4869
Feature Reduction and Selection: a Study on their Importance in the Context of Radiomics1Diagnostic and Interventional Radiology, University Hospital of Tuebingen, Tübingen, Germany, 2Institute of Signal Processing and System Theory, University of Stuttgart, Stuttgart, Germany, 3School of Biomedical Engineering and Imaging Sciences, King's College London/St Thomas' Hospital, London, United Kingdom
Synopsis
Using large amounts of image features in the context of Radiomics to perform complex image analysis tasks yields promising results for clinical applications. While it is easy to extract a large amount of features from medical images, it is complex to select the right features for a specific scientific problem. This study aims to show, how important it is to pay attention to choosing the right technique to select the most suitable features by means of feature reduction or selection on the example of two Radiomics-related MR image classification tasks.
Introduction
In recent years, the potential of complex image features combined with advanced digital post processing methods has been recognized for medical image analysis, especially in the context of Radiomics1,2. While extracting a large number of traditional and higher order features yields promising results for many clinical applications, there are also some drawbacks. Extracting too many features can lead to unnecessary large models, which may not converge at all, and often causes overfitting and thus bad generalization of the classifier. It is hence necessary to not only extract features, but choose the right technique to select the best subset of features for the scientific question at hand.
Since manually selecting the right features out of large numbers of extracted features is impossible, automated methods are necessary. Which method is suitable differs depending on data and
scientific question. With this
study, we aim to demonstrate how important choosing the right feature
reduction technique is, especially for applications in context
of Radiomics. To facilitate this time-intensive task, we included algorithms for feature
reduction/selection in ImFEATbox, our research toolbox for
medical image features. We use these algorithms on the features
extracted from two data sets with different classification
tasks and evaluate the results regarding how well the feature reduction techniques work on the respective data set.
Methods
We
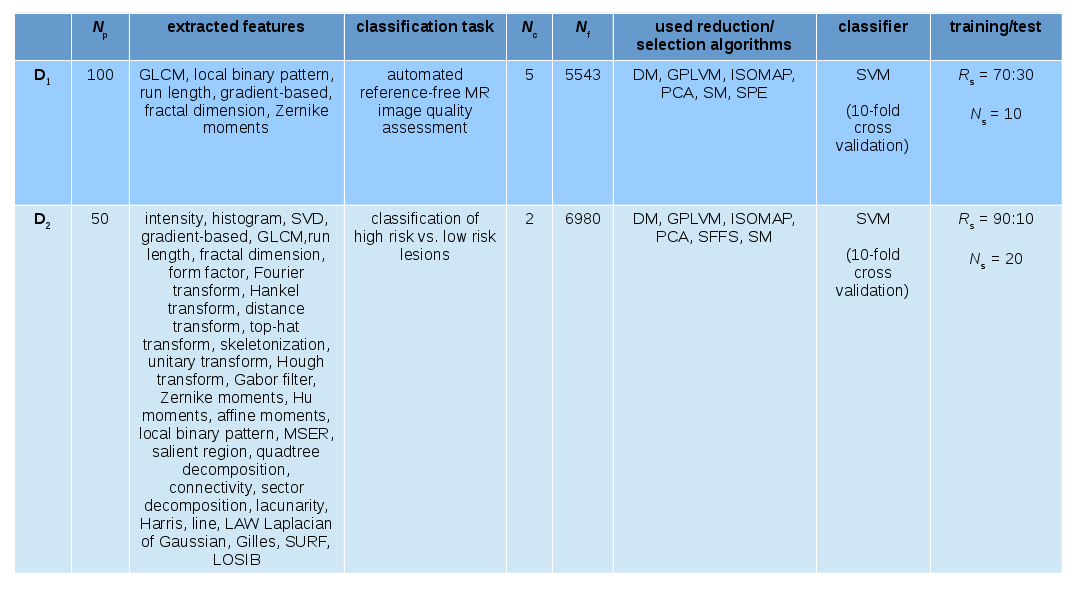
used two MR data sets in this study (Figure 1). D1
consists of images acquired for
automated reference-free image quality assessment3-5 (IQA) . D2 consisting of data from patients with prostate cancer was
used for Gleason Score prediction6.
