0266
Cerebellum Tissue Segmentation with Ensemble Sparse Learning1Department of Radiology and BRIC, University of North Carolina at Chapel Hill, Chapel Hill, NC, United States
Synopsis
Accurate segmentation of cerebellum is important in studying the structural changes in brain and the alert in different neuro-developmental disorders. However,
Introduction
Human cerebellum is not only active in brain networks related to cognition and other brain functions, but also significant as biomarkers for different neurodevelopmental disorders. Accurate segmentation of cerebellum is important for studying structural changes in brain. However, cerebellum segmentation has received less attention in the field, compared with cerebrum segmentation. In fact, cerebellum tissue segmentation is also very challenging due to severe partial volume effect and low tissue contrast. In this study, an ensemble sparse learning is proposed for cerebellum tissue segmentation, i.e., white matter (WM), gray matter (GM) and cerebrospinal fluid (CSF).Methods
Totally, 10 volunteers with the average age of 30 years were recruited for this study. All the participants were scanned at 3T Siemens Trio scanner with a 3D MP-RAGE sequence, including 144 sagittal slices using image parameters such as TR = 1900 ms, TE =2.16ms, flip angle =9° and resolution =0.8594 × 0.8594× 0.999 mm3 . Each image is resampled into the isotropic resolution. Furthermore, to obtain accurate ground truth for classifier learning, 7T MRI with high contrast was also scanned based on which manual labeling was performed. In particular, 7T T1-weighted MRI was acquired in a Siemens Magnetom 7T whole-body MR scanner with a 3D MP2-RAGE sequence of 192 sagittal slices using image parameters such as TR = 6000 ms, TE =2.95ms, flip angle =4° and resolution = 0.80× 0.80 × 0.80 mm3.
In our proposed method, the auto-context random forest is employed as the ensemble system, where each tree is a weak learner. To tackle the low contrast and the partial volume effects in cerebellum, both appearance features and context features are employed to train random forest. In this work, Haar features are considered as the appearance features of each patch. After the first round of training, the probability maps $$$\bf P$$$ can be predicted by the trained classifier, which are further used to extract context features for the next round of training. Finally, for the voxels with low classification confidence, spatial sparse learning is also employed to update the probability map, which can be expressed as follows:
$$\begin{array}{l}\mathop {\min }\limits_{\bf{A}} \frac{1}{2}\left\| {{\bf{X}} - {\bf{DA}}} \right\|_{\rm F}^2 + \lambda {\left\| {{\bf{W}} \odot {\bf{A}}} \right\|_{2,1}}\\s.t.~~{A_{i,j}} > 0\end{array}$$
where $$${\bf X}$$$ denotes the patches in a neighborhood and $$$\bf D$$$ is the dictionary constructed by the patches in a window. $$$\bf A$$$ is the coefficient matrix, in which each column is the sparse coefficient of a patch. $$$\lambda$$$ is the regularization parameter. The $$$\ell_{2,1}$$$ norm aims to enforce the patches to share the common pattern in sparse representation. $$$\bf W$$$ is a weight matrix, which is used to indicate the similarity among the patches $$$\bf X$$$ and the dictionary $$$\bf D$$$. $$$\odot$$$ denotes the component-wise multiplication. After the sparse representation, the coefficient of the central patch $$$\bf \alpha$$$ is extracted from $$$\bf A$$$ and the probability belonging to the i-th class can be updated as
\begin{equation}{p_i} = \frac{{\bf w}^i \cdot {\bf \alpha }^i}{{\bf w} \cdot {\bf \alpha }},~~ i \in \{ {\rm{WM, GM, CSF}} \} \end{equation}
where $$$\bf w$$$ is the similarity of the patch with the atoms in the dictionary $$$\bf D$$$. $$${\bf w}^i$$$ and $$${\bf \alpha}^i$$$ are the i-th segments of vectors $$$\bf w$$$ and $$$\bf \alpha$$$ corresponding to the atoms from the i-th class. The denominator is a constant for normalization.
In this work, the leave-one-out validation is employed, where 9 subjects are for training and the rest one is used for testing. In the training stage, 60000 patches are randomly selected from each subject, and 10000 Haar-like features are generated for each patch. The forest contains 20 decision trees, where the maximal depth of each tree is set as 100 and the minimal number of samples in each leaf node is set as 8.
