0657
Efficient Super-Resolution in Intracranial Vessel Wall Magnetic Resonance Imaging using 3D Deep Densely Connected Neural Networks1Department of Bioengineering, UCLA, Los Angeles, CA, United States, 2Biomedical Imaging Research Institute, Cedars-Sinai Medical Center, Los Angeles, CA, United States
Synopsis
Spatial resolution is of paramount importance for intracranial vessel wall (IVW) MR imaging because the vessel wall is submillimeter thin. However, high spatial resolution typically comes at the expense of long scan time, small spatial coverage and low signal-to-noise ratio (SNR). If we can reconstruct a high-resolution (HR) image from a low-resolution (LR) input, we can potentially achieve larger spatial coverage, higher SNR and better spatial resolution in a shorter scan. In this work, we propose a new Single Image Super-Resolution(SISR) technique which recovers an HR image from an LR image using 3D Densely Connected Super-Resolution Networks (DCSRN). We compared our network with state-of-art deep learning network in restoring 4x down-graded images and ours are faster and better.
Introduction
Spatial resolution is of paramount importance for intracranial vessel wall (IVW) MR imaging because vessel walls have submillimeter thickness. However, high spatial resolution typically comes at the expense of long scan time, limited spatial coverage and low signal-to-noise ratio (SNR). If we can reconstruct a high-resolution (HR) image from a low-resolution (LR) input, we can potentially achieve larger spatial coverage, higher SNR and better spatial resolution in a shorter scan. In this work, we propose a new Single Image Super-Resolution (SISR) technique which recovers an HR image from an LR image using 3D Densely Connected Super-Resolution Networks (DCSRN).METHODS
We used two different T1-weighted brain MR image sets in our experiment. The first set of IVW images were acquired from 25 healthy volunteers on a 3T MR scanner (Siemens Verio). Imaging parameters included: FOV 170x170x127 mm3, matrix 320x320x240, 0.53 mm isotropic resolution. Images were center cropped to 256x256x192. This dataset was split into 20 training and 5 testing images. The second set of images was a publicly accessible brain T1w structural dataset from the Human Connectome Project (HCP) [1], which has 1113 different subjects. To evaluate SR methods, pairs of LR and HR images are needed. The original images from both sets were treated as ground truth HR images, then LR images were obtained by 1) converting HR images into k-space by 3D FFT; 2) lowering the resolution by truncating the outer part of k-space by a factor of two along both phase encoding directions, which results in 4x down-graded images; 3) Applying the inverse FFT and linearly interpolating images back to the original HR matrix size. This process closely simulates real-world MRI acquisition of LR images.
For the SR experiments, we trained and tested two different deep learning networks on the IVW dataset: a 3D version of the current state-of-art SR networks Fast Super-Resolution Convolution Neural Networks (FSRCNN) [2] and our proposed efficient, advanced 3D DCSRN that was inspired by the Densely Connected Neural Networks (DenseNet) [3]. Network structure details are shown in Fig.1. During training, we fed the networks with LR image patches sized 64x64x64, which were randomly cropped from the whole 3D image data. We used the mean square error (L2 loss) between the output SR and the corresponding HR patches as the cost function by an Adam optimizer [4]. We also trained our DCSRN on the HCP data first and then fine-tuned it on the smaller IVW images to make use of the big image data information. In testing, the patches were averagely merged by a sliding window with step-size half of the patch size. Networks were all implemented in Tensorflow [5].