We
extracted the features with ImFEATbox6,7, then employed the included feature reduction/selection algorithms before training a classifier to
solve the respective task.
Reduction
and selection of features can be performed supervised or
unsupervised. In this study, we focus on unsupervised methods.
Both feature reduction and selection start with a full set F of all extracted features and result in a smaller feature set F*, which is then passed on to the classifier. The main difference is, that reduction techniques transform F to a new matrix F* by exploiting underlying structures in feature space, whereas selection algorithms choose subsets of F according to significance of the features, determined by different criteria.
The feature reduction methods we used in this study are
- principle component analysis (PCA)8
- Sammon mapping (SM)9
- diffusion mapping (DM)10
- stochastic proximity embedding (SPE)11
- isometric feature mapping (ISOMAP)12
- Gaussian process latent variable model (GPLVM)13
We also used one feature selection algorithm, sequential floating forward selection (SFFS)14. Due to the high computational cost of this method, we only employed it on the smaller data set D2.
After reduction with the aforementioned techniques, we trained support vector machines (SVM). We then compared the performance of the SVMs and thus the reduction techniques for each classification task. Additionally, for D2 we investigated the influence of the originally extracted features on how well reduction/selection methods work.
Results
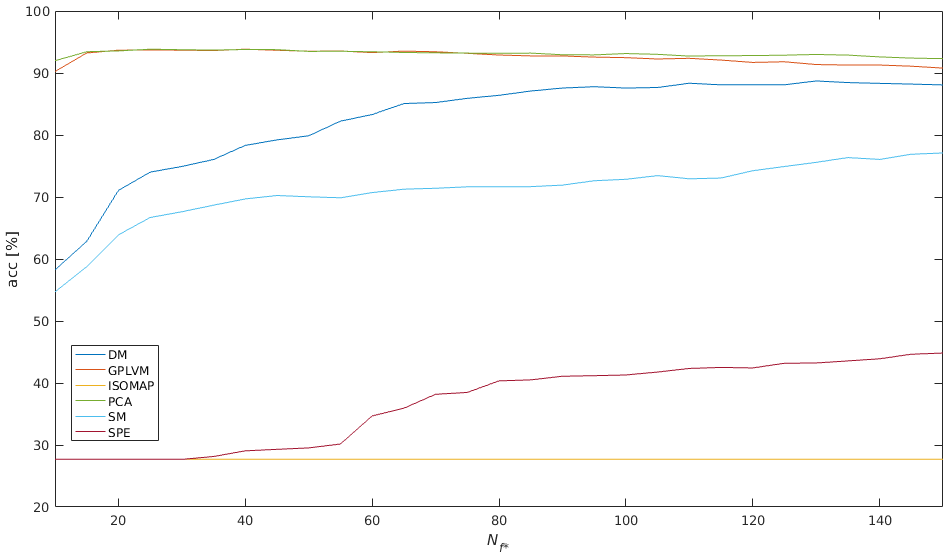
Data set D1: Figure 2 shows the results for data set D1. The best results (acc = 93,84%) are achieved with PCA and GPLVM.
