3988
A Study of Simulated Training Data for Image Reconstruction from Subsampled MR Data using Artificial Neural Network1KAIST, Daejeon, Korea, Republic of
Synopsis
Recently, several works have applied the deep learning technique to medical imaging problems such as lesion classification and image reconstruction. The deep learning techniques have advantages of learning from big data, however, in medical imaging, collecting an amount of training data is not easy because of expense, privacy, and so on. Strategies to supplement insufficient training data are important topics for applying deep learning to medical imaging field. In this study, training data are generated from the simulated images and the acquired MR images, which are utilized to learn the architecture of multilayer perceptron to reduce imaging time.
Introduction
Several techniques have been proposed to reduce imaging time in MRI. Meanwhile, so-called deep learning has been applied to various fields such as computer vision and speech recognition, which overwhelmingly outperform the conventional techniques. Recently, several works have applied the deep learning technique to medical imaging problems such as lesion classification and image reconstruction 1. The deep learning techniques have advantages of learning from big data, however, in medical imaging, collecting an amount of training data is not easy because of expense, privacy, patient availability, and so on 1. Strategies to supplement insufficient training data are important topics for applying deep learning to medical imaging field. In this study, training data are generated from the simulated images and the acquired MR images, which are utilized to learn the architecture of multilayer perceptron (MLP).Materials and Methods
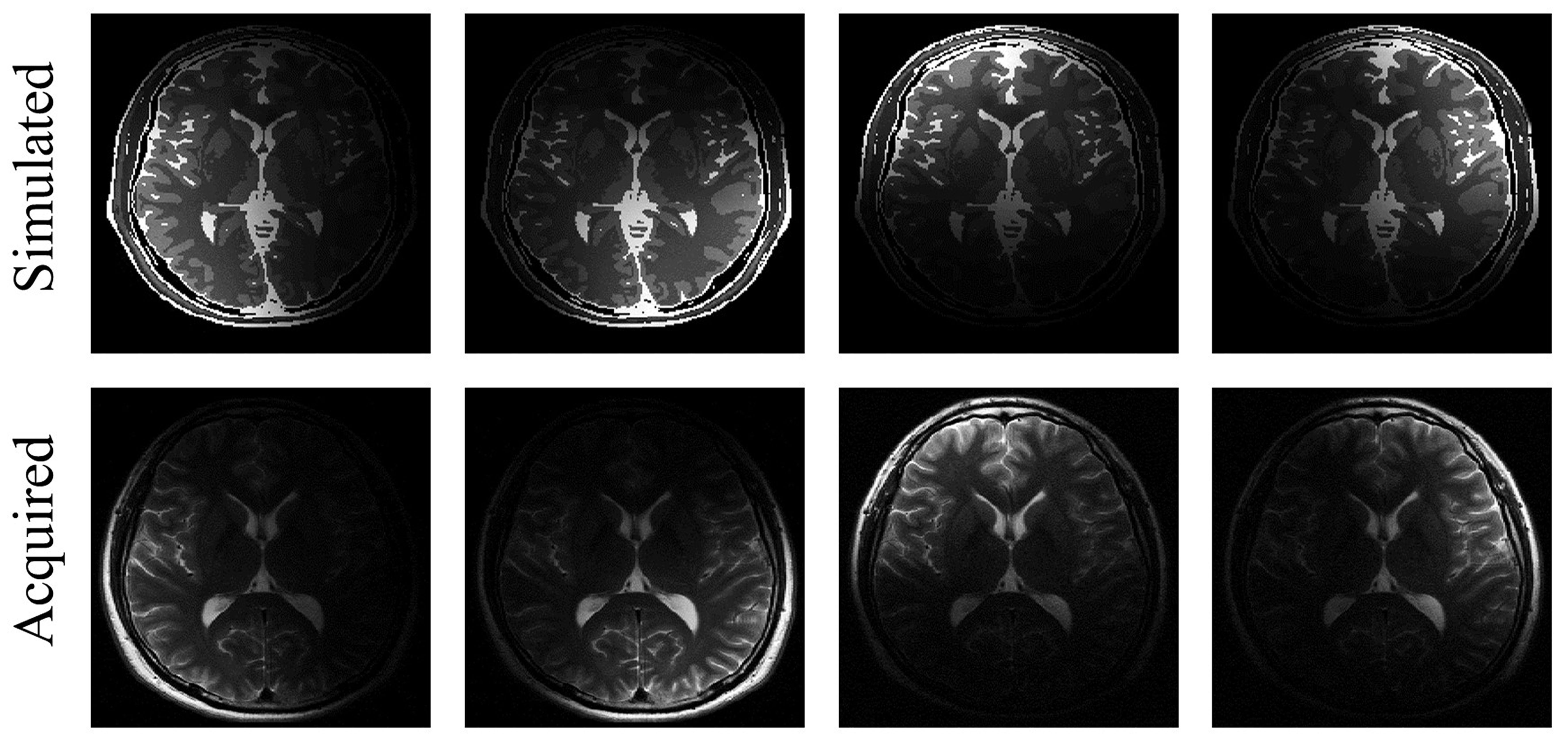
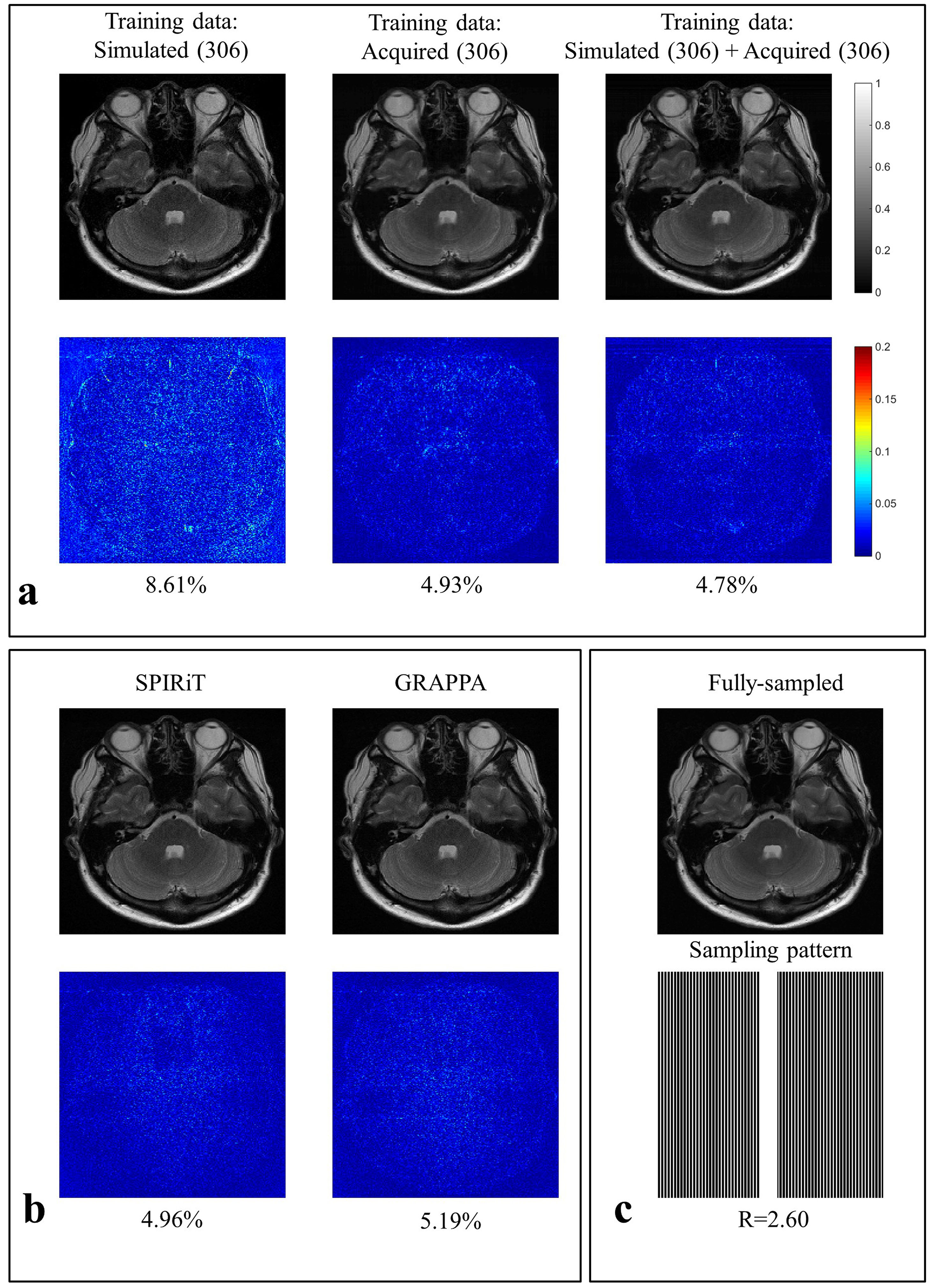
Fully-sampled T2-weighted (T2w) k-space data were obtained from healthy volunteers using the 3T MRI system (Magnetom Verio, Siemens Healthcare, Erlangen, Germany) with a 12-channel head coil. The imaging sequences were based on the fast spin-echo sequence with TR/TE = 5000/90 ms and matrix size = 384$$$\times$$$216. Simulated T2w images were generated from “brainweb” phantom data set by mimicking the acquired MR images, such as matrix size, sensitivity