5369
Encoding and decoding semantic information of natural movies from 7T human brain activity provided by the Human Connectome Project1UC Berkeley, Berkeley, CA, United States, 2Center for Imaging of Neurodegenerative Diseases, Veteran Affairs Health Care System, San Francisco, CA, United States
Synopsis
We demonstrate the utility of the new 7T fMRI movie dataset made publicly available by the WashU-UMinn Human Connectome Project (HCP, www.humanconnectome.org) by reconstructing the movies participants watched, based on their fMRI brain activity and two general models of the human brain: a structural model and a semantic model. Although we were only marginally successful when using the structural model (most likely because participants were allowed to freely view the movie without a fixation task), we were able to successfully decode the semantic content of the held out movie data, with surprisingly high accuracy (r~0.8, and p<10^-10).
PURPOSE:
To demonstrate the utility of the new 7T fMRI movie dataset made publicly available by the WashU-UMinn Human Connectome Project (HCP, www.humanconnectome.org). Towards this goal, we reconstructed the movies participants watched, based on their fMRI brain activity and two general models of the human brain: a structural model [1-2] and a semantic model [3-5]. The structural model describes the stimulus features in terms of low level visual properties such as size, spatial frequency, orientation and location. The semantic model describes the features in terms of the objects in a stimulus, for example a “person”, a “plant”, or a “vehicle”. The effect of FSL's FIX denoising algorithm (http://fsl.fmrib.ox.ac.uk/fsl/fslwiki/FIX) on this dataset, as made available by the HCP, is also investigated.METHODS:
In this preliminary study, the first ten 7T subjects (of ~100) were analyzed. Subjects were scanned using a Siemens 7T MRI scanner (1.6 mm iso, TR=1000 ms, IPAT2 MB5, 32 ch receive array) while viewing four natural movies (approximately 15 min each). The movies consisted of short clips from Hollywood and Creative Commons movies (http://creativecommons.org). The last 84 seconds of each movie were identical and were used for model validation as well as for evaluation of data quality (via F-test [6] with 12 groups each averaged across 7 sec bins). The remaining ~3000 seconds of unique movie data were used to train both structural and semantic models. Principle Component Analysis (PCA) was run on the structural and semantic feature time courses to reduce the dimensionality and collinearity between individual features. Unlike prior work where PCA was performed on an individual subject basis on fitted voxel beta weights (determined via regularized regression), our approach benefits from improved statistical power since the number of regressors (many of them collinear) is reduced by a factor of ~10, prior to regression. Furthermore, this approach facilitates direct comparison across subjects as well as direct decoding of the Principle Components (PCs) of the feature space since a single, stimulus derived PC space is used. Data were preprocessed via the HCP minimal preprocessing pipeline [7]. To determine if FIX denoising impacts BOLD signals of interest, analysis was performed on the two versions of the available datasets (with and without FIX denoising).