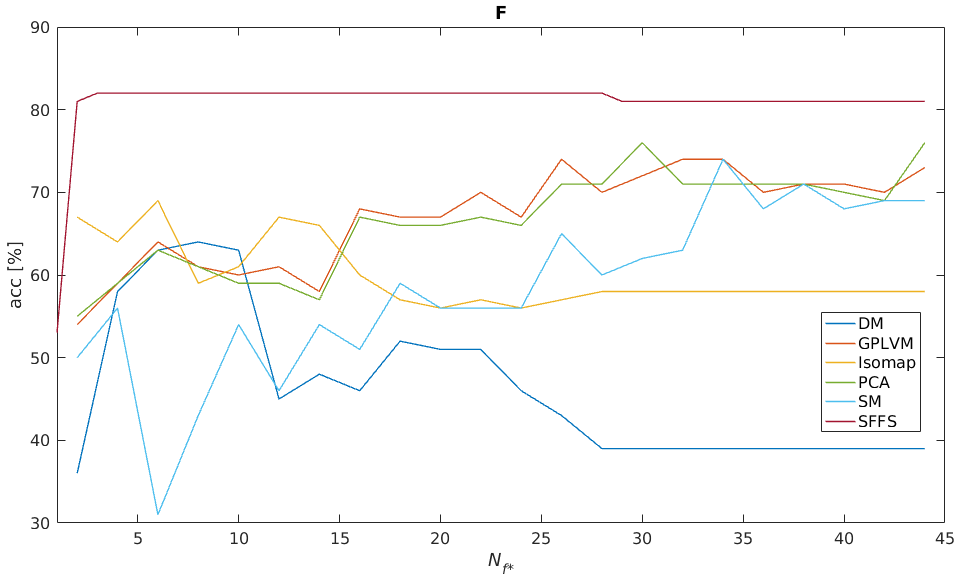
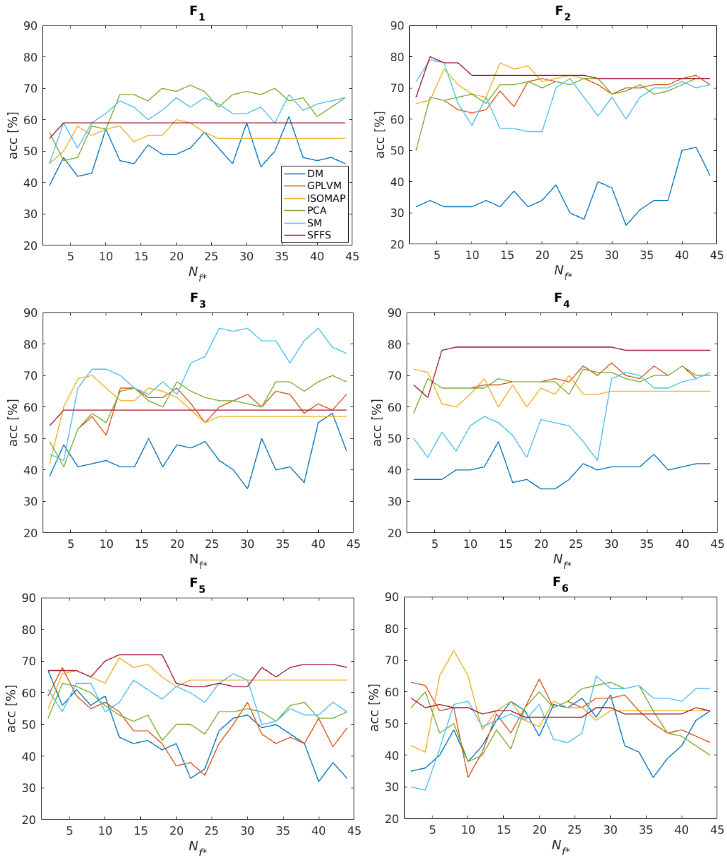
Data set D2: Results are depicted in Figure 3. Feature selection via SFFS yields significantly better results (acc = 82%) than the employed reduction techniques. Regarding the influence of the extracted features, the results in Figure 4 clearly illustrate how important it is to consider this factor. The 6 different feature subsets Fn we analyzed are described in Figure 5.
Discussion
The
results we obtained for both exemplary classification tasks clearly
indicate, that the “right” feature reduction or selection method
strongly depends on the scientific problem as well as the extracted
features. For example, while SM applied to feature set F3 leads to
the best overall result for Gleason score prediction (85%), it
results in mediocre accuracies for F1,2,4,5,6 and
for IQA. We thus want to emphasize that it is crucial for Radiomics to try different combinations of feature extraction and reduction and that it is desirable that this can be done as conveniently as possible, e.g. by using our toolbox.
