1174
Motion Correction in MRI using Deep Convolutional Neural Network1Monash Biomedical Imaging, Monash University, Melbourne, Australia, 2School of Psychological Sciences, Monash University, Melbourne, Australia, 3Department of Electrical and Computer System Engineering, Monash University, Melbourne, Australia, 4Institute of Medicine, Research Centre Juelich, Juelich, Germany
Synopsis
Patient motion during MR data acquisition appears in the reconstructed image as blurring and incoherent artefacts. In this work, we present a novel deep learning encoder-decoder convolutional neural network (CNN) that recasts the problem of motion correction into an artefact reduction problem. A CNN was designed and trained on simulated motion corrupted images that learned to remove the motion artefact. The motion compensated image reconstruction was transformed into quantized pixel classification, where each pixel in the motion corrupted MR image was classified to its uncorrupted quantized value using a trained deep learning encoder-decoder CNN.
Introduction
Motion during MRI acquisition is a common problem, often encountered in routine MRI examinations. Various motion correction techniques were presented in the past which include image-based motion correction,1 k-space based motion correction 2 and external camera based motion correction.3 In these motion correction techniques, first an estimate of motion is obtained followed by a prospective or retrospective motion correction of MR data. Image and k-space based prospective motion correction requires a redesign of the pulse sequence and often a separate sequence is required for different imaging applications. In this work, we present a retrospective data driven motion correction approach using deep learning that does not require any prior estimate of motion parameters. The deep learning network is trained on simulated, motion corrupted MR data that learns to classify each pixel intensity in the motion corrupted image to its uncorrupted quantized value.Methods
