5663
Improving the PI+CS Reconstruction for Highly Undersampled Multi-contrast MRI using Local Deep Network1Electrical Engineering, Stanford University, Stanford, CA, United States, 2Radiology, Stanford University, Stanford, CA, United States
Synopsis
A typical clinical MR protocol includes multiple scans with different contrasts for complementary diagnostic information. Various methods have been proposed to specifically accelerate multi-contrast scans by using more complicated sparsity regularization in PI+CS.
Here we proposed a Non-iterative Deep-Learning approach to further improve existing methods for highly undersampled multi-contrast MRI reconstruction.
This method uses a Sequential+Joint+Local scheme, which takes fast PI+CS reconstruction as the initial input, uses a Deep-Network on local patches, and efficiently generates a better reconstruction for different contrasts with reduced noise and artifacts.
Experiments demonstrate the proposed method has superior performance compared with existing PI+CS methods.
Introduction
A typical clinical MR protocol includes multiple scans with different contrasts. These MR images share similar structures but still consist of fundamentally unique contrasts for complementary diagnostic information. To reduce the long scanning time associated with acquiring multiple contrasts, the combination of Parallel-Imaging (PI) and Compressed-Sensing (CS) methods [1-4] has been proposed to reconstruct undersampled MR data. Various methods were proposed to specifically improve multi-contrast scans by using more complicated sparsity regularization [5-8].
Here we propose a Non-iterative Deep-Learning (DL) approach to further improve existing PI+CS methods for highly undersampled multi-contrast MRI reconstruction.
This method takes fast PI+CS reconstruction as the initial input, uses a Deep-Network on local patches, and efficiently generates a better reconstruction for different contrasts with reduced noise and artifacts.
Theory
PI+CS reconstruction for undersampled multi-contrast MRI scans is usually formulated as a constrained optimization problem, including a data consistency term for the acquisition model $$$F$$$ with coil sensitivity information $$$S$$$, a sparsity penalty based on sparsity transforms (TV, Wavelet, Low-rank etc.) and optionally special sparsity penalty across different contrasts (TGV, Low-rank, Structured Group Sparsity, etc.).
$$ \arg \min_{x} { \left \| FSx-y \right \|_2^2+\lambda_{Single} \sum_{c=1}^M{\left \| \Psi x_c\right \|_1} + \lambda_{Multi} \left \| \Phi x \right \|_1} $$
Here we propose to improve the reconstruction with a Sequential+Joint+Local approach by exploiting 1) structural similarity of multi-contrast signals from the same anatomy, 2) the incoherency of residual artifacts from random undersampling, 3) the randomness of noise.
The local Deep-Network works because of the local sparsity and redundancy in local multi-contrast patches, which has been proved by other research works (Locally Low-Rank (LLR) [9-10] and Super-Resolution [11]).
Method
The proposed method has a Sequential+Joint+Local scheme.
1) Initial PI-CS Reconstruction for each scan independently and sequentially
Fast acquisition with random undersampling is used for each scan of different contrast. An initial PI+CS reconstruction is conducted for each scan independently (using BART toolbox [12]). This sequential and independent reconstruction is consistent with common clinical approaches.
2) Jointly improve multi-contrast reconstruction using deep network on local multi-contrast patches
From the initial reconstruction of all the scans, a local deep network is trained and used to take the multi-contrast patches as input and generate the improved version (artifact reduction, noise reduction) of multi-contrast patches, which are then combined to form the multi-contrast images. This leads to better reconstruction performance.
3) Deep-Network Structure
Here we use a Convolutional Neural Network (CNN) [13] for local patch improvement. The CNN model uses bypass connections proposed in ResNet network [14] structure. The network structure is similar to the Residual-Encoder-Decoder CNN which been proposed for image restoration studies [15]. Using local patches augmented the amount of samples in training which prevents overfitting.