Conclusion
In the context of Radiomics, using suitable techniques to reduce the extracted feature space or select the right features for a specific question is a very important task. Which reduction technique works best strongly depends on both data and the classification setup, hence choosing the right method significantly influences how well a classifier can be trained with the features extracted from medical imaging data. Using our toolbox ImFEATbox, which provides multiple suitable algorithms for both feature extraction and reduction, can facilitate the time-consuming search for the right combination of extracted features and reduction method.Acknowledgements
No acknowledgement found.References
1. P. Lambini, E. Rios-Velazquez, R. Leijenaar, S. Carvalho,R.G. van Stiphout, P. Granton, C.M. Zegers, R. Gillies, R. Boellard, A. Dekker, H.J. Aerts: “Radiomics: Extracting more information from medical images using advanced feature analysis.” Eur. J. Cancer 48(4):441–446., 2012 https://doi.org/10.1016/j.ejca.2011.11.036.
2. R.J. Gillies, P.E. Kinahan, H. Hricak: “Radiomics: Images are more than pictures, they are data.” Radiology 278(2):563–577, 2016.
3. T. Küstner, S. Gatidis, A. Liebgott, M. Schwartz, L. Mauch, P. Martirosian, H. Schmidt, N. Schwenzer, K. Nikolaou, F. Bamberg, B. Yang and F. Schick: “A machine-learning framework for automatic reference-free quality assessment in MRI”, Magnetic Resonance Imaging, 53, 134 - 147, 2018. doi: https://doi.org/10.1016/j.mri.2018.07.003
4. A. Liebgott, T. Küstner, S. Gatidis, F. Schick an B. Yang: "Active Learning for Magnetic Resonance Image Quality Assessment", Proceedings of the 41th IEEE International Conference on Acoustics, Speech and Signal Processing ICASSP 2016, March 2016, Shanghai, China.
5. A. Liebgott, D. Boborzi, S. Gatidis, F. Schick, K. Nikolaou, B. Yang and T. Küstner: "Active learning for automated reference-free MR image quality assessment: analysis of the influence of intra-batch redundancy on the number of required training samples", Proceedings of the Joint Annual Meeting ISMRM-ESMRMB 2018, June 2018, Paris, France.
6. A. Liebgott, T. Küstner, H. Strohmeier, T. Hepp, P. Mangold, P. Martirosian, F. Bamberg, K. Nikolaou, B. Yang and S. Gatidis: “ImFEATbox: a toolbox for extraction and analysis of medical image features”, International Journal of Computer Assisted Radiology and Surgery, Sep 2018. Springer Verlag, ISSN 1861-6429, https://doi.org/10.1007/s11548-018-1859-7
7.
“ImFEATbox,”
https://github.com/annikaliebgott/ImFEATbox, Nov. 2018.
8.S. Wold, K. Esbensen and P. Geladi: “Principal component analysis,” Chemometrics and intelligent laboratory systems, Bd. 2, Nr. 1-3, S. 37–52, 1987.
9. J. W. Sammon: “A nonlinear mapping for data structure analysis,” IEEE Transactions on computers, Bd. 100, Nr. 5, S. 401–409, 1969.
10. R. R. Coifman and S. Lafon:“Diffusion maps,” Applied and computational harmonic analysis, Bd. 21, Nr. 1, S. 5–30, 2006. [REF SPE] D. K. Agrafiotis: “Stochastic proximity embedding,” Journal of computational chemistry, Bd. 24, Nr. 10, S. 1215–1221, 2003.
11. J. B. Tenenbaum, V. de Silva and J. C. Langford: “A Global Geometric Framework for Nonlinear Dimensionality Reduction”, Science 290, (2000), 2319–2323.
12. N. D. Lawrence: “Gaussian process latent variable models for visualisation of high dimensional data,” in Advances in neural information processing systems, 2004, S. 329–336.
13. P. Pudil, F. J. Ferri, J. Novovicova and J. Kittler: “Floating search methods for feature selection with nonmonotonic criterion functions,” in Proceedings of the 12th IAPR International Conference on Pattern Recognition, Vol. 3 - Conference C: Signal Processing (Cat. No.94CH3440-5), Oct 1994, vol. 2, pp. 279–283 vol.2.
Figures