Network Architecture
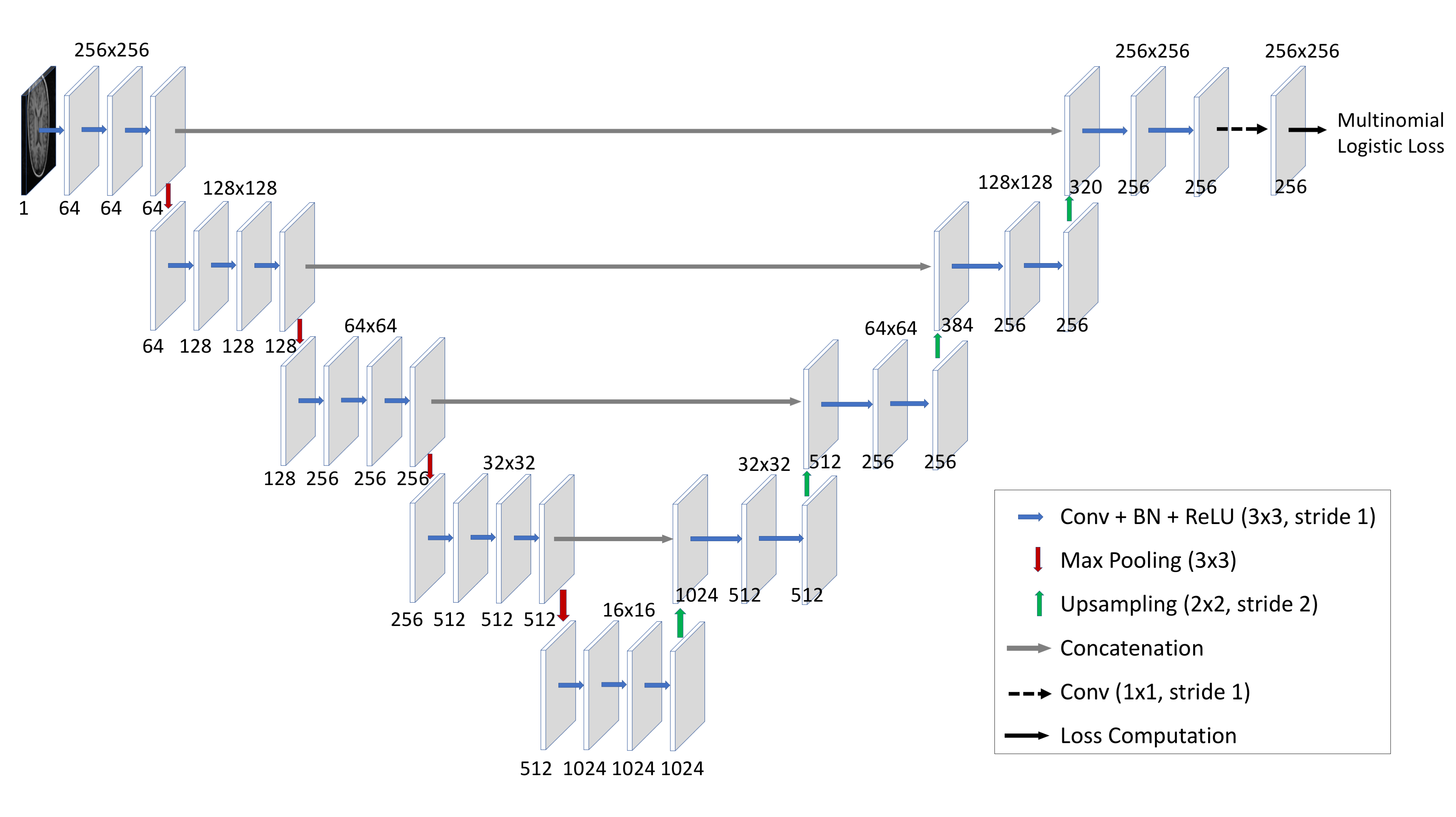
The encoder-decoder CNN architecture shown in Fig.1 is designed for the motion correction. The network transforms the motion corrected image reconstruction to quantized pixel classification. The last layer in the network is a classification layer, that treats the output as a quantized 8-bit image and predicts the probability of each pixel being in one of the 256 different classes. The input to the network is 256x256 motion corrupted image and output is 8-bit quantized motion corrected image.
Data Preparation
2D images from 3D datasets of 43 subjects were used for to generate a training dataset and 10 subjects were used to generate test datasets. In order to generate motion corrupted images, 2D k-space datasets of the images were distorted with a random motion of ±5 mm and ±50 along the phase encode (PE) direction. The severity of the artefact in the motion corrupted image depended on the extent of the motion as well as the location of PE line. For example, motion near the centre of k-space resulted in more blurring and less ringing, while motion in the outer regions of the k-space resulted in more ringing and less blurring.
Training
The following parameter were used for training the network in the caffe4 deep learning library: Stochastic gradient descent was used with initial learning rate = 0.005, momentum = 0.95, inverse decay, total of 100K iteration on NVIDIA Tesla P100 GPU.
Experiments
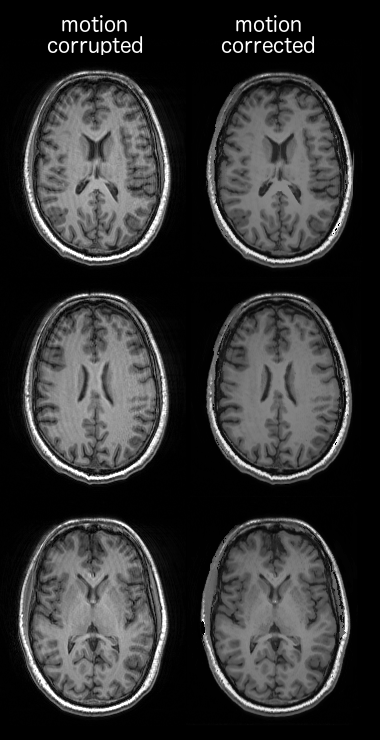
For experimental validation of the proposed motion correction technique, a 3D MPARGE dataset was acquired on 3T MAGNETOM Skyra, (Siemens Healthineers, Erlangen, Germany) with TE/TR = 3/2000 ms, FOV = 256x256x192 mm3, resolution 1 mm isotropic, flip angle = 90. In order to acquire motion corrupted data, the subject was instructed to move during scan. The reconstructed images from motion corrupted k-space data was feed into the trained CNN.