RESULTS:
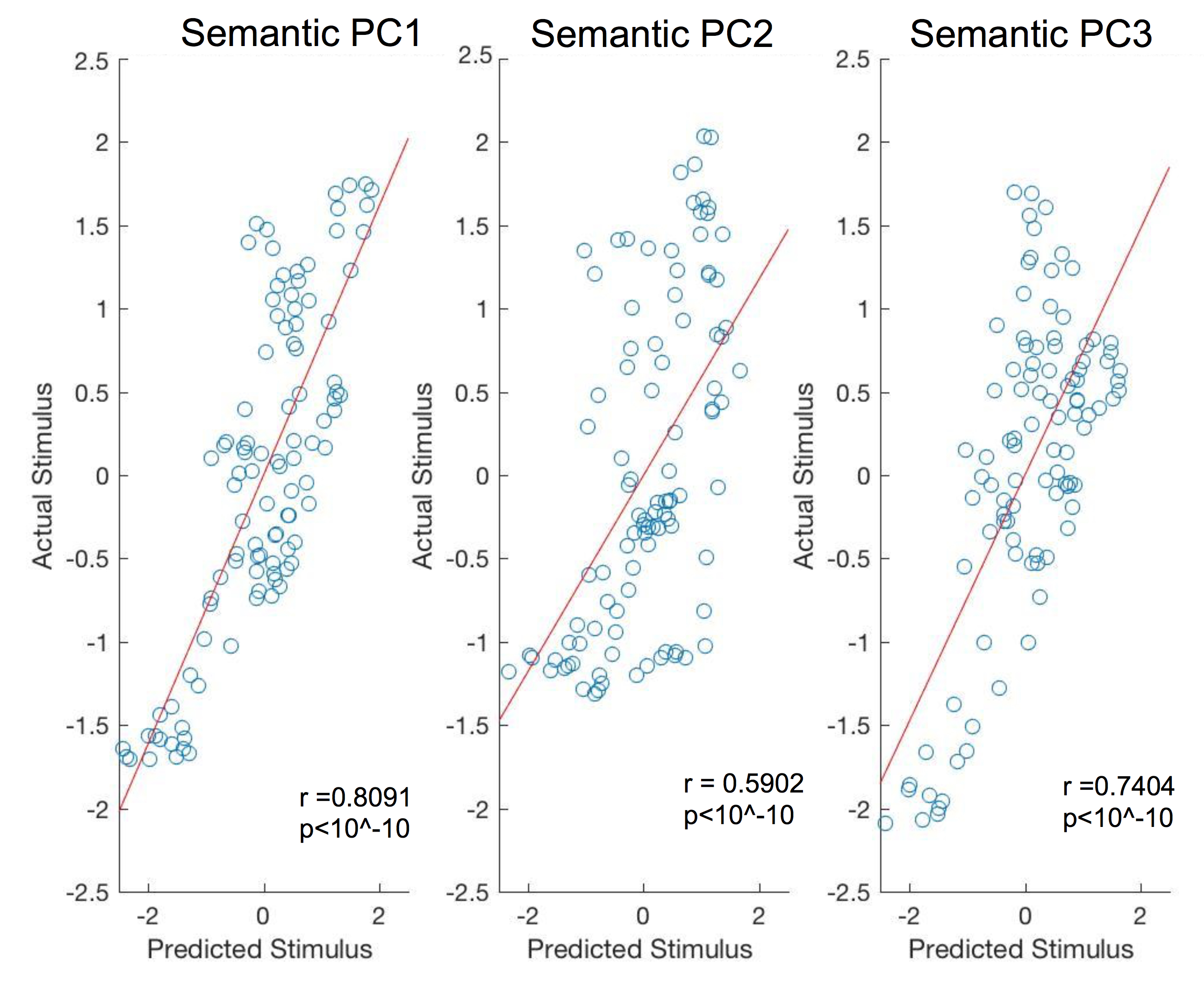
Figure 1 shows the F-values from one representative subject plotted on the flattened cortical sheet of the brain. As expected, visual areas have the highest values. Figure 2 shows that FIX denoising significantly improves both the size and cortical extent of F-values (p < 0.05). Figure 3 shows the preference of semantic content across the brain in PC space. PC 1 (red channel) has preference for semantic content such as ‘male’, ‘living things’, and ‘person’. PC 2 (green channel) favors content such as ‘matter’, ‘tree’, and ‘plants’. PC 3 (blue channel) favors content such as ‘physical entity’, ‘body part’, and ‘things’. Early visual cortex is not semantically selective and thus tends towards white. For reference, Figure 4 shows the five most positive and negative weighted words defining the first three PCs. Figure 5 shows the decoding accuracy of semantic movie content (predicted stimulus versus actual stimulus for one representative subject). Each circle represents one second of the 84 second validation movie. Using the semantic model, we were able accurately predict the first three semantic PCs (p < 10^-10). The ability to decode higher PCs varied from subject to subject (not shown).
CONCLUSION:
Although we were only marginally successful when using the structural model (most likely because participants were allowed to freely view the movie without a fixation task), we were able to accurately decoded, on a second by second basis, the semantic content of held out movie data that was not used in fitting our models. Future work will attempt to reconstruct/decode more detailed renditions of the stimulus based on the decoded PC components as well as in conjunction with the structural model - potentially with eye tracking data to account for subject eye movements. In addition, we plan to apply the fitted models that were estimated from natural movie fMRI data to resting state data of the same subjects in an attempt to decode mental imagery or dreams.Acknowledgements
Data were provided by the Human Connectome Project, WU-Minn Consortium(Principal Investigators: David Van Essen and Kamil Ugurbil; 1U54MH091657) funded by the 16 NIH Institutes and Centers that support the NIH Blueprint for Neuroscience Research; and by the McDonnell Center for Systems Neuroscience at Washington University.
We would also like to thank NIH Bridge to Baccalaureate Program, grant project R25GM095401.
References
[1] Kay KN, Naselaris T, Prenger RJ, Gallant JL. Identifying natural images from human brain activity. Nature, 452:352-355 (2008).
