2129
Using Natural Language Processing to Explore the Correlation of Breast MR Findings and BI-RADS classification1Radiology, Peking University First Hospital, Beijing, People's Republic of China, 2Philips Research China, Shanghai, People's Republic of China
Synopsis
The decision tree trained on MR descriptions by natural language processing (NLP) method shows desirable capability in identifying the high-risk BI-RADS 5-6 class.From the decision path, we identify the key indicators to distinguish BI-RADS 5-6 from the relatively low-risk classes. And the inner heterogeneity of BI-RADS 4 cases makes it difficult to build a general model for this class.
Purpose
Natural language processing (NLP) can convert traditional text into structured form, and enable large data mining of breast imaging[1].So our purpose is to explore the correlation of breast MR findings and BI-RADS classification[2] by natural language processing (NLP) method.Methods
Data of breast MR were retrospectively obtained from Hospital Information System (HIS) from Jan. 2014 to Oct. 2016. The MR examinations for evaluation of breast cancer neoadjuvant therapy were excluded. NLP model was constructed and tested in the following steps: 1. Corpus pre-process: For each BI-RADS score mentioned in the conclusion part, a regular expression was employed to capture the corresponding anatomic site. Through fuzzy matching, descriptions in the findings section can be assigned to the corresponding anatomic site. Then the original MR report is segmented and re-organized into BI-RADS score-centered chunks. 2. Data pre-process: As BI-RADS 1indicates a relatively low risk and there are little descriptions in the MR reports, we excluded this classification from the data set. And BI-RADS 5 and BI-RADS 6 are merged as a new classification BI-RADS 5-6. 3.Feature Generation and Selection: To characterize each piece of MR findings, we generated 3-grams and 4-grams after word segmentation. The specific terms provided by clinicians were used to build a vocabulary for feature selection. An n-gram is selected as feature only if it includes at least one term in the provided vocabulary. Then the n-grams with incomplete semantic meaning were excluded by regular expressions, which were generated based on manual review and summary. Finally, each one of MR findings was represented by a vector, including the frequencies of selected features (n-grams). The decision tree to explore the correlation of MR findings and BI-RADS classifications (BI-RADS 2, BI-RADS 3, BI-RADS 4, BI-RADS 5-6) was test by the 10-fold cross validation (CV).Results
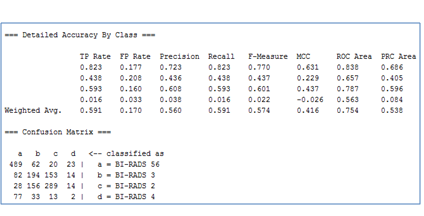
Totally1,649 BI-RADS scores (BI-RADS 2, n=487; BI-RADS 3, n=443; BI-RADS 4, n=125; BI-RADS 5-6, n=594) and the corresponding MR findings from the 355 records in the original Data set were included. The 10-fold CV demonstrated that the decision tree had better performance on the BI-RADS 5-6 class (AUC= 0.838), whereas the BI-RADS 4 class was easy to be misclassified (F-Measure= 0.022) (Fig 1).Looking into the decision tree (Fig 2), axillary adenopathy, breast composition categories, time-intensive curve types, mass margin, internal enhancement and so forth were the key indicators for the final decision to distinguish BI-RADS 5-6 from the relatively low-risk classes. But the decision path goes really deep to distinguish the BI-RADS 2 and BI-RADS 3.Discussion
Our results show that, the decision tree has the capability in identifying the high-risk BI-RADS 5-6 class. However, it seems difficult to further distinguish the relatively low-risk classes like BI-RADS 2 and BI-RADS 3. Because they all have the similar signs identified as benign lesion. As for BI-RADS 4 class, our results show that it is easy to be misclassified. We think that BI-RADS 4 covered benign and malignant lesions and maybe have more different MR signs. And the inner heterogeneity and limited number of BI-RADS 4 cases may influence the results.Conclusion
It is feasible to use the natural language processing indentifying the high-risk BI-RADS 5-6 class.Acknowledgements
No acknowledgement found.References
[1] Pons E, Braun LM, Hunink MG, et al. Natural Language Processing in Radiology: A Systematic Review. Radiology. 2016;279(2):329-343.
[2]Morris EA, Comstock CE, Lee CH, et al. ACR BI-RADS® Magnetic Resonance Imaging. In: ACR BI-RADS® Atlas, Breast Imaging Reporting and Data System. Reston, VA, American College of Radiology; 2013.
Figures