Results
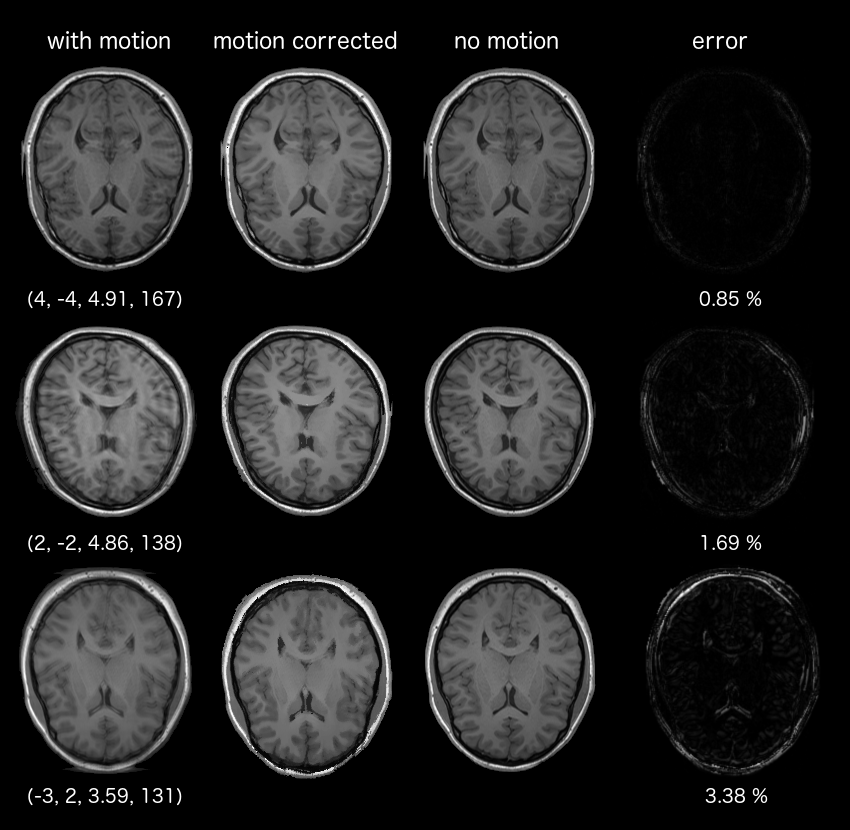
Fig.2 shows the result of applying motion correction on the three test datasets (unseen datasets). It is evident from the motion corrected images that the proposed method is able to correct for the motion artefacts. The accuracy of the motion correction is dependent on the severity of motion corruption and the percentage error lies between 0.85% - 3.38%. Highly accurate motion correction is achieved when motion occurs at the peripheral k-space lines as evident from (rows 1, Fig.2). However, when a sudden dramatic change occurs near the centre of k-space (row 2 and 3, Fig.2), the accuracy of the motion correction is reduced. It should be noted that the error was computed after converting the 8-bit unsigned image to floating point representation (scaled between 0 and 1), hence the total error is a sum of networks' predication error and quantization error. Fig.3 shows results of the motion correction on an experimental dataset, it is evident from images that the trained network is able to remove the motion artefacts.Discussion
Current state-of-the-art motion correction methods that rely on the image or k-space navigators, interfere with the MR protocol and penalize contrast, scan time and SNR. Other methods based on external sensors need calibration and are expensive and complex to setup. The method presented in this work is an innovative solution to motion problem. First unlike navigators, it does not require development or modification of acquisition sequence or image reconstruction methods. Second, it does not interfere with MR protocol parameters such as T1/T2/TI/TE, scan time or contrast. Third, it does not require any external hardware and thus makes it relatively inexpensive to implement. We have presented a proof of concept which demonstrate that deep learning based methods are capable of removing motion artefacts in motion corrupted MR images.Conclusion
An efficient data driven method based on deep convolutional neural network is developed for MR motion correction, that does not require any external sensors or internal navigators for motion correction.Acknowledgements
No acknowledgement found.References
- Gallichan D, Marques JP, Gruetter R. Retrospective correction of involuntary microscopic head movement using highly accelerated fat image navigators (3D FatNavs) at 7T. Magnetic resonance in medicine. 2016 Mar 1;75(3):1030-9.
- Ehman RL, Felmlee JP. Adaptive technique for high-definition MR imaging of moving structures. Radiology. 1989 Oct;173(1):255-63.
- Qin L, van Gelderen P, Derbyshire JA, Jin F, Lee J, de Zwart JA, Tao Y, Duyn JH. Prospective head‐movement correction for high‐resolution MRI using an in‐bore optical tracking system. Magnetic resonance in medicine. 2009 Oct 1;62(4):924-34.
- Y. Jia, E. Shelhamer, J. Donahue, S. Karayev, J. Long, R. Girshick, S. Guadarrama, and T. Darrell. Caffe: Convolutional architecture for fast feature embedding. arXiv preprint arXiv:1408.5093, 2014.
Figures