0570
DeepSPIRiT: Generalized Parallel Imaging using Deep Convolutional Neural Networks1Radiology, Stanford University, Stanford, CA, United States, 2Electrical Engineering, Stanford University, Stanford, CA, United States
Synopsis
A parallel-imaging algorithm is proposed based on deep convolutional neural networks. This approach eliminates the need to collect calibration data and the need to estimate sensitivity maps or k-space interpolation kernels. The proposed network is applied entirely in the k-space domain to exploit known properties. Coil compression is introduced to generalize the method to different hardware configurations. Separate networks are trained for different k-space regions to account for the highly non-uniform energy. The network was trained and tested on both knee and abdomen volumetric Cartesian datasets. Results were comparable to L2-ESPIRiT and L1-ESPIRiT which required calibration data from the ground truth.
Introduction
Receiver-coil arrays introduce localized spatial information that can be exploited for accelerating the scan with parallel-imaging algorithms1–5. Standard techniques rely on calibration data to characterize the localized sensitivity profiles. This data is expensive to obtain in terms of scan time (for a separate calibration scan) or effective subsampling factors (for auto-calibration approaches). Additionally, estimating sensitivity profiles can be time consuming when the channel count is high and/or when a calibration-less approach is applied6–10. We propose a generalized solution to rapidly solve the parallel-imaging problem using deep convolution neural networks (ConvNets).Method
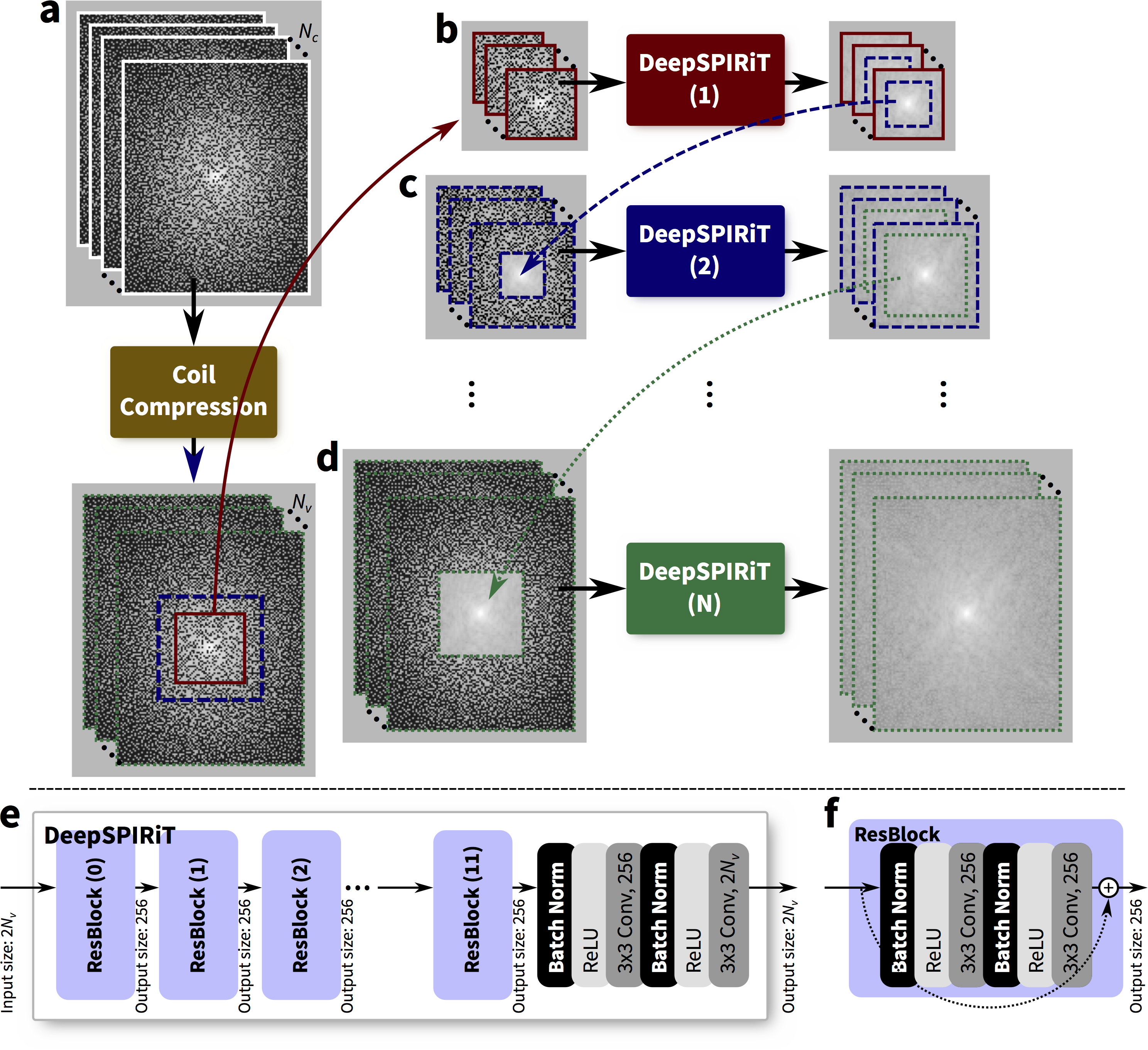
Differing from previous work of image-domain-based ConvNets11,12, we develop the infrastructure to apply ConvNets in the k-space domain to exploit known properties2,5,7,9,10,4 to enable ConvNet-based parallel imaging. Inspired by the generality of SPIRiT4, we refer to this approach as “DeepSPIRiT.”
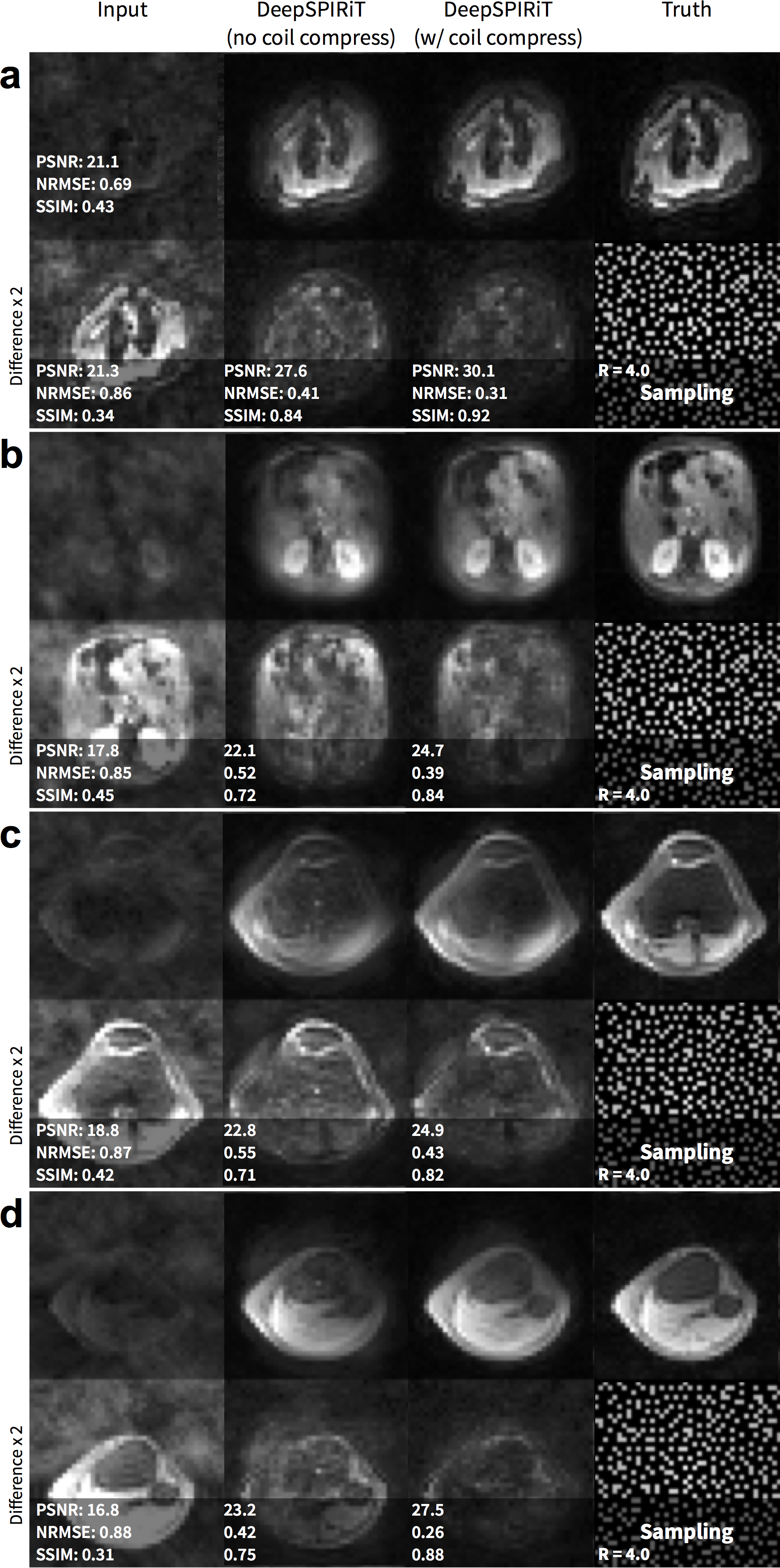
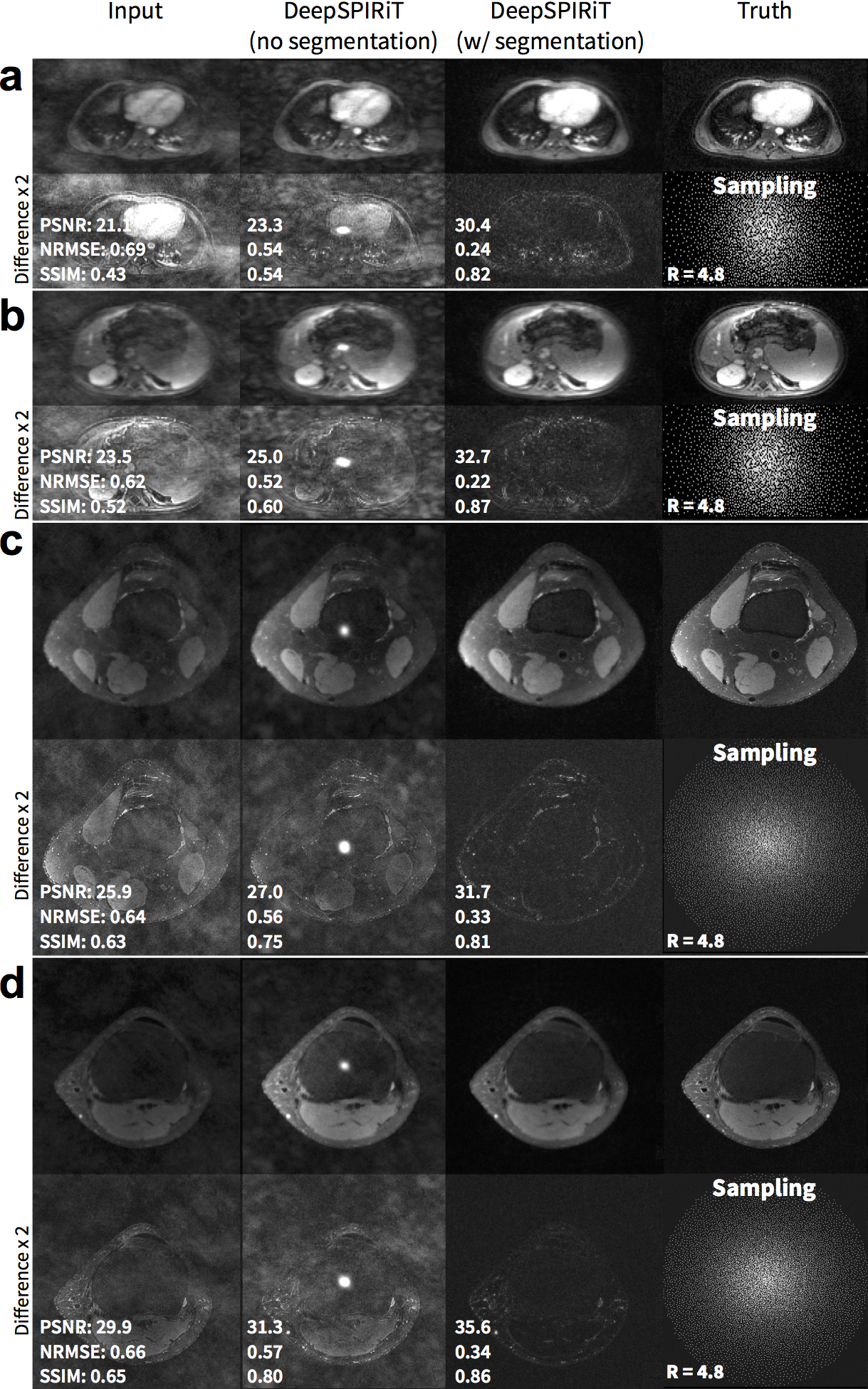