[2] Nishimoto S, Vu AT, Naselaris T, Benjamini Y, Yu B, Gallant, JL. Reconstructing visual experiences from brain activity evoked by natural movies. Current Biology, 21:1641-1646 (2011).
[3] Huth AG, Nishimoto S, Vu AT & Gallant JL. A Continuous semantic space describes the representation of thousands of objects and action categories across the human brain. Neuron, 76:1210-1224 (2012).
[4] Vu AT, Phillips JS, Kay K, Phillips ME, Johnson MR, Shinkareva SV, Tubridy S, Millin R, Grossman M, Gureckis T, Bhattacharyya R, Yacoub E. Using Precise word timing information improves decoding accuracy in a multiband-accelerated multimodal reading experiment. Cogn Neuropsychol, 3-4:265-275 (2016).
[5] Huth AH, Lee T, Nishimoto S, Bilenko NY, Vu AT, Gallant JL. Decoding the semantic content of natural movies from human brain activity. Front Syst Neurosci. 10:81 (2016).
[6] Freedman, D. Statistical models: Theory and practice. Cambridge: Cambridge University Press (2005).
[7]
Glasser MF, Sotiropoulos SN, Wilson JA, Coalson TS, Fischl B, Andersson JL, Xu J,
Jbabdi S, Webster M, Polimeni JR, Van Essen DC, Jenkinson M, - for the WU-
Minn HCP Consortium. The minimal preprocessing pipelines for the Human
