0690
Accelerated Projection Reconstruction MR imaging using Deep Residual Learning1KAIST, daejeon, Korea, Republic of
Synopsis
We propose a novel deep residual learning approach to reconstruct MR images from radial k-space data. We apply a transfer learning scheme that first pre-trains the network using large X-ray CT data set, and then performs a network fine-tuning using only a few MR data set. The proposed network clearly removes the streaking artifact better than other existing compressed sensing algorithm. Moreover, the computational speed is extremely faster than that of compressed sensing MRI.
Introduction
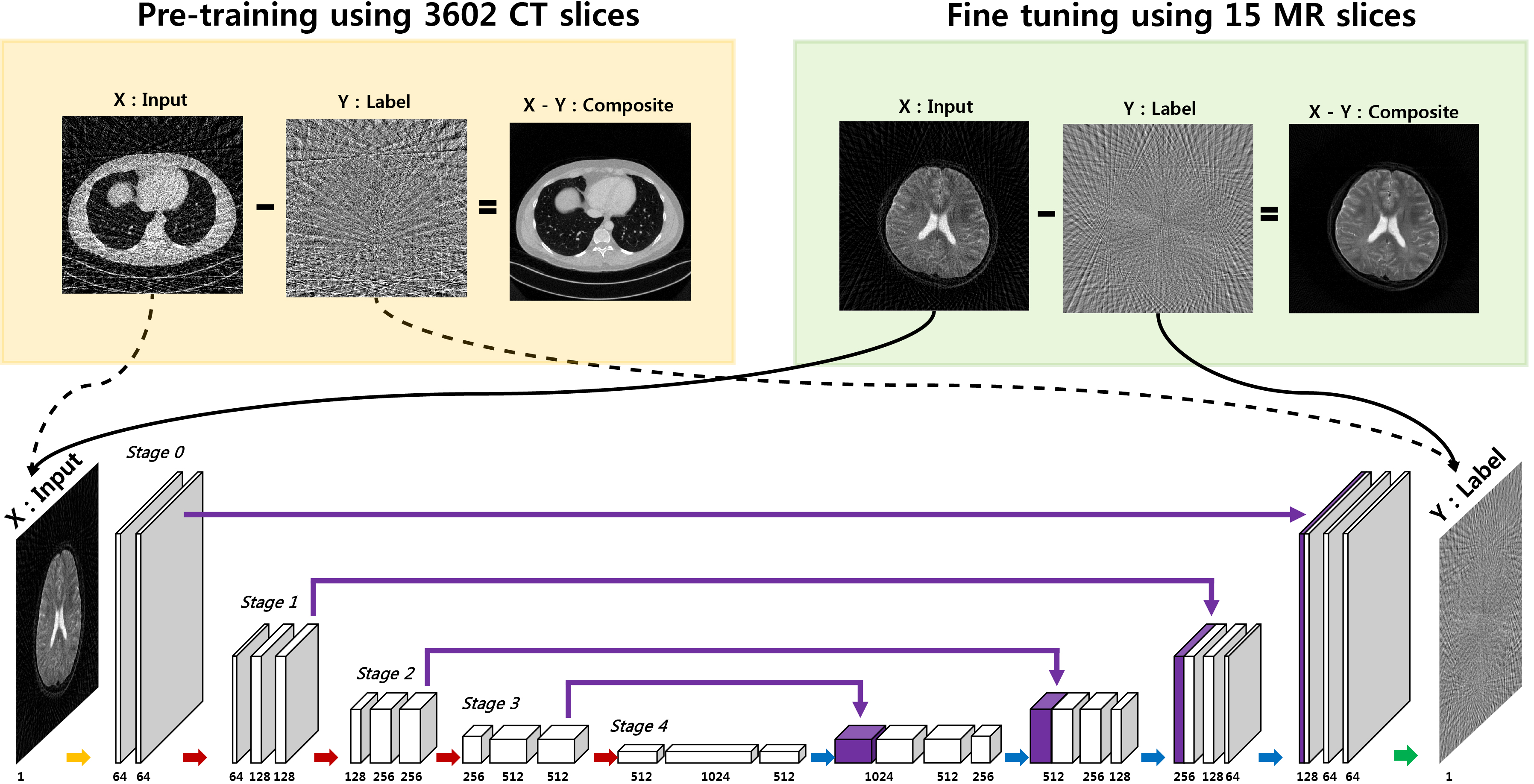
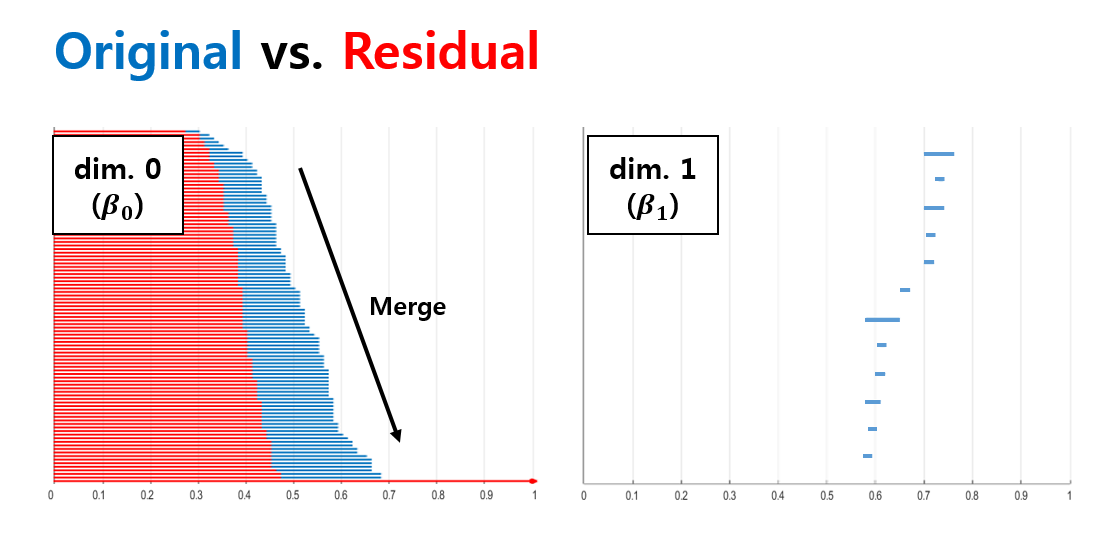
Projection reconstruction (PR) with radial k-space trajectory has many advantages. Specially, aliasing artifacts from radial under-sampling are less disrupting than the aliasing patterns caused by cartesian under-sampling. However, if the number of radial lines is too sparse, then the streaking artifact becomes too severe. However, compressed sensing (CS) algorithm usually takes long time for reconstruction. To address this issue, here we propose a novel deep residual learning approach as shown in Fig. 1 to learn streaking artifacts (Y) from under-sampled radial reconstruction (X). Once a streaking artifact image is estimated, an artifact-free image is obtained by subtracting the streaking artifacts from the input image (X). According to the statistical learning theory [1], the risk of a learning algorithm is bounded in terms of a complexity measure and the empirical risk. Thus, for a given network architecture, if the manifold composed of labels is simple, the risk can be reduced and the performance of the learning algorithm can be improved. Thus, we