcare, Erlangen, Germany), of a single radiology site. A machine learning approach for automated MRI billing code retrieval from MRI log data is implemented. The proposed algorithm reliably predicts medical billing codes for MRI exams (F1-score: 97.1%). Integrated in the clinical environment, this work has the potential to reduce the workload for technologists, prevent coding errors and enable scanner-specific expense and turnover analysis.
Introduction
Despite ongoing measures to improve technology and clinical workflow, MRI exams remain time consuming and are cost intensive. It is therefore crucial to properly claim incurred costs by reporting the correct set of medical billing codes. In the current MRI workflow of the investigated site, a technologist manually enters the conducted procedures and associated billing codes into the radiology information system (RIS). However, billing for MRI exams can be error-prone and billing codes are either missed (undercoding) or falsely added (overcoding). Thus, we have developed an algorithm that can automatically retrieve MRI billing codes from MRI log data, which has the potential to reduce the number of errors and enhance the MRI workflow by reducing the workload for the technologist. Recent work on automation of medical coding has rather focused on the retrieval of diagnosis codes from free text documents and electronic health records [1–4] than on billing codes. The MRI log data (containing the executed sequences, scanner table movement, registered body region, etc.) is processed with the consent of the radiology site. The MRI log data serves as basis of the feature data for the training of the algorithm to predict billing codes of an MRI exam. The target data (i.e. billing codes), crucial for training of the algorithm, is extracted from the RIS of the hospital.Methods
In the first step of the classification pipeline of the developed prototype, features are extracted from the sequences executed during the MRI exam, including a subset of sequence parameters, MRI scanner table movements (e.g. total table movement) and anonymized patient information (age, gender). Additionally, the registered body region and information whether contrast medium was injected are used as features. The executed sequences provide useful information for the identification of the conducted procedure. However, the sequence names can be adapted individually and therefore they are not comparable and meaningful features for the characterization of an MRI exam. Therefore, in the second step of the classification pipeline, normalized sequence names are automatically generated solely based on their underlying parameters, increasing the generalization ability of the classification model while decreasing the training time. In the last step, a feed-forward neural network with a single hidden layer is trained using the billing codes extracted from the RIS as target data.Results
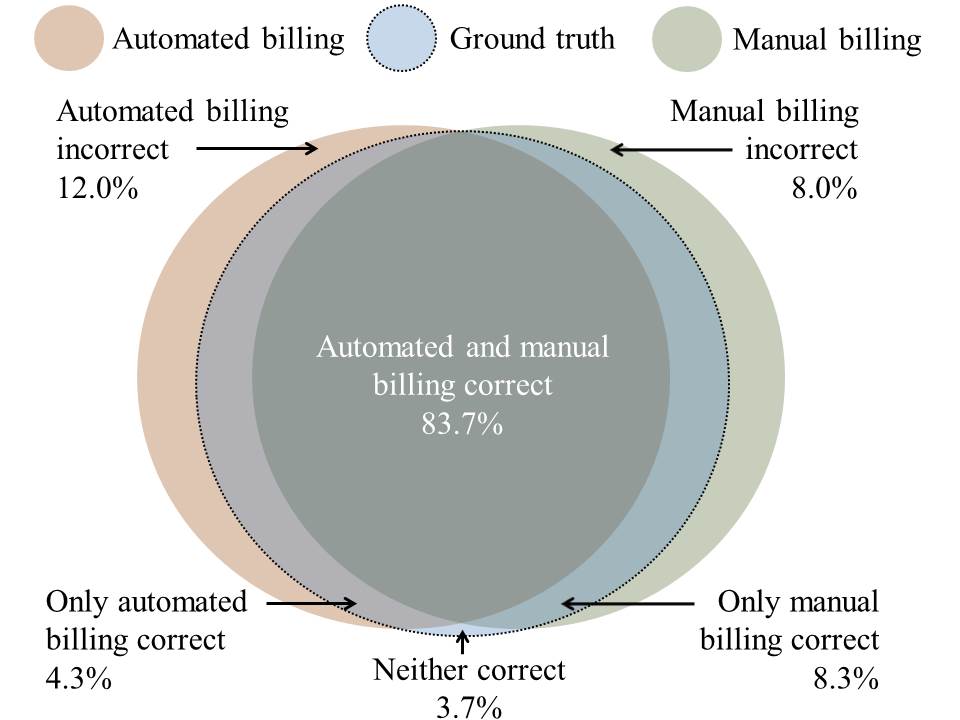
The training set consisted of 7,972 MRI exams and the test set of 448 MRI exams. Not all billing codes that occurred in the billing data for MRI exams were predicted, since some codes could not be retrieved from the MRI log data (e.g. a surcharge code for narcotized patients). After data cleaning, 22 billing codes remained, with 4.1 billing codes assigned per MRI exam on average. It was observed that the target data was erroneous due to manual billing errors (under-/overcoding). Thus, the target data of the test set were corrected exam-wise to generate a ground truth test dataset, which allowed to both evaluate the performance of the manual billing (i.e. billing codes entered manually by the technologist) and the automated prediction. The final prediction model for automated billing yielded 97.1% micro-averaged F1-score, 96.9% precision and 97.3% recall. The manual billing yielded 98.0% micro-averaged F1-score, 98.7% precision and 97.4% recall. Thus, the manual billing was still superior to the prediction. Moreover, the predictive accuracy of automated billing was compared to manual billing (Figure 1). For 3.7% of the test instances, neither manual billing nor the prediction generated the correct set of billing codes. However, while the manual billing was superior to the prediction in 8.3% of the test instances, the prediction was also superior in 4.3% of the test instances. Thus, the prediction outperformed manual billing for a significant share of the test instances, although the predictive accuracy was still lower.Discussion and Conclusion
The results show the potential of a machine learning application for the task of automated billing for MRI exams, with a performance that is close to the human performance. MRI log data offers a variety of information but also has some limitations – the log data contains gaps due to logging errors and offers only incomplete information (e.g. the type and amount of injected contrast agent is missing). It is reasonable to assume that the algorithm can also be applied to a similar data basis, such as DICOM header information. The manually corrected test data allows to evaluate manual billing errors and shows that the billing procedure has to be improved to reduce errors. This improvement can be achieved with a computer-aided or even automated billing workflow for MRI exams. Consequently, incorporating the algorithm into the billing workflow has the potential to increase the reimbursement for MRI exams by reducing missed billing codes.Acknowledgements
No acknowledgement found.References
1. Atutxa A, Perez A, Casillas A. Machine Learning approaches on Diagnostic Term Encoding with the ICD for Clinical Documentation. IEEE journal of biomedical and health informatics. doi:10.1109/JBHI.2017.2743824.
2. Kavuluru R, Rios A, Lu Y. An empirical evaluation of supervised learning approaches in assigning diagnosis codes to electronic medical records. Artificial intelligence in medicine:155–166. doi:10.1016/j.artmed.2015.04.007.
3. Koopman B, Zuccon G, Nguyen A, Bergheim A, Grayson N. Automatic ICD-10 classification of cancers from free-text death certificates. International Journal of Medical Informatics:956–965. doi:10.1016/j.ijmedinf.2015.08.004.
4. Perotte A, Pivovarov R, Natarajan K, Weiskopf N, Wood F, Elhadad N. Diagnosis code assignment: models and evaluation metrics. Journal of the American Medical Informatics Association JAMIA:231–237. doi:10.1136/amiajnl-2013-002159.
Figures