RESULTS
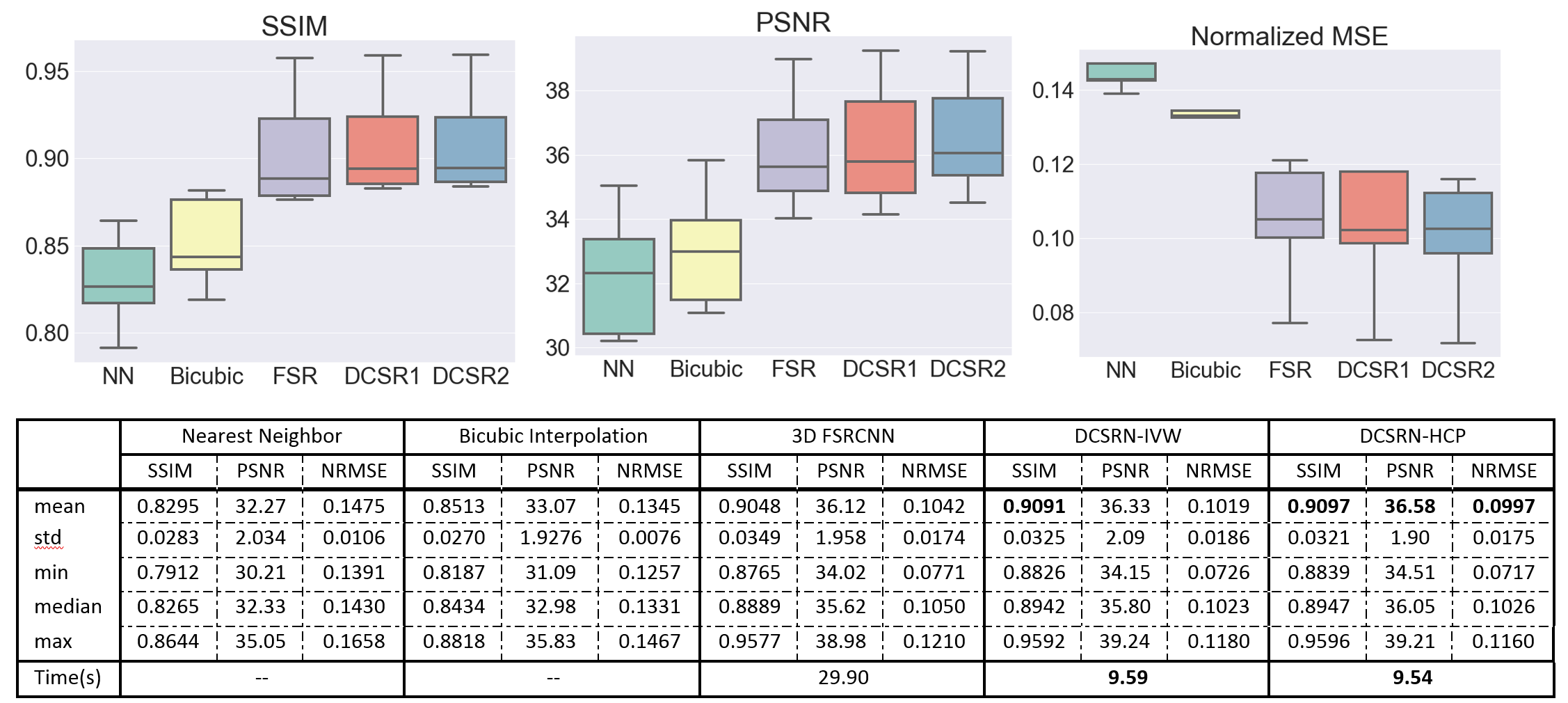
We compared the SR outputs from the original HR image, nearest neighbor (NN) interpolation, and bicubic interpolation, as shown in Figure 2. For quantitative analysis of our results, we compared the SR outputs and interpolated images with the original HR images in three similarity metrics: peak signal-to-noise ratio (PSNR), structural similarity (SSIM) [6], and normalized root mean square error (NRMSE). Analysis on the test set is shown in Figure 3. Both 3D deep learning models outperformed interpolation, recovering more structural details. However, the proposed DCSRN ran over 3x faster and provided superior image quality. Also, by transferring the model from big dataset HCP, the proposed DCSRN only took 2 hours to finish fine-tuned training but was still slightly better than extensively trained on a small dataset.DISCUSSION
In this work, we proposed a novel deep learning neural networks DCSRN for super-resolution to recover IVW HR images from LR ones. Our preliminary study showed that our proposed network outperformed widely used bicubic interpolation and previous deep learning networks. The ability of this deep learning model to generate high-quality images only based on limited information shows a potential to perform MRI scans in low resolution without sacrificing image quality. Future work will focus on further fine-tuning the model on the real k-space data acquired by MRI low-resolution scan.CONCLUSION
We demonstrated that a novel deep learning super-resolution networks could successfully restore high-resolution brain MR image from low-resolution one and it outperformed existing methods in metrics of PSNR, SSIM, and computational speed. The proposed technique may potentially enable high resolution MRI with shortened scan time.Acknowledgements
Data were provided [in part] by the Human Connectome Project, WU-Minn Consortium (Principal Investigators: David Van Essen and Kamil Ugurbil; 1U54MH091657) funded by the 16 NIH Institutes and Centers that support the NIH Blueprint for Neuroscience Research; and by the McDonnell Center for Systems Neuroscience at Washington University.References
[1] David C. Van Essen, Stephen M. Smith, Deanna M. Barch, Timothy E.J. Behrens, Essa Yacoub, Kamil Ugurbil, for the WU-Minn HCP Consortium. (2013). The WU-Minn Human Connectome Project: An overview. NeuroImage 80(2013):62-79.
[2] Dong, Chao, C.C. Loy, and Xiaoou Tang. "Accelerating the super-resolution convolutional neural network." European Conference on Computer Vision. 2016.
[3] Huang, Gao, et al. "Densely connected convolutional networks." arXiv preprint arXiv:1608.06993 (2016).
[4] Kingma, Diederik, and Jimmy Ba. "Adam: A method for stochastic optimization." arXiv preprint arXiv:1412.6980 (2014).
[5] M. Abadi, “TensorFlow: learning functions at scale,” ACM SIGPLAN Notices, vol. 51, no. 9, pp. 1–1, Apr. 2016.
[6] Z. Wang, A. Bovik, H. Sheikh, and E. Simoncelli, “Image Quality Assessment: From Error Visibility to Structural Similarity,” IEEE Transactions on Image Processing, vol. 13, no. 4, pp. 600–612, 2004.
Figures