5662
Deep Convolutional Auto-Encoder and 3D Deformable Approach for Tissue Segmentation in Magnetic Resonance Imaging1Department of Radiology, University of Wisconsin-Madison, Madison, WI, United States, 2Department of Biomedical Engineering, University of Minnesota, Minneapolis, MN, United States
Synopsis
A fully-automated segmentation pipeline was built by combining a deep Convolutional Auto-Encoder (CAE) network and 3D simplex deformable modeling. The CAE was applied as the core of the segmentation method to perform high resolution pixel-wise multi-class tissue classification. The 3D simplex deformable modeling refined output from CAE to preserve the overall shape and maintain a desirable smooth surface for structure. The fully-automated segmentation method was tested using a publicly available knee joint image dataset to compare with currently used state-of-the-art segmentation methods. The fully-automated method was also evaluated on morphological MR images with different tissue contrasts and image training datasets.
Introduction
Tremendous progress has been made for image processing and analysis due to the flourishing deep Convolutional Neural Networks (CNN) in recent years (1-3). Adaptation of CNN deep learning methods has been shown to have great impact on multiple medical imaging fields with performance superior than most of the-state-of-art techniques (4). In this study, we propose to perform fully-automated versatile tissue segmentation by combining a Convolutional Auto-Encoder (CAE) CNN and 3D simplex deformable modeling (5). The purpose of this study is to describe and validate this application of CNN deep learning for tissue segmentation from MR images and to build a framework to pipeline this fully-automated process. We hypothesize that this new method will improve the accuracy and efficiency of segmentation, and has potentials to be extended to wide variety of tissue segmentation applications in MRI.Methods
