1409
Task-based Optimization of Regularization in Highly Accelerated Speech RT-MRI1Electrical Engineering, University of Southern California, Los Angeles, CA, United States
Synopsis
Speech RT-MRI has recently experienced significant improvements in
Purpose
Real-time MRI has emerged as a powerful tool to noninvasively assess vocal tract dynamics during speech production. It is continuing to provide new insights in several speech science and clinical applications (e.g. language production, language timing, speech errors, speech assessment pre and post oropharyngeal cancer treatment) 1,2,3). Recently, significant improvements in spatio-temporal resolution and coverage have been achieved via the use of sparse sampling and constrained reconstruction using object models (eg. low rank, and/or transform sparsity) 4-7. These require tuning of one or more regularization parameters that are used to perform a trade-off between data consistency and object model consistency. These parameters are chosen heuristically, based on an L-curve 6, or more often by visual assessment of image quality. In this work, we perform optimization for speech RT-MRI based on task-specific metrics including preservation of articulatory features. Specifically, we investigate the production of consonants and vowels.Methods
Speech RT-MRI data was collected on a GE Signa Excite 1.5 T scanner with a custom 8-channel upper airway coil. A golden-angle spiral readout spoiled gradient echo pulse sequence was used for data collection (spatial resolution: 1.34x1.34 mm2; readout time: 2.4ms; repetition time: 6msec; flip angle: 15°; slice thickness: 6 mm). Image reconstruction was performed using SENSE with total variation spatio-temporal regularization:
$$\arg\min_f \|{\cal A}(f)-\mathbf b\|_{2}^{2} + \lambda_t \|\nabla_t(f)\|_1 + \lambda_s \|\sqrt{|\nabla_x(f)|^{2} + |\nabla_y(f)|^{2}}\|_1$$
where $$$f$$$ is the spatio-temporal signal, and $$$\mathbf b$$$ is the under-sampled data from multiple coils. $$${\cal A}$$$ models coil sensitivity encoding and non-uniform Fourier Transform along the under-sampled spiral trajectory. $$$\nabla_x, \nabla_y, \nabla_t $$$, are respectively the first order finite difference operations along the spatial dimensions $$$x,y$$$, and time dimension $$$t$$$. $$$\lambda_s$$$ and $$$\lambda_t$$$ are regularization parameters that control the balance between data fidelity and object constraints.
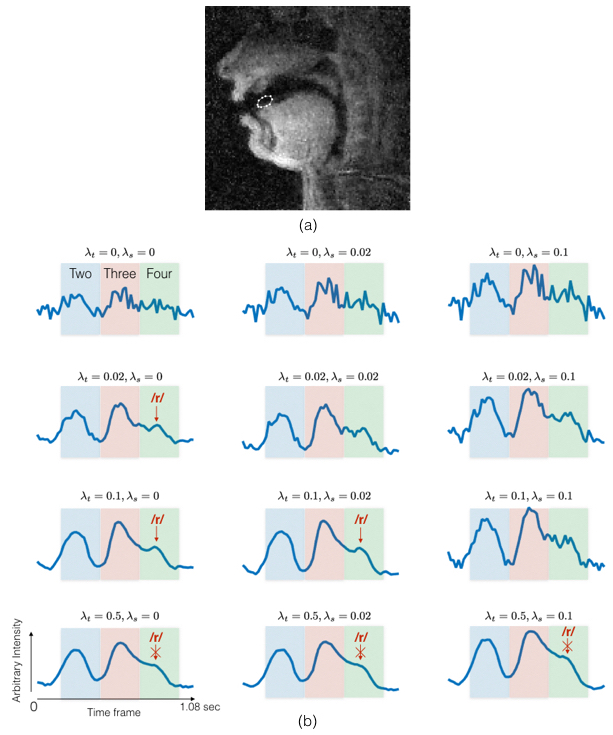
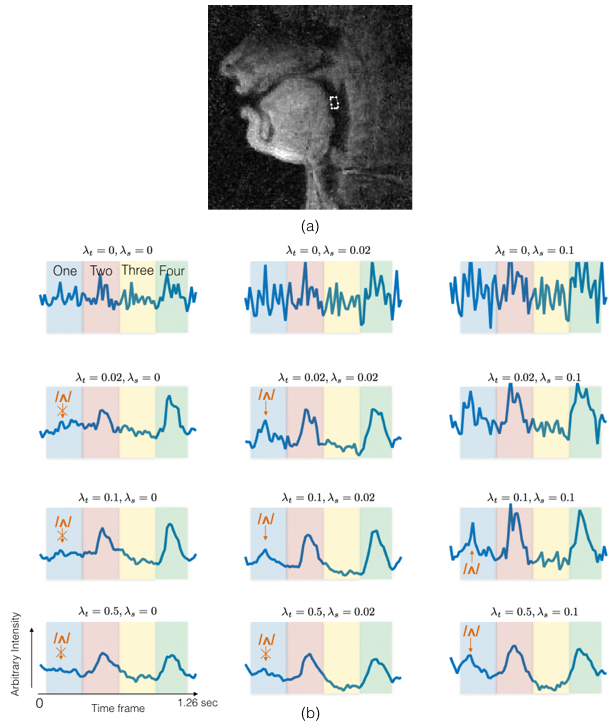
One subject was imaged while performing a task of counting numbers: “one-two-three-four” at a normal pace followed by a rapid pace (~4 times faster). Images were reconstructed with 3 spiral interleaves/frame with a time resolution of 18 ms/frame using a range of $$$\lambda_s$$$ ={0,0.02,0.05}, and $$$\lambda_t$$$ ={0,0.02,0.1,0.5}. Two region of interest (ROI) intensity-time profiles were extracted to highlight the dynamics at the tip of the tongue, and back of the tongue (see Figure 2 and 3) 8. Events of producing consonants ((/t/ in “two”, /th/ in “three” and /r/ in “four”) at a rapid pace were analyzed using the ROI-based time profiles between the tongue tip and the airway. The ROI based time profiles between the back of the tongue and the airway were also analyzed for the production of vowels (/ʌ/ in “one”, /u/ in “two”, /i/ in “three” and /ɔ/ in “four”).