To train the deep network, we use initial recon results as input, use reference fully-sampled images as reference output. From each multi-contrast images at a corresponding 2D slice, thousands of multi-contrast patches (16x16) are generated to train a model based on corresponding patches in fully-sampled images.
To use a trained network, for each position we generate a stack of multi-contrast patches centered at this position from initial reconstructed images. Then we forward-pass these multi-contrast patches to reduce the artifact and noise. The final reconstructed multi-contrast images are synthesized from improved local patches.
Experiments and Results
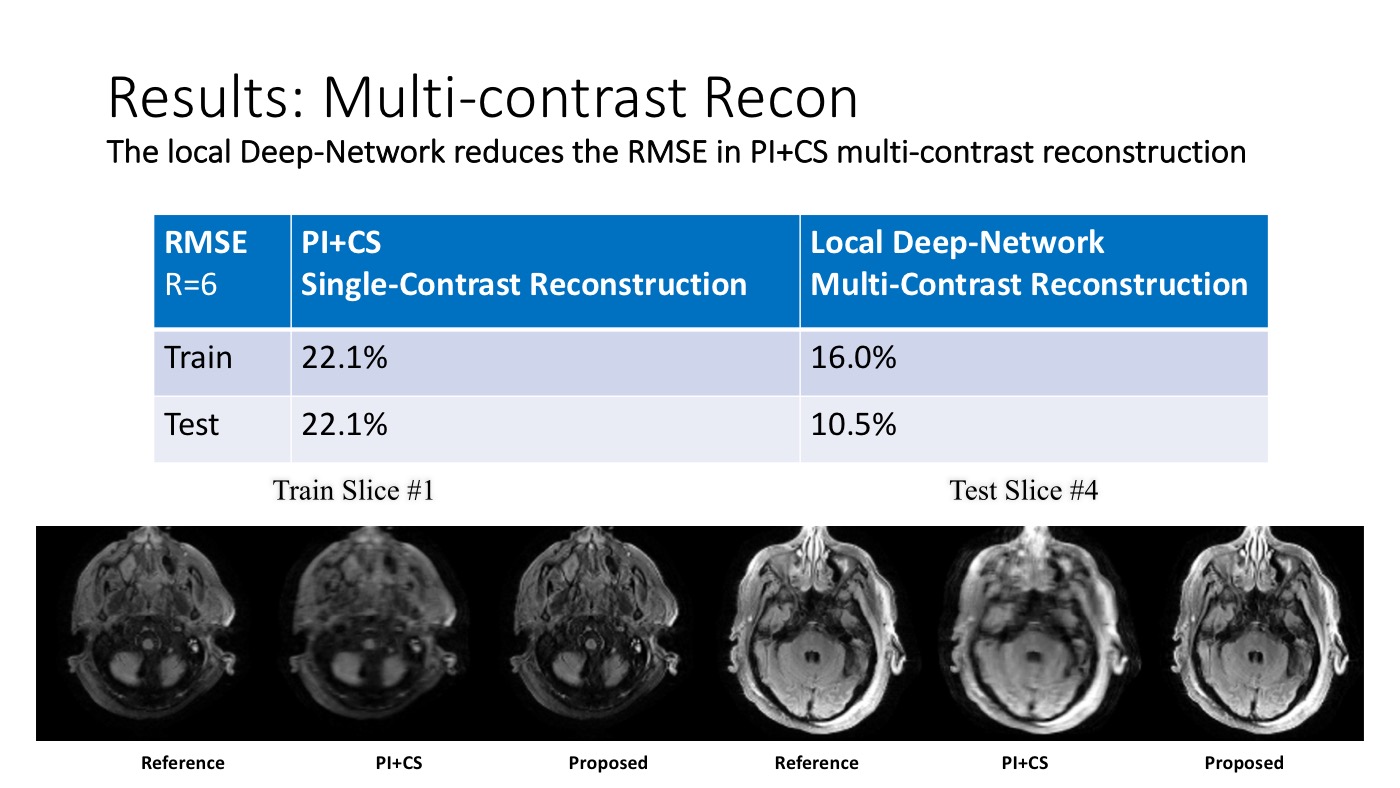
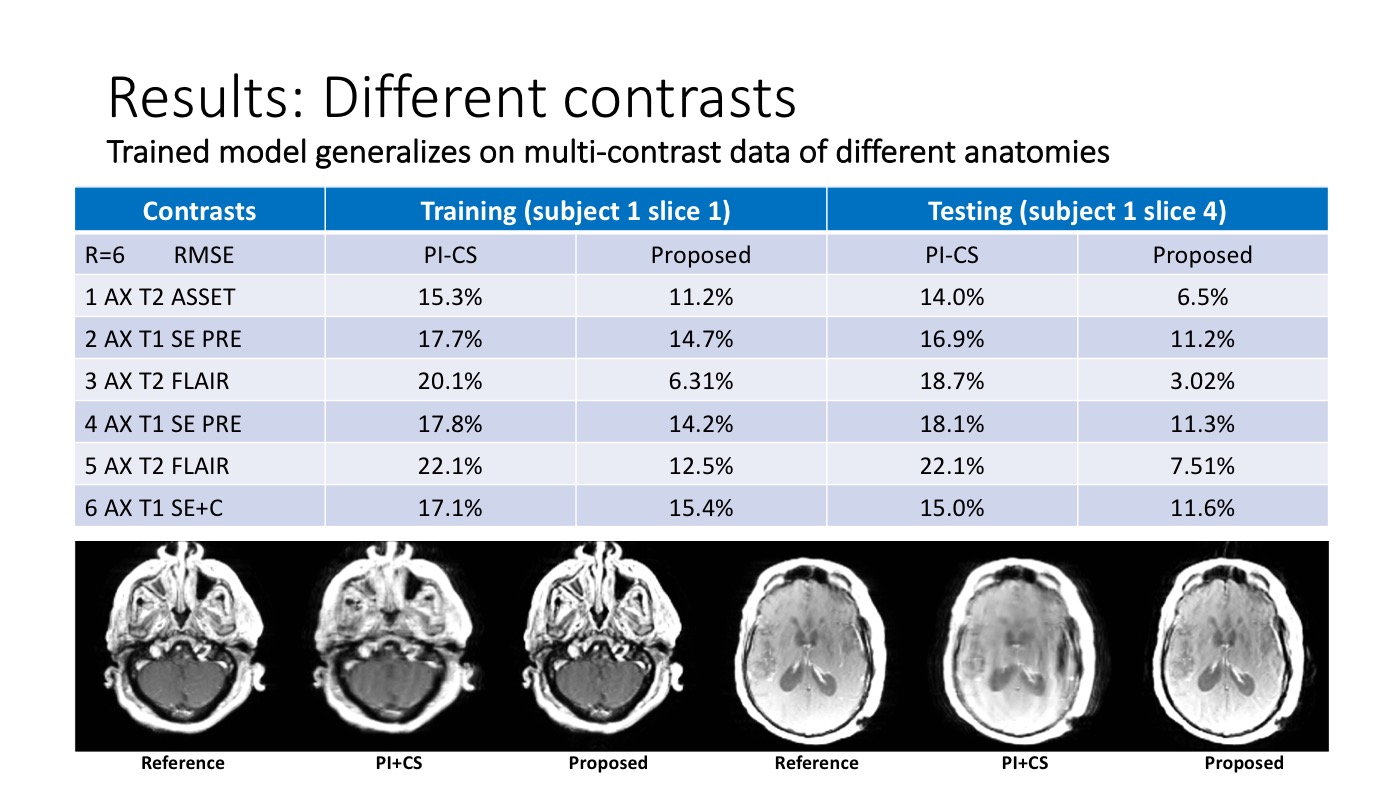
Training and testing on different datasets, we demonstrated the reconstruction using existing PI+CS reconstruction method (from BART toolbox) and the proposed method.