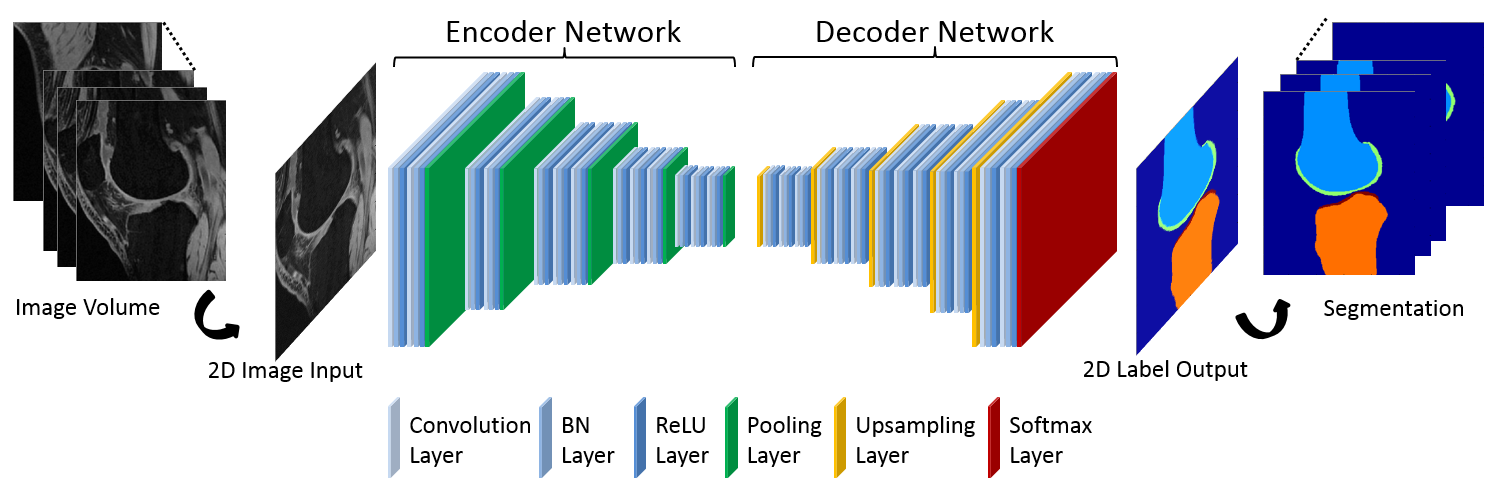
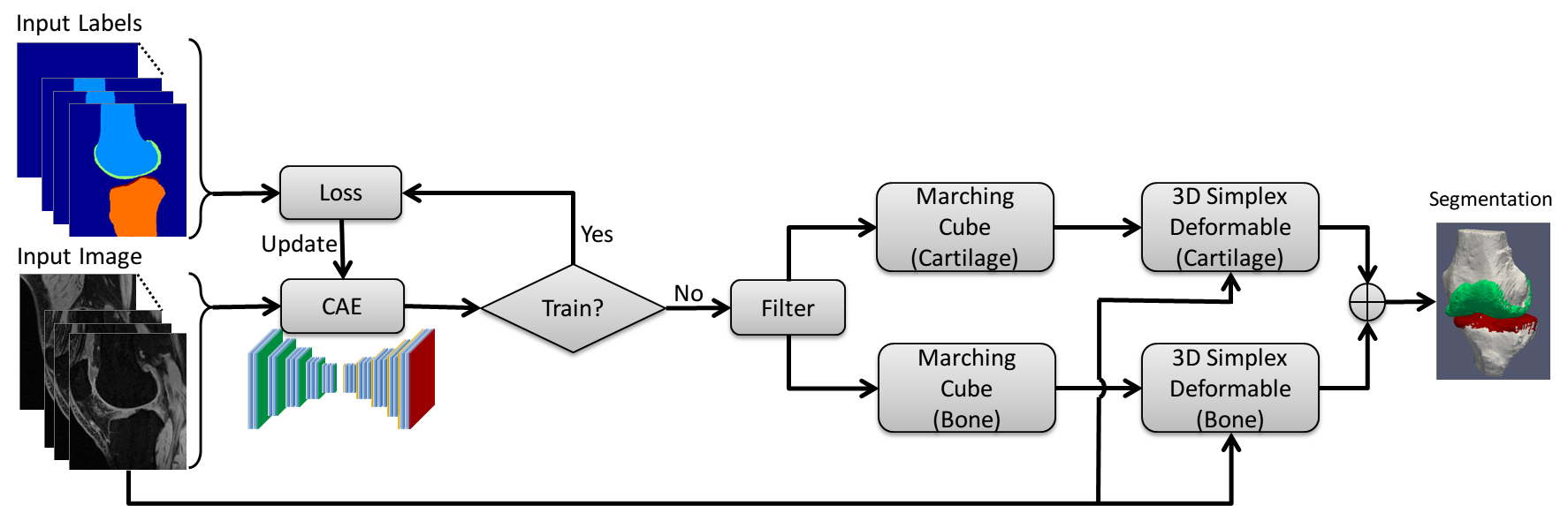
CAE was selected as a core segmentation engine for constructing the deep learning network (6). An illustration of the CAE network is shown in Figure 1. This network is composed of an encoder network and a decoder network. The encoder network is essentially the same as the 13 convolutional layers of the VGG16 network (7) designed for object recognition. The encoder layer consists of standard 2D convolutional filter, batch normalization (BN) filter, and rectified-linear non-linear (ReLU) filter followed by a max-pooling filter. The decoder network is a reverse process of the encoder and consists of up-sampling layers to recover high resolution pixel-wise labels. The final layer of decoder network is a multi-class soft-max classifier which produces class probabilities for each individual pixel. The class labels of whole 3D image volume is used as the initial tissue classification and the tissue boundary is extracted, and the segmentation is then refined through 3D simplex deformable modeling to preserve the smooth boundary and maintain overall object shape. The full segmentation algorithm is summarized in Figure 2. The segmentation method was evaluated on both a publicly available SKI10 (www.ski10.org) knee image dataset (SPGR images, 60 subjects for training, 40 for testing) and clinical knee image datasets (3D-FSE images, 40 subjects for training, 20 for testing) for