Results/Discussion
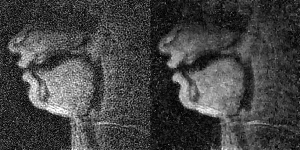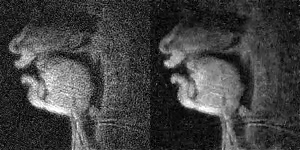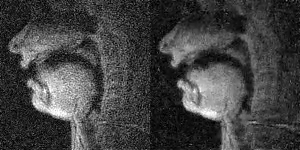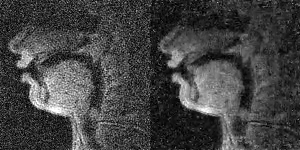
Figure 1 has twelve pairs of images and time profiles showing the upper lip and tongue movements, reconstructed with different temporal and spatial regularization parameters ($$$\lambda_t$$$ and $$$\lambda_s$$$). We observe as $$$\lambda_t$$$ increases, the intensity-time profiles show reduction in aliasing artifacts. At $$$\lambda_t$$$>0.1, reconstructions exhibit temporal stair-stepping artifacts. This is most evident in regions with subtle articulatory dynamics such as the back of the tongue. These temporal stair-stepping artifacts are qualitatively reduced by setting $$$\lambda_t$$$ between [0.01-0.2], and by introducing spatial regularization with $$$\lambda_s$$$ between [0.02-0.05]. With $$$\lambda_s$$$>0.02, the images also show blurred edges along the vocal tract.
Figure 2 shows the ROI time profiles for an ROI between the tongue tip and the airway. When, $$$\lambda_t$$$=0, the peaks are embedded in noise. Starting from the second row, when temporal constraints are applied, the peaks are identified. However, when $$$\lambda_t$$$ is high (>0.1), the small peak (/r/ sound) in green shaded region tend to blur due to temporal stair-stepping. This is reduced with smaller $$$\lambda_t$$$ (<0.1) and introduction of spatial regularization (0.01<$$$\lambda_s$$$<0.2).
Figure 3 shows the ROI time profiles for an ROI between the back of the tongue and the airway. As $$$\lambda_t$$$ increases, two high peaks are identified in the intensity-time profile. The introduction of spatial regularization allows for the recovery of subtle dynamic changes during the production of /ʌ/ in “one”, which has a small peak (blue shaded region).
Conclusion
We have demonstrated task-based optimization of highly accelerated speech RT-MRI. Specifically, we optimize spatio-temporal regularization parameters based on tasks-specific image features that need to be extracted for the study of consonant and vowel production. The choice of regularization parameters is evaluated both qualitatively with reconstructed images and time profiles, and a task-based ROI feature analysis. The results show temporal regularization can reduce aliasing artifacts, and combined use with spatial regularization can help resolve blurring movements caused by high temporal constraints.Acknowledgements
We acknowledge funding support from National Institute of Health under NIH-R01-DC007124 and National Science Foundation under NSF-1514544.References
1. Bresch E, Kim Y-C, Nayak K, Byrd D, Narayanan S. Seeing speech: Capturing vocal tract shaping using real-time magnetic resonance imaging. IEEE Signal Process. Mag. 2008;25:123–132.
2. Scott AD, Wylezinska M, Birch MJ, Miquel ME. Speech MRI: Morphology and function. Phys. Medica 2014.
3. Lingala SG, Sutton BP, Miquel ME, Nayak KS. Recommendations for real-time speech MRI. J. Magn. Reson. Imaging 2016;43:28–44. doi: 10.1002/jmri.24997.
4. Niebergall A, Zhang S, Kunay E, Keydana G, Job M, Uecker M, Frahm J. Real-time MRI of speaking at a resolution of 33 ms: Undersampled radial FLASH with nonlinear inverse reconstruction. Magn. Reson. Med. 2013;69:477–485.
5. Fu M, Barlaz MS, Holtrop JL, Perry JL, Kuehn DP, Shosted RK, Liang ZP, Sutton BP. High-frame-rate full-vocal-tract 3D dynamic speech imaging. Magn. Reson. Med. 2016. doi: 10.1002/mrm.26248.
6. Lingala SG, Zhu Y, Kim Y, Toutios A, Narayanan S, Nayak KS. A fast and flexible MRI system for the study of dynamic vocal tract shaping. Magn. Reson. Med. [Internet] 2016;00:n/a–n/a. doi: 10.1002/mrm.26090.
7. Iltis PW, Frahm J, Voit D, Joseph AA, Schoonderwaldt E, Altenmüller E. High-speed real-time magnetic resonance imaging of fast tongue movements in elite horn players. Quant. Imaging Med. Surg. [Internet] 2015;5:374–81. doi: 10.3978/j.issn.2223-4292.2015.0.
8. Lammert, A., Proctor, M., & Narayanan, S. (2010), Data-Driven Analysis of Realtime Vocal Tract MRI using Correlated Image Regions, In INTERSPEECH-2010, 1572–1575.
Figures