In this DeepSPIRiT framework, we introduce two main features (Figure 1). First, for faster training and for broader applicability to different hardware configurations with varying channel count and coil sizes, we normalize the data using coil compression13,14 (Figure 2). This step places the dominant virtual sensitivity map in the first channel, second dominant in the second channel, and so on. Second, to address the highly non-uniform distribution of k-space signal and the different correlation properties for different k-space regions10, ConvNets are separately trained and applied for each region. The specific setup for segmenting k-space is described in Figure 3. Each ConvNet has the same network architecture with 12 residual blocks15.
The generality of DeepSPIRiT was exploited by combining two vastly different Cartesian datasets collected with IRB approval on GE MR750 3T scanners: fully-sampled proton-density-weighted volumetric knee scans16,17 using an 8-channel knee coil, and gadolinium-contrast-enhanced T1-weighted volumetric abdomen scans using 20-channel body and 32-channel cardiac coils. Raw data were compressed to 8 virtual channels. Abdomen datasets were modestly subsampled $$$(R=1.2–2)$$$ and reconstructed using soft-gated18,19 compressed-sensing-based parallel imaging with L1-ESPIRiT5,20. For these volumetric scans, k-space data were first transformed into the hybrid $$$(x,k_y,k_z)$$$-space and separated into $$$x$$$-slices. Dataset consisted of 14, 2, and 3 knee subjects (4480, 640, and 960 slices) for training, validation, and testing, respectively. Also, 245, 21, 56 abdomen subjects (47040, 4032, and 960 slices) were included for training, validation, and testing, respectively.
For each training example, a pseudo-random uniform poisson-disc sampling mask was randomly chosen. During the training of the center 40x40 block of k-space, data was subsampled by 1.5–2. For the training for the outer portions of k-space, the subsampling factors used were 2–9. Networks were trained in TensorFlow21 using an L2-loss.
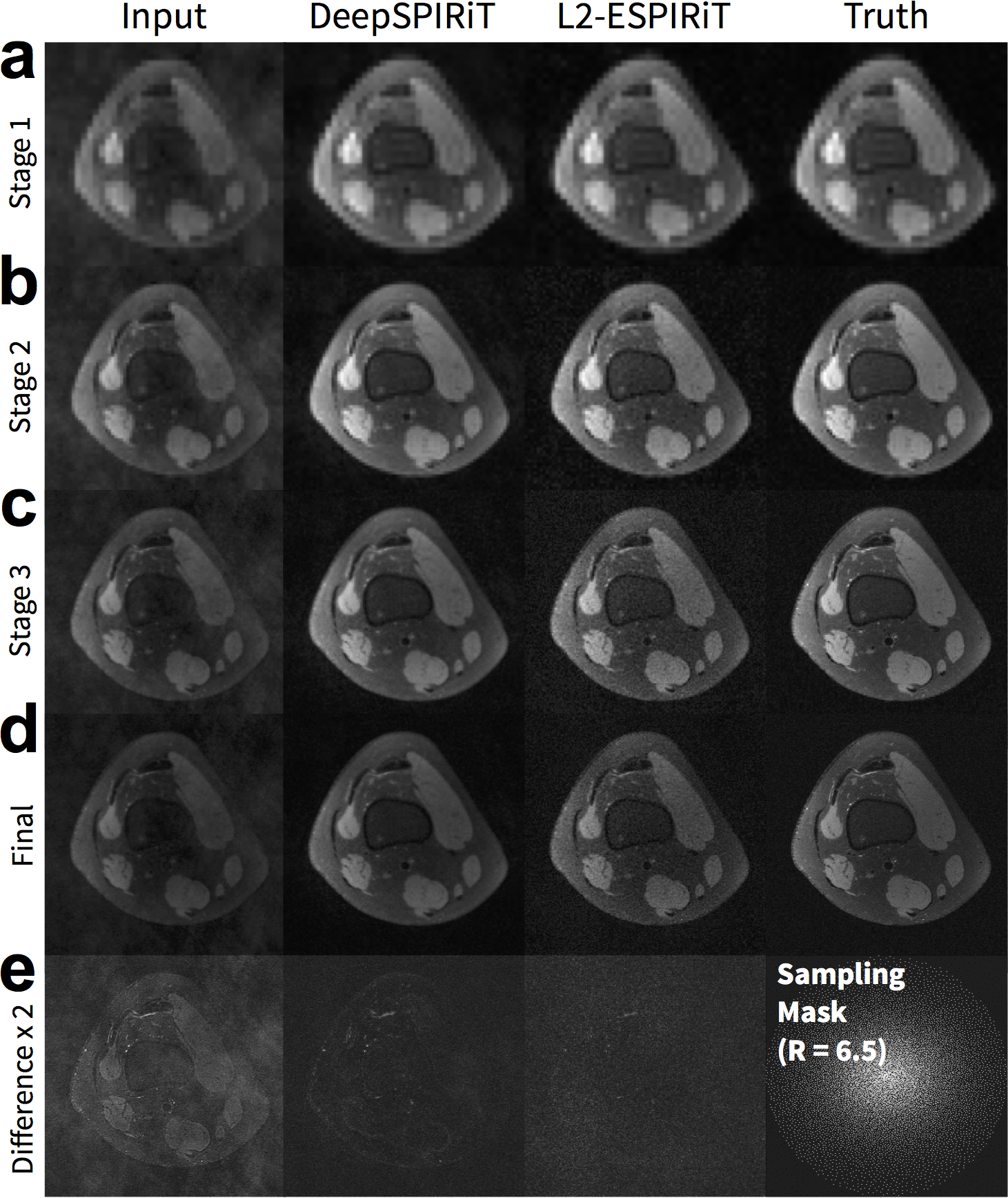
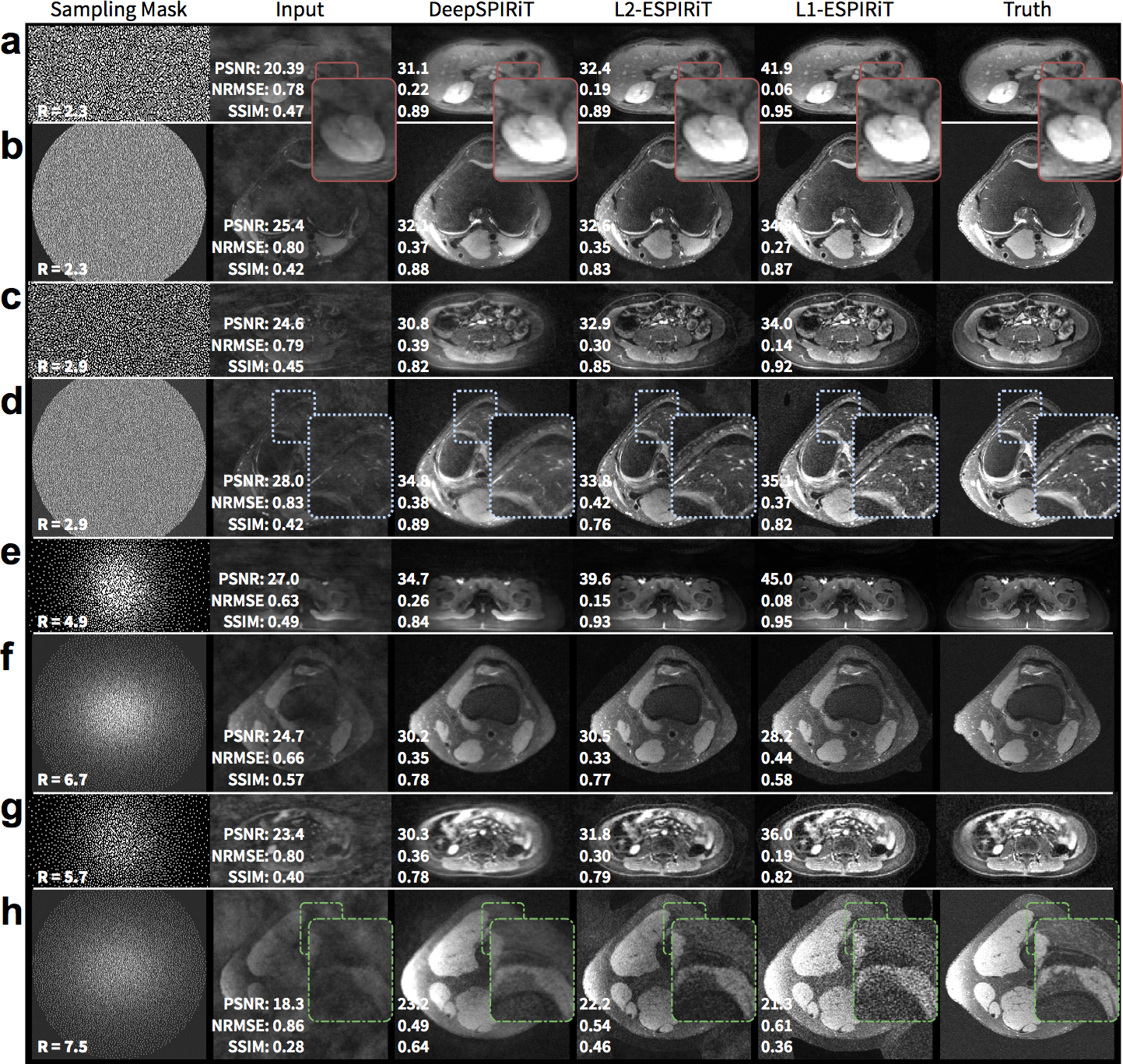
L2-ESPIRiT (with L2-regularization) and L1-ESPIRiT (with spatial wavelet regularization) were performed using BART22 for comparison. We assume that accurate sensitivity maps can always be estimated by computing ESPIRiT maps based on the fully-sampled