segmenting bone and cartilage. To evaluate the accuracy of bone segmentation, the average symmetric surface distance (AvgD) and root-mean-square symmetric surface distance (RMSD) were used. To evaluate the accuracy of cartilage segmentation, the volumetric overlap error (VOE) and volumetric difference (VD) were used.Results
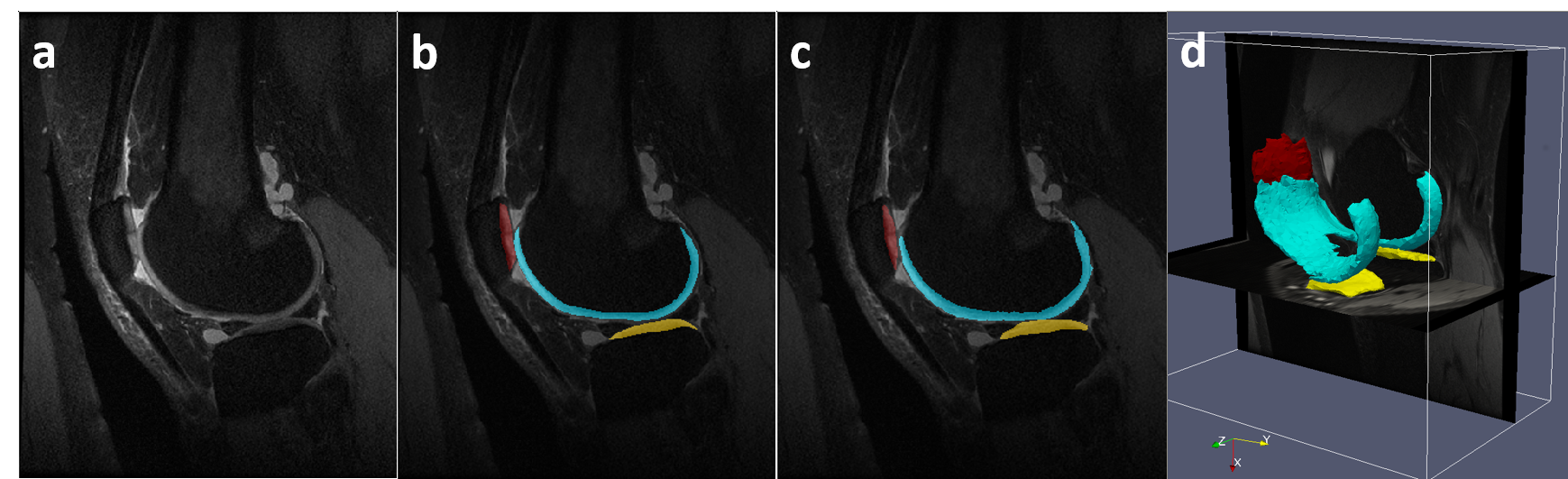
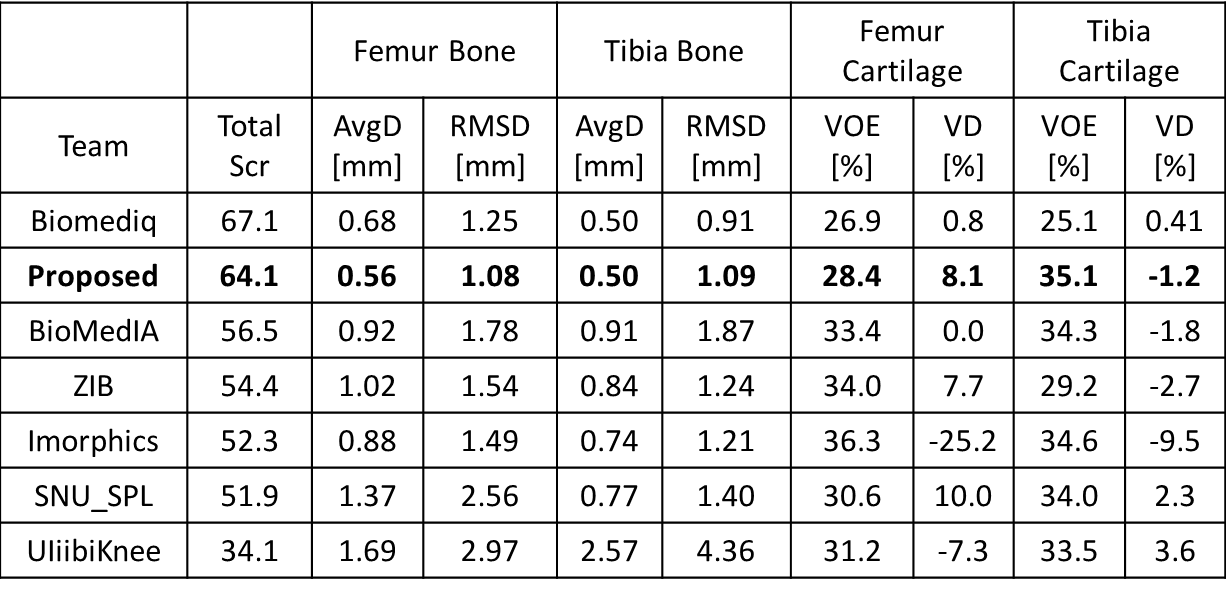
Figure 3 shows an example of a patient in the SKI10 image dataset with severe cartilage loss with T1 weighted SPGR sequence. The final segmentation provides excellent agreement with the overall shape of the ground truth as well as maintaining desirable smooth cartilage and bone surfaces indicated by arrows in Figure 3g. Figure 4 shows an example of cartilage segmentation in a clinical patient imaged with a 3D-FSE sequence which has different tissue contrast than SPGR sequence used in the SKI10 challenge. Figure 4c shows the fully-automated segmented femoral, tibial, and patellar cartilage on one sagittal image slice which demonstrates excellent agreement with the manually segmented cartilage shown in Figure 4b. Table 1 shows average numbers of quantitative accuracy metrics for the 40 test patients in the SKI10 image dataset. Our segmentation method ranked the second top overall performance among state-of-the-art segmentation methods with a score of 64.1 based on SKI10 scoring system.Discussion
Our study has developed and validated a new fully-automated tissue segmentation method which integrates deep CNN and 3D simplex deformable approaches to improve the accuracy and efficiency of cartilage and bone segmentation within the knee joint. Our segmentation method was shown to provide