employed the persistent homology analysis [2] to investigate the topological structure of aliasing artifacts and the original images, respectively. As shown in Fig.2, Betti numbers $$$(\beta_0)$$$ quickly decays in the residual learning compared to the direct image learning. Moreover, the $$$\beta_1$$$ barcode showed that there exists no hole in the residual manifold. These findings imply that the residual image spaces have simpler topology than the original one. Moreover, in training a deep neural network, large data set is usually required. Because projection reconstruction is more common in X-ray CT, we propose a transfer learning scheme that first pre-trains the network using large X-ray CT data set, and then performs a network fine-tuning using only a few MR data set. The validity of this transfer learning is also evaluated.Material and Methods
As shown in Fig. 1, the proposed residual network consists of convolution layer, batch normalization [3], rectified linear unit (ReLU) [4], and contracting path connection [5]. Specifically, each stage contains four sequential layers composed of convolution with $$$3 \times 3$$$ kernels, batch normalization, and ReLU layers. Finally, the last stage has two sequential layers, and the last layer contains only convolution layer with $$$1 \times 1$$$ kernel. In the first half of the network, each stage is followed by a max pooling layer, whereas an average unpooling layer is used in the later half of the network. The number of channels for each convolution layer is illustrated in Fig. 1. Considering that the streaking artifact has globally distributed pattern (see the inserted images in Fig. 1), the enlarged effective receptive field from U-net is more advantageous in removal the streaking artifacts.
