5295
Distributed and overlapping cortical networks represent visual categories1Electrical and Computer Engineering, Purdue University, West Lafayette, IN, United States, 2Electrical and Computer Engineering and Biomedical Engineering, Purdue University, West Lafayette, IN, United States
Synopsis
The principle of cortical representations when thousands of real-life objects and categories are involved remains unclear. Here, we built a computational model of the human visual system by using a deep neural network and predicted the cortical responses to natural visual stimuli. In particular, we trained the model by using fMRI data obtained while subjects watched very long (>10 hours) natural movie stimuli that contained thousands of visual object categories. Based on the model, we systematically analyzed the activation patterns in the brain induced by different kinds of object categories. We found that the categorical information was represented by distributed and overlapping cortical networks, as opposed to discrete and distinct areas. Three cortical networks represented such broad categories as biological objects, non-biological objects, and background scenes. More fine-grained categorical representations in the brain suggest that visual objects share more (spatially) similar cortical representations if they share more similar semantic meanings.
PURPOSE
How does the brain represent different objects in the rich visual world? Scientists commonly use a cherry-picking strategy to map the cortical activations with only a few objects or categories, e.g. faces and houses, and thus offer a narrowly-focused view of categorical representations. Here, we explored a new and high-throughput strategy to investigate the cortical representations of thousands of visual objects and categories, and to offer unique insights to the distributed network basis of categorical representations. Central to this strategy is a Deep Learning model, i.e. deep residual network (ResNet), which has enabled computers to recognize and segment natural pictures with human-like performance1.METHODS
RESULTS
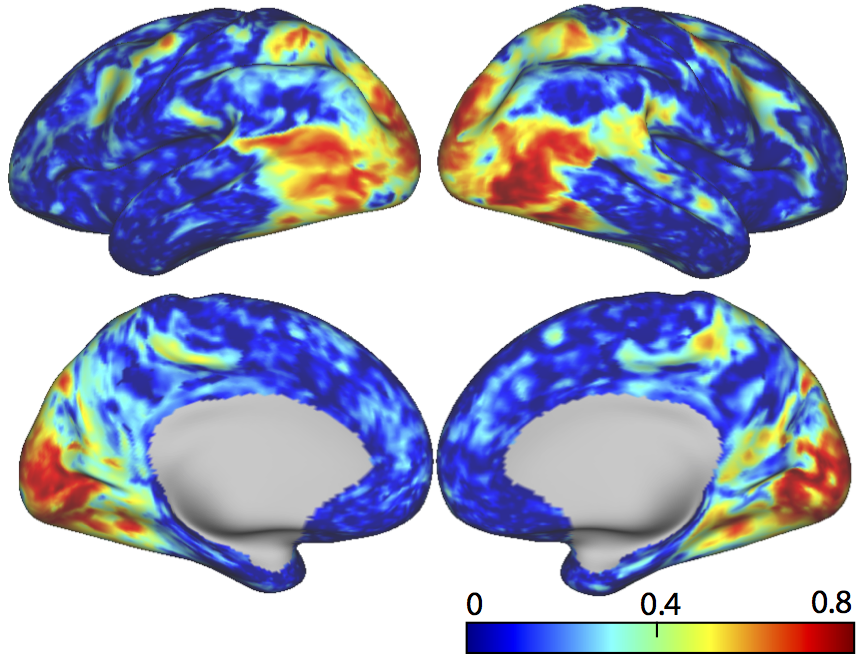
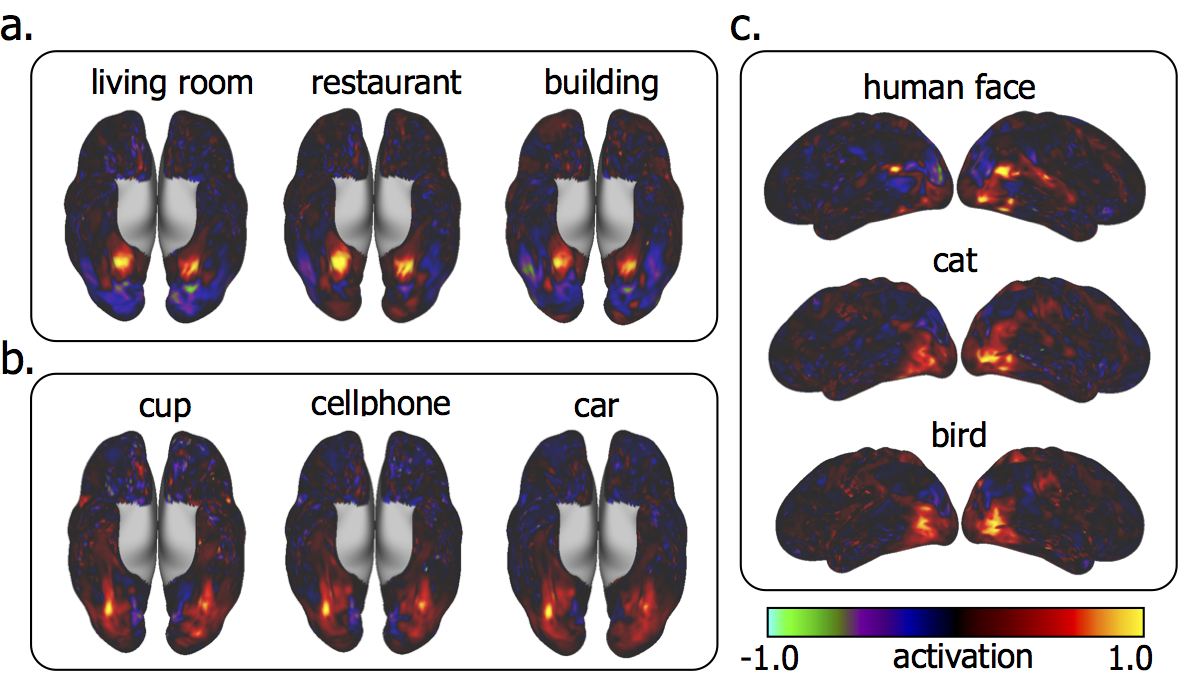
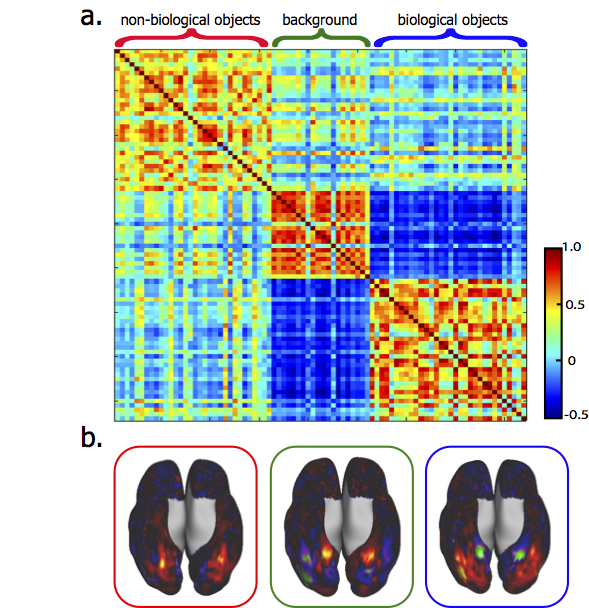