rapid and accurate segmentation for routine use in clinical practice and MR image research studies. Additional efforts are currently underway to improve the segmentation algorithm by optimizing network structure and to reduce training time by applying transfer learning and fine-tuning. These techniques may further improve the efficiency of the segmentation method while maintaining high accuracy and repeatability and low computational costs. More studies are still undergoing to explore the usefulness of this fully-automated segmentation framework in multiple tissue segmentation applications.Acknowledgements
We acknowledge support from NIH R01-AR068373-01.References
1. Lecun Y, Bottou L, Bengio Y, Haffner P. Gradient-based learning applied to document recognition. Proceedings of the IEEE 1998;86(11):2278-2324.
2. Krizhevsky A, Sutskever I, Hinton GE. ImageNet Classification with Deep Convolutional Neural Networks. Advances in Neural Information Processing Systems 25 2012:1097-1105.
3. LeCun Y, Bengio Y, Hinton G. Deep learning. Nature 2015;521(7553):436-444.
4. Greenspan HG, Bram van, Summers RM. Guest Editorial Deep Learning in Medical Imaging: Overview and Future Promise of an Exciting New Technique. IEEE Transactions on Medical Imaging May 2016;35(5):1153 - 1159.
5. Delingette H. General Object Reconstruction Based on Simplex Meshes. International Journal of Computer Vision 1999;32(2):111-146.
6. Badrinarayanan V, Kendall A, Cipolla R. SegNet: A Deep Convolutional Encoder-Decoder Architecture for Image Segmentation. arXiv preprint arXiv:1511.005612015.
7. Simonyan K, Zisserman A. Very Deep Convolutional Networks for Large-Scale Image Recognition. ArXiv e-prints. Volume 14092014.
Figures