ground truth. In practice, this information is unavailable and the sensitivity maps must be computed from a separate acquisition or through a calibration-less approach. We evaluated each reconstruction in terms of peak-signal-to-noise-ratio (PSNR), root-mean-squared-error normalized by the norm of the truth (NRMSE), and structural similarity metric23 (SSIM).
Results
For pseudo-random uniformly subsampled datasets, the use of coil compression improves DeepSPIRiT reconstruction results in terms of PSNR, NRMSE, and PSNR (Figure 2). By training models focused on specific k-space regions, the proposed DeepSPIRiT effectively reduced aliasing artifacts (Figure 4). Without k-space segmentation, a bias error was introduced in the estimated data that resulted in high-energy artifacts in the image center.
DeepSPIRiT yielded comparable results with L2-ESPIRiT and L1-ESPIRiT (Figure 5). The proposed approach was unable to fully recover higher spatial frequencies but yielded consistent results. The conventional approaches using L2-ESPIRiT and L1-ESPIRiT reconstructed sharper images; however, these approaches are sensitive to tuning of reconstruction parameters (Figure 5h) and relied on accurate sensitivity maps that were estimated from ground truth.
Discussion
The proposed approach offers several advantages. Since all training is performed offline, DeepSPIRiT is an extremely fast parallel-imaging solution for practical clinical integration. This approach eliminates the need for collecting calibration data and for estimating calibration information. Also, by reconstructing the subsampled data as a multi-channel dataset, data consistency can be explicitly enforced by replacing estimated samples with known measurements. Further, the result of DeepSPIRiT can be used as an initialization for conventional approaches: for example, the output can be used to estimate sensitivity maps or k-space interpolation kernels.
This work is focused on applying ConvNets in the k-space domain. The localized convolutions in k-space naturally generalizes the approach to both uniform and variable-density subsampling. This work can be integrated with image-domain approaches for further improvements in reconstruction accuracy.