Network training
In training a deep neural network, large data set is usually required. To overcome deficiency of MR dataset, we used a pre-trained deep residual learning from our group. This was trained using CT dataset corresponding to 3602 slices of $$$512 \times 512$$$ real patient images which was provided by Low-dose CT Grand Challenge (http://www.aapm.org/GrandChallenge/LowDoseCT/). The model was trained by stochastic gradient descent. The regularization parameter was $$$\lambda = 10^{−4}$$$. The learning rate was set from $$$10^{−3}$$$ to $$$10^{−5}$$$ which was gradually reduced at each epoch. The number of epoch was 150. A mini-batch data using image patch was used, and the size of image patch was $$$256 \times 256$$$. Then, we performed a fine-tuning of the network with a 15 slices of MR dataset for training. The procedure of the fine-tuning was exactly the same as CT pre-training. Then, five MR slices with very different structures were used for validation. The concept of fine-tuning is illustrated as Fig. 1.Results
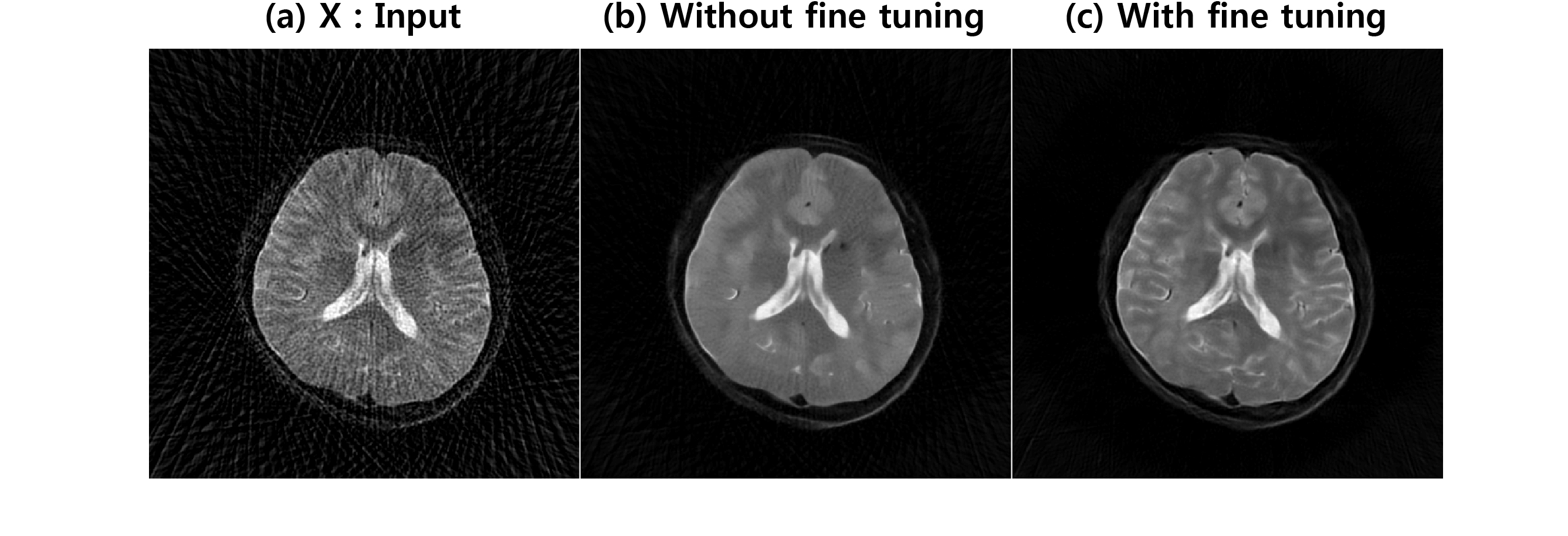
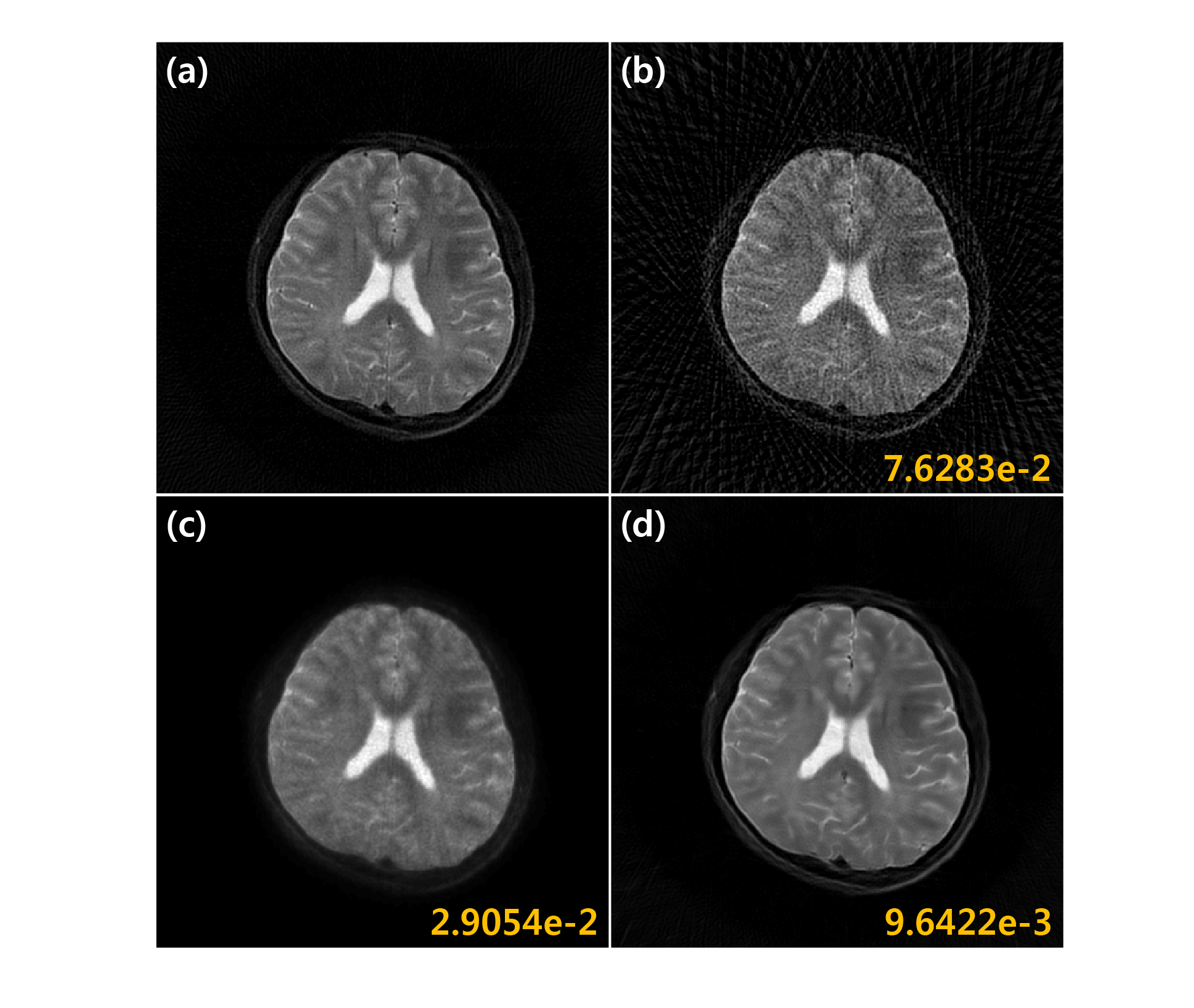
Fig. 3(a) shows reconstruction results using 45 projection views. Direct application of deep residual learning without MR fine-tuning results in cartoon like image in Fig. 3(b). After using residual network with MR fine-tuning, the result was significantly improved (Fig. 3(c)). The comparative study in Fig. 4 clearly showed that the proposed method outperforms the CS approach called PR-FOCUSS [6] by removing most of streaking artifact patterns and preserving detailed structure of the underlying image. Furthermore, the computational time for the proposed method was 75 ms/slice, whereas PR-FOCUSS [6] took about 24 sec/slice.Conclusion