Connectome Project. Neuroimage 80:105–124 (2013).
Figures
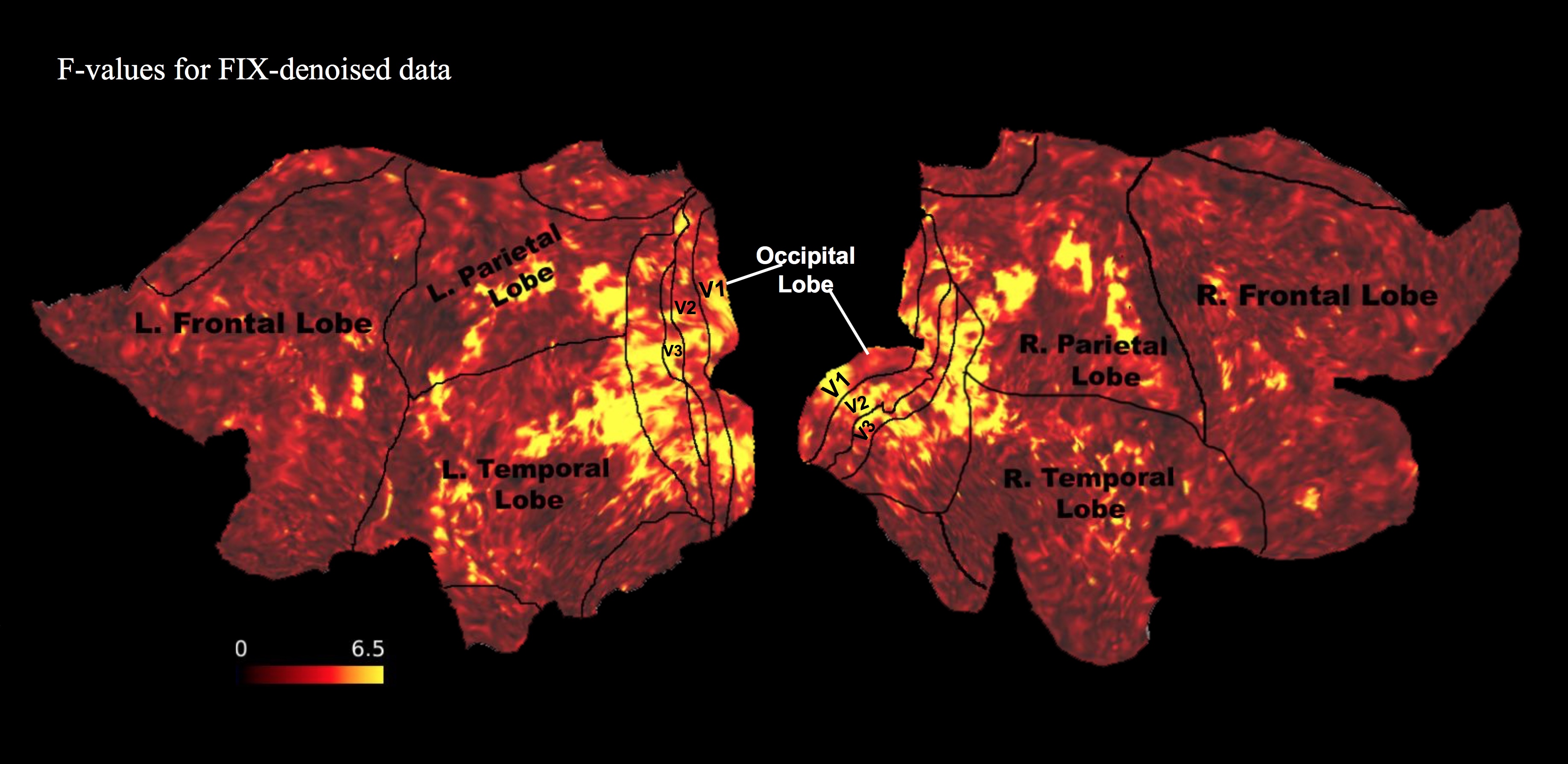
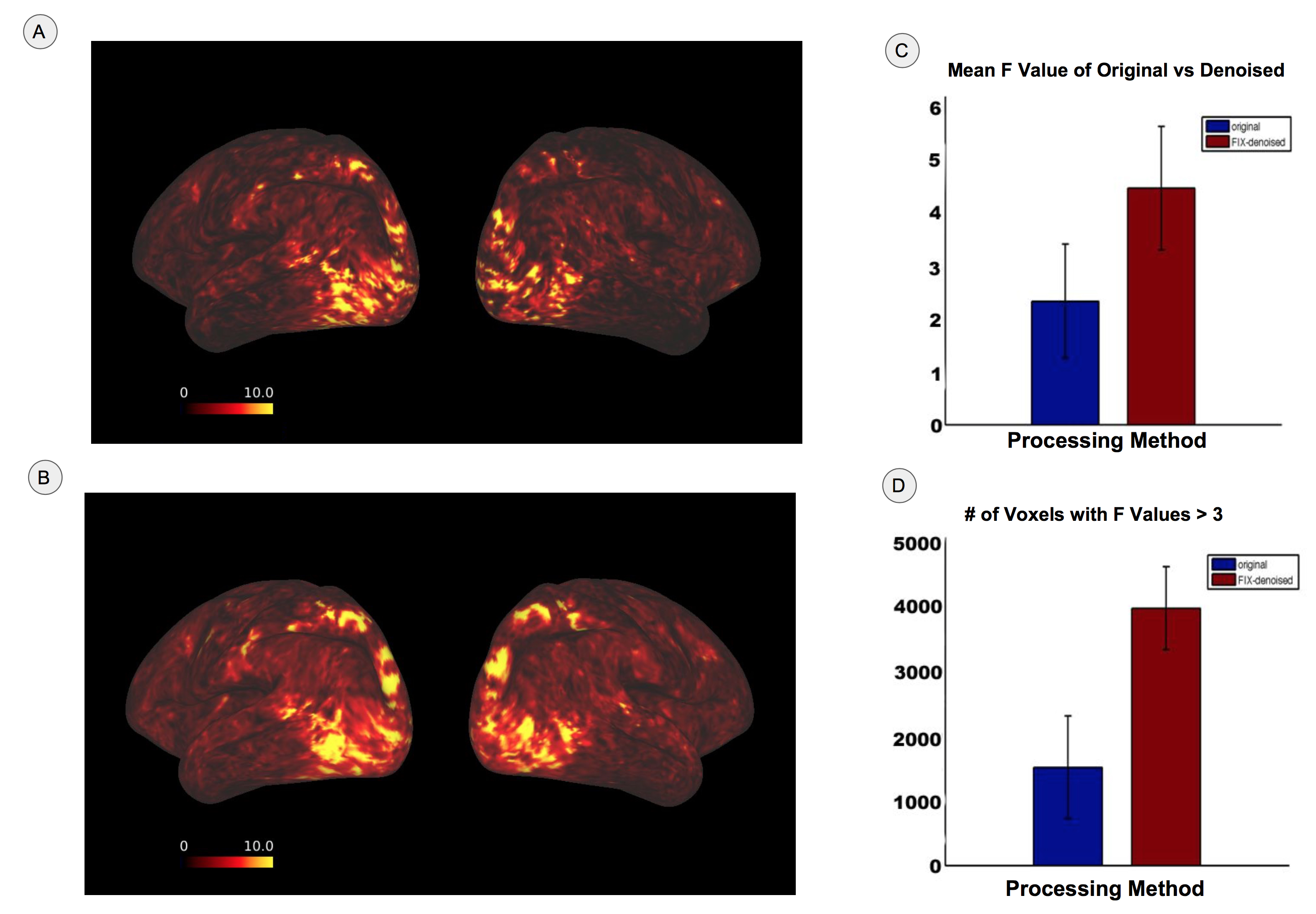
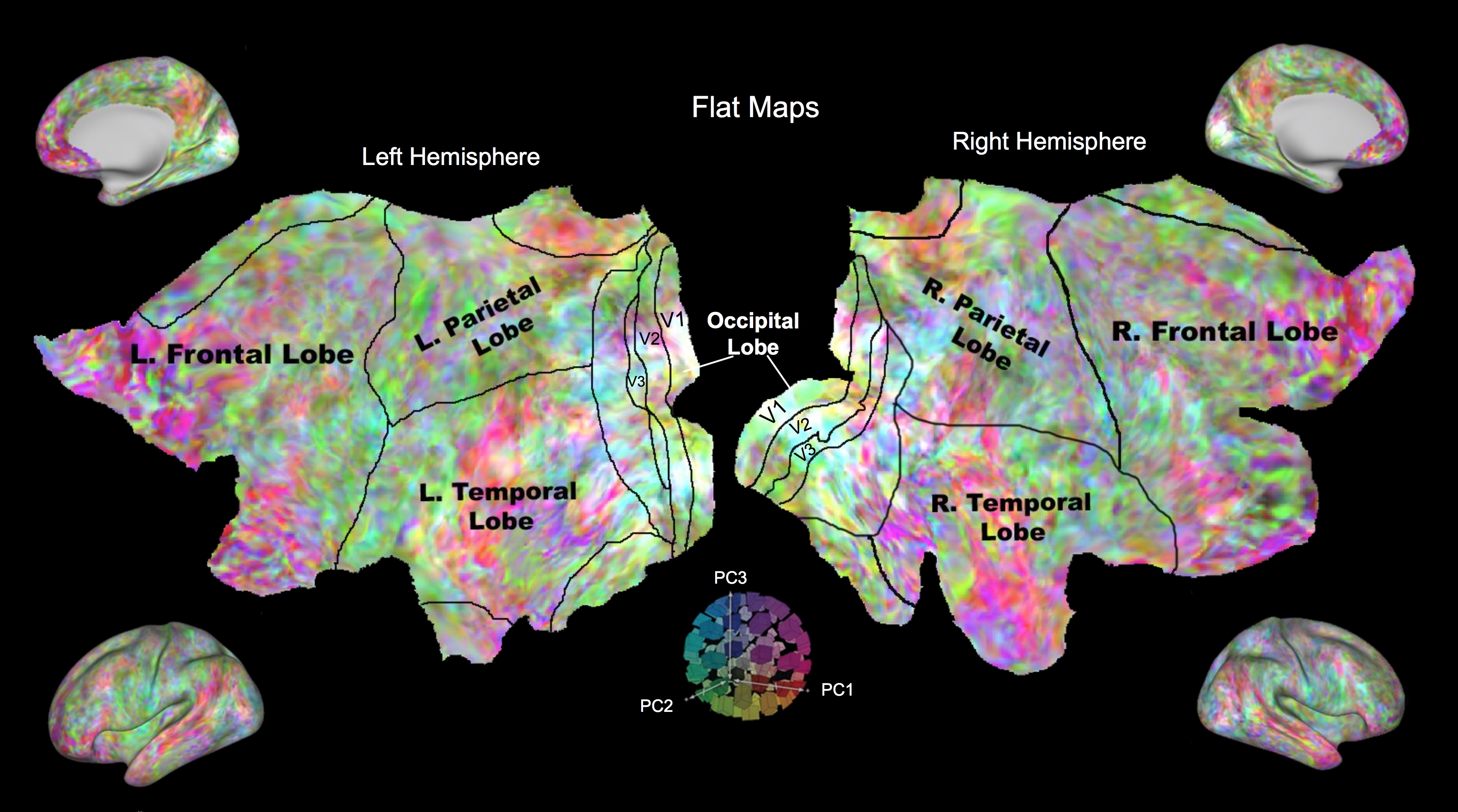
Figure 3. Preference of semantic content in Principal Component (PC) space. PC 1 (red) has preference for semantic content such as ‘male’, ‘living things’, and ‘person’. PC 2 (green) favors content such as ‘matter’, ‘tree’, and ‘plants’. PC 3 (blue) favors content such as ‘physical entity’, ‘body part’, and ‘things’. Different parts of the brain favor different semantic content. The visual cortex favors all the contents and thus appears white.