Trained with >10-hour video-fMRI data, the voxel-wise encoding models could reliably predict the cortical responses to novel testing movie stimuli with high accuracies for nearly the entire visual cortex (r = 0.64 ± 0.1) (Fig. 1). Applying the encoding models to 84 categories of natural pictures (1,000 pictures per category), we predicted the activation pattern corresponding to each category (Fig. 2). For example, human face was represented by a network including the fusiform face area (FFA), the occipital face area (OFA), the posterior superior temporal sulcus (pSTS); building was represented by activations at bilateral parahippocampal place area (PPA), with de-activations at FFA (Fig. 2). Some categories showed similar co-activation networks. For example, living room, restaurant, and building all had significant activations in PPA; cup, cellphone, and car also shared similar cortical representations; human face, cat and bird had distinct but overlapping representations (Fig. 2). All 84 cortical activation patterns could be grouped into three clusters based on their spatial similarities (Fig. 3). Interestingly, these clusters were found to bear different semantic content: the first cluster included non-biological objects (e.g. hat, computer, shoes, cellphone, car); the second cluster included biological objects (e.g. person, cat, horse, bird, fish); the third cluster included background scenes (e.g. bedroom, restaurant, street, market, office) (Fig. 3). The similarity of co-activation networks also revealed the similarity of semantic meanings of their corresponding objects; for example, the similarity between cat and dog (r = 0.9±0.04) was higher than cat and bird (r = 0.7±0.08) (p=0.0012, two-way t-test). The cortical representations between biological objects and background scenes were anti-correlated in the inferior temporal cortex (Fig. 3).DISCUSSION
Here we provide evidence that the categorical information is represented by distributed and overlapping cortical networks, as opposed to discrete and distinct areas. Three cortical networks represent such broad categories as biological objects, non-biological objects, and background scenes. More fine-grained categorical representations in the brain suggest that visual objects share more (spatially) similar cortical representations if they share more similar semantic meanings. These findings, as well as those from our previous studies2, advocate the use of brain-inspired artificial intelligence models and functional neural imaging and recording to advance our understanding of the brain itself.Acknowledgements
This work was supported in part by NIH R01MH104402.References
1. He, K., Zhang, X., Ren, S., & Sun, J. (2015). Deep residual learning for image recognition. arXiv preprint arXiv:1512.03385.
2. Wen, H., Shi, J., Zhang, Y., Lu, K. H., & Liu, Z. (2016). Neural Encoding and Decoding with Deep Learning for Dynamic Natural Vision. arXiv preprint arXiv:1608.03425.
Figures