Acknowledgements
NIH R01-EB009690, NIH R01-EB019241, and GE Healthcare.References
- Sodickson, D. K. & Manning, W. J. Simultaneous acquisition of spatial harmonics (SMASH): fast imaging with radiofrequency coil arrays. Magn. Reson. Med. 38, 591–603 (1997).
- Griswold, M. A. et al. Generalized autocalibrating partially parallel acquisitions (GRAPPA). Magn. Reson. Med. 47, 1202–1210 (2002).
- Pruessmann, K. P., Weiger, M., Scheidegger, M. B. & Boesiger, P. SENSE: sensitivity encoding for fast MRI. Magn. Reson. Med. 42, 952–62 (1999).
- Lustig, M. & Pauly, J. M. SPIRiT: Iterative self-consistent parallel imaging reconstruction from arbitrary k-space. Magn. Reson. Med. 64, 457–471 (2010).
- Uecker, M. et al. ESPIRiT-an eigenvalue approach to autocalibrating parallel MRI: Where SENSE meets GRAPPA. Magn. Reson. Med. 71, 990–1001 (2014).
- Uecker, M., Hohage, T., Block, K. T. & Frahm, J. Image reconstruction by regularized nonlinear inversion - Joint estimation of coil sensitivities and image content. Magn. Reson. Med. 60, 674–682 (2008).
- Shin, P. J. et al. Calibrationless parallel imaging reconstruction based on structured low-rank matrix completion. Magn. Reson. Med. 72, 959–970 (2014).
- Jin, K. H., Lee, D. & Ye, J. C. A general framework for compressed sensing and parallel MRI using annihilating filter based low-rank Hankel matrix. arXiv:1504.00532 [cs.IT] (2015).
- Haldar, J. P. Low-Rank Modeling of Local k-Space Neighborhoods (LORAKS) for Constrained MRI. IEEE Trans. Med. Imaging 33, 668–681 (2014).
- Li, Y., Edalati, M., Du, X., Wang, H. & Cao, J. J. Self-calibrated correlation imaging with k-space variant correlation functions. Magn. Reson. Med. (2017).
- Hammernik, K. et al. Learning a Variational Network for Reconstruction of Accelerated MRI Data. arXiv: 1704.00447 [cs.CV] (2017).
- Yang, Y., Sun, J., Li, H. & Xu, Z. ADMM-Net: A Deep Learning Approach for Compressive Sensing MRI. Nips 10–18 (2017).
- Huang, F., Vijayakumar, S., Li, Y., Hertel, S. & Duensing, G. R. A software channel compression technique for faster reconstruction with many channels. Magn. Reson. Imaging 26, 133–141 (2008).
- Zhang, T., Pauly, J. M., Vasanawala, S. S. & Lustig, M. Coil compression for accelerated imaging with Cartesian sampling. Magn. Reson. Med. 69, 571–582 (2013).
- He, K., Zhang, X., Ren, S. & Sun, J. Identity Mappings in Deep Residual Networks. arXiv:1603.05027 [cs.CV] (2016).
- Epperson, K. et al. Creation of Fully Sampled MR Data Repository for Compressed Sensing of the Knee. in SMRT 22nd Annual Meeting (2013). doi:10.1.1.402.206
- MRI Data. Available at: http://mridata.org/. (Accessed: 14th July 2017)
- Johnson, K. M., Block, W. F., Reeder, S. B. & Samsonov, A. Improved least squares MR image reconstruction using estimates of k-space data consistency. Magn. Reson. Med. 67, 1600–8 (2012).
- Cheng, J. Y. et al. Free-breathing pediatric MRI with nonrigid motion correction and acceleration. J. Magn. Reson. Imaging 42, 407–420 (2015).
- Lustig, M., Donoho, D. & Pauly, J. M. Sparse MRI: The application of compressed sensing for rapid MR imaging. Magn. Reson. Med. 58, 1182–1195 (2007).
- Abadi, M. et al. TensorFlow: Large-Scale Machine Learning on Heterogeneous Distributed Systems. arXiv:1603.04467 [cs.DC] (2016).
- Uecker, M. et al. BART: version 0.3.01. (2016). doi:10.5281/zenodo.50726
- Wang, Z., Bovik, A. C., Sheikh, H. R. & Simoncelli, E. P. Image quality assessment: from error visibility to structural similarity. IEEE Trans Image Process. 13, 600–612 (2004).
Figures