profile, and imaging contrast 2. Brain phantom images were generated by spin-echo signal formula, $$$S(x,y)=M_0 (x,y)(1-exp(-TR/(T_1 (x,y) )) )exp(-TE/(T_2 (x,y) ))$$$. Sensitivity maps were estimated from the acquired MR images 3, and multi-channel simulated images were generated by multiplying the brain phantom images with the estimated multi-channel sensitivity maps as shown in Figure 1. As shown in Figure 2, the proposed MLP architecture is modified from our previous work 4. The sensitivity maps are redundant as additional input data because they can be estimated from multi-channel images. So, they are not used as inputs of the MLP architecture. The acquired MR k-space data and the simulated k-space data are utilized to learn the MLP architecture. In order to train the MLP, fully-sampled multi-channel k-space data are retrospectively subsampled, rescaled to have unit energy for every multi-channel k-space data, inverse Fourier transformed, and then divided into real and imaginary images. All voxels of the multi-channel real and imaginary images from the subsampled data along the line in the phase encoding direction are used as an input of the MLP, and the corresponding line of the root-sum-of-squares of the fully-sampled multi-channel images is used as a desired output of the MLP. Three MLP architectures are learned by utilizing different training data such as 306 simulated images, 306 acquired MR images, and all of them. The MLP architectures have two hidden layers with 1728 neurons each, and rectified linear unit is used as an activation function. The size of the input vector is 5184 (216 phase encoding lines $$$\times$$$ 12 channels $$$\times$$$ 2 real and imaginary values), and the size of the output vector is 216. To compare the performances of three MLP architectures, an MR image that is not utilized for learning is reconstructed, and the normalized root-mean-square error (nRMSE) is calculated within objects. In addition, the reconstructed images from SPIRiT and GRAPPA are compared, whose acceleration factor (R) is 2.60 5, 6.Results