We used multi-contrast brain scans (detailed protocol listed in figure) for demonstration. The data was undersampled retrospectively with randomized 1D undersampling patterns. It reduced round 50% of residual artifacts and noises (estimated in RMSE) compared with existing PI+CS methods.
Discussion
Similar to Local-Sparsity [9-10] and Total-Generalized-Variance [8] which exploit the redundancy and sparsity in local regions across different contrasts, we proposed a Deep Learning method to achieve better reconstruction.
The model uses bypass connections [14] and a Residual-Encoder-Decoder-CNN structure [15] which have been shown useful for image recognition application, Super-Resolution and medical imaging processing. This residual learning scheme try to compensate residual artifacts/noises between initial reconstruction and ground-truth reconstruction, which keeps original signal intensity and unique features in different contrasts.
The training of the model takes hours but application of the network trained is non-iterative and real-time, which makes it an efficient and effective addition to all reconstruction products.
This method can also be used as a projection step for other to further improve other iterative reconstruction methods.
Acknowledgements
We acknowledge GE Healthcare for supporting the work.References
- Pruessmann, Klaas P., et al. "SENSE: sensitivity encoding for fast MRI." Magnetic resonance in medicine 42.5 (1999): 952-962.
- Griswold, Mark A., et al. "Generalized autocalibrating partially parallel acquisitions (GRAPPA)." Magnetic resonance in medicine 47.6 (2002): 1202-1210.
- Lustig, Michael, David Donoho, and John M. Pauly. "Sparse MRI: The application of compressed sensing for rapid MR imaging." Magnetic resonance in medicine 58.6 (2007): 1182-1195.
- Uecker, Martin, et al. "ESPIRiT—an eigenvalue approach to autocalibrating parallel MRI: where SENSE meets GRAPPA." Magnetic resonance in medicine 71.3 (2014): 990-1001.
- Bilgic, Berkin, Vivek K. Goyal, and Elfar Adalsteinsson. "Multi-contrast reconstruction with Bayesian compressed sensing." Magnetic Resonance in Medicine 66.6 (2011): 1601-1615.
- Huang, Feng, and Enhao Gong. "Mri using spatially adaptive regularization for image reconstruction." U.S. Patent Application No. 14/916,200.
- Gong, Enhao, et al. "PROMISE: Parallel-imaging and compressed-sensing reconstruction of multicontrast imaging using SharablE information." Magnetic resonance in medicine 73.2 (2015): 523-535.
- Knoll, Florian, et al. "Joint MR-PET reconstruction using a multi-channel image regularizer." IEEE Transactions on Medical Imaging 36.1 (2017): 1-16.
- Lee, Joonseok, et al. "Local Low-Rank Matrix Approximation." ICML (2) 28 (2013): 82-90.
- Zhang, Tao, John M. Pauly, and Ives R. Levesque. "Accelerating parameter mapping with a locally low rank constraint." Magnetic resonance in medicine 73.2 (2015): 655-661.
- Dong, Chao, et al. "Image super-resolution using deep convolutional networks." IEEE transactions on pattern analysis and machine intelligence 38.2 (2016): 295-307.
- Uecker, Martin, et al. "Berkeley advanced reconstruction toolbox." Proceedings of the 23rd Annual Meeting ISMRM, Toronto. 2015.
- Krizhevsky, Alex, Ilya Sutskever, and Geoffrey E. Hinton. "Imagenet classification with deep convolutional neural networks." Advances in neural information processing systems. 2012.
- He, Kaiming, et al. "Deep residual learning for image recognition." Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2016.
- Mao, Xiaojiao, Chunhua Shen, and Yu-Bin Yang. "Image restoration using very deep convolutional encoder-decoder networks with symmetric skip connections." Advances in Neural Information Processing Systems. 2016.
Figures