1398
Fully automatic segmentation of all lower body muscles from high resolution MRI using a two-step DCNN model1Springbok, Inc., Charlottesville, VA, United States
Synopsis
Lower limb skeletal muscles play an essential role in athletic performance as wellas muscular health in patients with dystrophies. Quantitative mapping of all 35 lower body muscles from high resolution MRI has the potential to improve power and agility in athletes and assist the diagnosis and follow-up for certain musculardystrophies in medical applications. However, due to the weak contrast and insufficient boundary information, the accurate segmentation of each individual muscle is challenging. In this study we developed a fully automatic segmentation framework using a two-step DCNN model and showed accurate segmentation for all muscles.
Introduction
Lower limb skeletal muscles, as the producer of force and motion, play an essential role in athletic performance as well as muscular health in patients with dystrophies. Quantitative mapping of all 35 lower body muscles from high resolution MRI has the potential to improve power and agility in athletes by targeted training1 and assist the diagnosis and follow-up for certain muscular dystrophies2 in medical applications. However, due to the weak contrast and insufficient boundary information, the accurate segmentation of each individual muscle is challenging. As the image volume is very large, the segmentation process can take more than 30 hours even with well-trained engineers and suffers from inter-observer variability. Given the recent success of deep learning based methods in medical image segmentation3, we propose a fully automatic segmentation framework using deep convolutional neural network (DCNN) based on 3D U-Net4 for this task.Methods
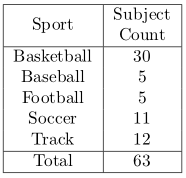
For each subject, to cover all 35 lower body muscles, proton density weighted images are acquired from T12 to ankle using a customized 2D multi-slice spiral protocol or a Cartesian protocol with parallel imaging to reduce scan time. The in-plane resolution is 1 mm * 1mm with matrix size 512x512 for spiral and 476x380 for Cartesian. The slice thickness is 5 mm with 200-240 slices in total. The scan time is about 25 minutes for spiral, and 30 minutes using the Cartesian protocols. A total of 63 subjects are collected with the detailed information shown in Table 1. All muscles are segmented and vetted by trained engineers. 50 subjects were used for training, and 13 for testing. In pre-processing, improved N3 bias correction5 is used to correct for inhomogeneity. Due to the relatively small training size, instead of using one model to segment all muscles at the same time, using dedicated models for each individual muscle can greatly improve the accuracy. As the raw 3D data set is too large to fit into the GPU memory without significant shrinking, we develop a two-step model with two DCNN networks. The goal of the first step is to obtain a bounding box that encloses the muscle to be segmented from coarsely segmented labels using low resolution data set, which is then be used to crop the original 3D data set to only contain relevant regions. To allow for segmentation errors, the images are cropped at a slightly enlarged bounding box to avoid losing information. A second DCNN network is trained to segment the muscle of interest from cropped images at close to the original resolution so that the details are maintained to improve segmentation accuracy. Both DCNN models have the same network architecture, which is a modified 3D-UNet that resembles RESNET6, where residual connections are added between each convolution and deconvolution blocks. Random rotation, scaling and shear are introduced to the 3D images to augment the dataset. Training time on an NVidia 1080Ti GPU for one muscle is 12hrs (4hrs for step 1 with 2k epochs and 8hrs for step 2 with 5k epochs). 6 bones are also segmented, so, the total number of ROI is 76. Multiple GPUs are run in parallel to reduce the total training time. During testing, the results from all models are combined with post-processing including connected component analysis to ensure that only one connected 3d volume is kept for each ROI and binary closing to guarantee that the predicted volumes are dense and closed. Conflict from different models for a pixel is resolved by their corresponding predicted softmax probabilities, highest wins. Dice score against manual segmentation is used to evaluate the performance of our method. As a comparison, an inter-observer study was performed with three well-trained engineers segmenting one data set.Results
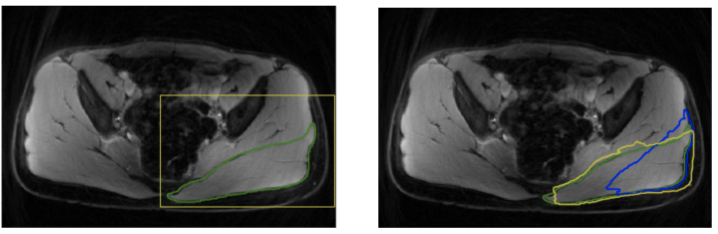
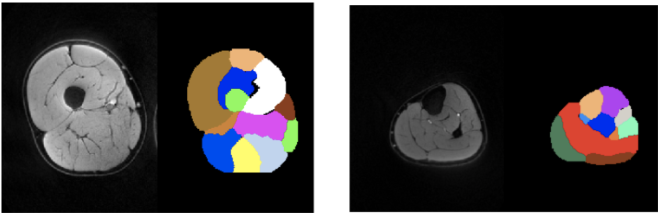
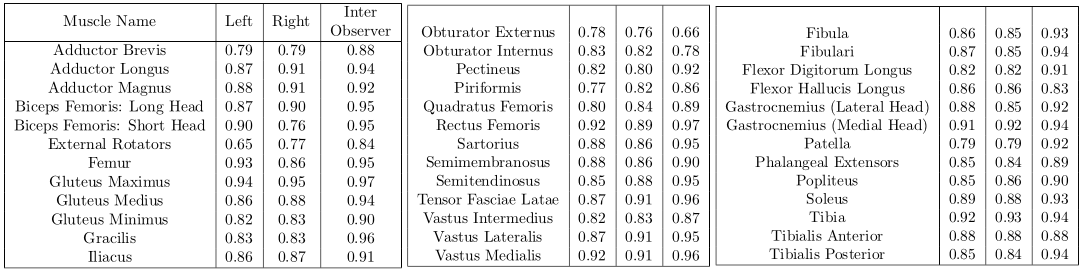
Table 2 summarizes the dice scores from the proposed method. Most muscles have dice scores comparable to inter-observer variability. Figure 1 shows the results of bounding box extraction in step1 and segmentation in both steps along with ground truth contour. Muscles are located correctly in step1 but not segmented properly. Step2 performs much more accurate segmentation. Figure 2 shows final result from both upper leg and lower leg. All muscles are segmented well even with partial boundary information.Conclusion
We have developed a two-step DCNN model for accurate segmentation of all lower limb muscles. The contour information can be used to quantify important characteristics such as muscle sizes and lengths to enhance performance and improve muscular health.Acknowledgements
References
1. Handsfield GG, Knaus KR, Fiorentino NM, et al. Adding muscle where you need it: non-uniform hypertrophy patterns in elite sprinters. Scand J Med Sci Sports. 2016. 27(10):1050-1060.
2. Diaz-Manera J, Llauger J, Gallardo E, et al. Muscle MRI in muscular dystrophies. Acta Myol. 2015. 34(2-3): 95-108.
3. Ronneberger O, Fischer P, Brox T. U-Net: convolutional networks for biomedical image segmentation. arXiv:1505.04597 [cs.CV]. 2015.
4. Cicek O, Abdulkadir A, Lienkamp SS, et al. 3D U-Net: learning dense volumetric segmentation from sparse annotation. arXiv:1606.06650 [cs.CV]. 2016.
5. Tustison NJ, Avants BB, Cook PA, et al. N4ITK: improved N3 bias correction. IEEE Trans Med Imaging. 2010. 29(6): 1310-1320.
6. He K, Zhang X, Ren S, et al. Deep residual learning for image recognition. arXiv:1512.03385 [cs.CV]. 2015.
Figures