Results
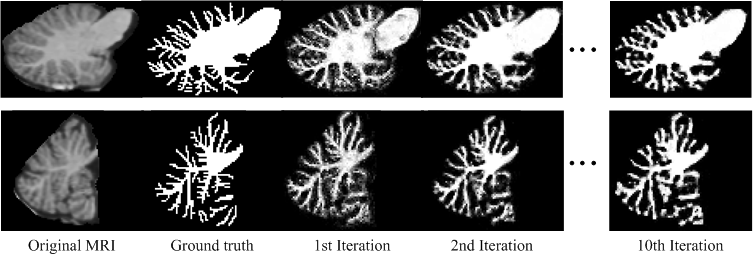
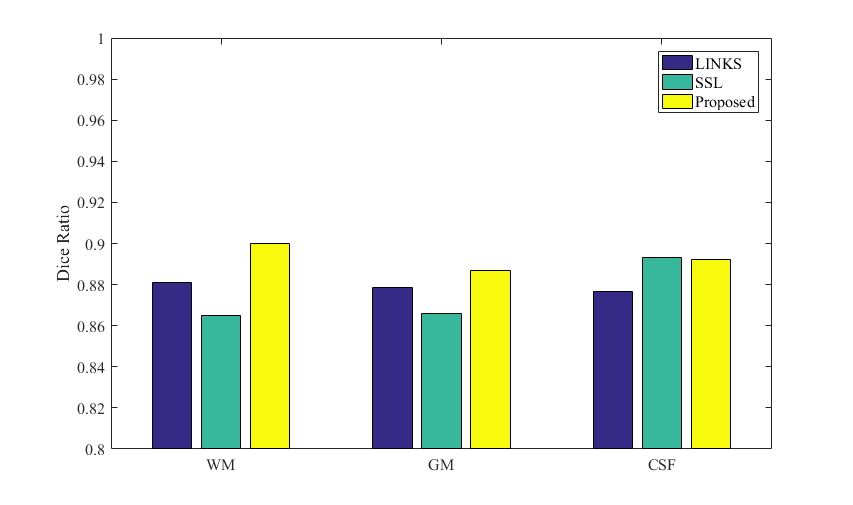
Fig.1 shows the intermediate results on a typical subject. It can be observed that the probability maps are gradually improved with iterations. Then, to verify the effectiveness of our proposed method, both auto-context random forest (LINKS) 1 and spatial sparse learning (SSL) method3 are compared with our proposed method in experiments. The comparison results are provided in Fig.2. It can be seen that our proposed method performs better than other methods. Furthermore, Dice ratios are shown in Fig. 3, which indicate again the best results by our proposed method.Conclusion
An ensemble sparse learning method has been presented for cerebellum tissue segmentation. In the experiments, our proposed method was compared with both the auto-context random forest method and the spatial sparse learning method, and our proposed method obtained the best performance.Acknowledgements
This work was supported in part by National Institutes of Health grants (MH100217, MH108914 and MH107815).References
1. Wang, Li, Yaozong Gao, Feng Shi, Gang Li, John H. Gilmore, Weili Lin, and Dinggang Shen. "LINKS: Learning-based multi-source Integration framework for Segmentation of infant brain images." NeuroImage. 2015, 108(3): 160-172.
2. Yu, Renping, Minghui Deng, Pew-Thian Yap, Zhihui Wei, Li Wang, and Dinggang Shen. "Learning-Based 3T Brain MRI Segmentation with Guidance from 7T MRI Labeling." In International Workshop on Machine Learning in Medical Imaging, pp. 213-220. Springer International Publishing, 2016.
3. Wang, Li, Feng Shi, Gang Li, Yaozong Gao, Weili Lin, John H. Gilmore, and Dinggang Shen. "Segmentation of neonatal brain MR images using patch-driven level sets." NeuroImage, 2014, 84 (1): 141-158.
4. Cocosco, Chris A., Alex P. Zijdenbos, and Alan C. Evans. "A fully automatic and robust brain MRI tissue classification method." Medical image analysis, 2003, 7(4): 513-527.
5. M. Prastawa, J. H. Gilmore, W. Lin, and G. Gerig, “Automatic segmentation of MR images of the developing newborn brain,” Medical image analysis, 2005, 9(5): 457–466, 2005.
Figures