We developed a deep residual learning for projection reconstruction MRI based on the analysis that residual manifold is topologically simpler than the origin one. The proposed network was pre-trained using large number of x-ray CT data set, then the network was fine-tuned using only 15 MR data. Reconstruction results outperformed the existing compressed sensing algorithm. Moreover, the computational speed was extremely faster than that of compressed sensing MRI.Acknowledgements
The authors would like to thanks Dr. Cynthia MaCollough, the Mayo Clinic, the American Association of Physicists in Medicine (AAPM), and grant EB01705 and EB01785 from the National Institute of Biomedical Imaging and Bioengineering for providing the Low-Dose CT Grand Challenge data set. This work is supported by Korea Science and Engineering Foundation, Grant number NRF2016R1A2B3008104.References
[1] Anthony, Martin, and Peter L. Bartlett. Neural network learning: Theoretical foundations. Cambridge university press, 2009.
[2] H. Edelsbrunner and J. Harer. Persistent homology-a survey. Contemporary mathematics, 453:257–282, 2008.
[3] S. Ioffe and C. Szegedy. Batch normalization: Accelerating deep network training by reducing internal covariate shift. arXiv preprint arXiv:1502.03167, 2015.
[4] A. Krizhevsky, I. Sutskever, and G. E. Hinton. Imagenet classification with deep convolutional neural networks. In Advances in neural information processing systems, pages 1097–1105, 2012.
[5] O. Ronneberger, P. Fischer, and T. Brox. U-net: Convolutional networks for biomedical image segmentation. In International Conference on Medical Image Computing and Computer-Assisted Intervention, pages 234–241. Springer, 2015.
[6] J.C. Ye, et al. Projection reconstruction MR imaging using FOCUSS. Magnetic Resonance in Medicine 57.4 (2007): 764-775.
Figures