As shown in Figure 3, an MR image is reconstructed from subsampled k-space data by using SPIRiT, GRAPPA, and three MLP architectures with different training data. As shown in Figure 3a, the learned MLP from simulated training data can resolve aliasing artifacts of the subsampled MR image, but the reconstructed image is noisy, because the simulated training data is a little different from the acquired training data. The performance is improved when the simulated training data is additionally utilized with the acquired training data. The two MLP architectures utilizing the acquired training data are better in terms of nRMSE than SPIRiT and GRAPPA.Discussion and Conclusion
The proposed method generates simulated training data to supplement insufficient training data for the learning-based algorithm. It improves the performance of the learning-based method by utilizing the more training data. If the simulated training data is designed sophisticatedly to be more similar to the acquired MR data, the performance of the proposed MLP architecture would be improved. The simulated training data is important for applying deep learning to medical imaging because collecting training data is not easy. It could substitute the acquired MR training data, and it could be applied to parameter quantification, artifacts correction, and so on in MRI.Acknowledgements
This research was partly supported by the Brain Research Program, through the National Research Foundation (NRF) of Korea, funded by the Ministry of Science, ICT & Future Planning (2014M3C7033999), and by the Korea Health Technology R&D Project through the Korea Health Industry Development Institute (KHIDI), funded by the Ministry of Health & Welfare, Republic of Korea (grant number : HI14C1135).References
1. Greenspan H, et al. Guest Editorial Deep Learning in Medical Imaging: Overview and Future Promise of an Exciting New Technique. IEEE TMI. 2016;35:1153-1159.
2. Collins DL, et al. Design and construction of a realistic digital brain phantom. IEEE TMI. 1998;17:463-468.
3. Pruessmann KP, et al. SENSE: sensitivity encoding for fast MRI. MRM. 1999;42:952-962.
4. Kwon K, et al. Learning-based reconstruction using artificial neural network for higher acceleration. ISMRM, 2016. p 1801.
5. Lustig M, et al. SPIRiT: iterative self-consistent parallel imaging reconstruction from arbitrary k-space MRM 2010;64:457-471.
6. Griswold MA, et al. Generalized autocalibrating partially parallel acquisitions (GRAPPA). MRM 2002;47:1202-1210.
Figures