4868
Towards Contrast-Independent Automated Motion Detection Using 2D Adversarial DenseNets1Digital Technology and Innovation, Siemens Healthineers, Princeton, NJ, United States, 2Magnetic Resonance, Siemens Healthcare GmbH, Erlangen, Germany, 3Radiology, Icahn School of Medicine at Mount Sinai, New York City, NY, United States, 4Electrical Engineering, Johns Hopkins University, Baltimore, MD, United States
Synopsis
Patient motion is a challenging and common source of artifacts in MRI. Two recent studies investigating motion detection with convolutional neural networks showed promising results, but did not generalize to varying MRI contrasts. We present a unified, domain adapted deep learning routine to provide automated image motion assessment in MR brain scans with T1 and T2 contrast. We aim to limit the influence of varying image contrasts, scanner models, and scan parameters in the motion detection routine by using adversarial training.
INTRODUCTION
The generation of high-quality MR images providing maximal diagnostic value is of key importance. Optimization of both the scanning workflow and the image quality are in dire need to render high-quality MRI a cost-effective imaging modality. Patient motion is a challenging and common source of artifacts in MRI. Conventional image-based methods1-3 exhibits limited classification accuracy. Two recent studies investigating motion detection with convolutional neural networks showed promising results, but did not generalize to varying MRI contrasts4,5. Here, we present a unified, domain adapted deep learning routine to provide automated image motion assessment in MR brain scans with T1 and T2 contrast. We aim to limit the influence of varying image contrasts, scanner models, and scan parameters in the motion detection routine by using adversarial training.METHODS
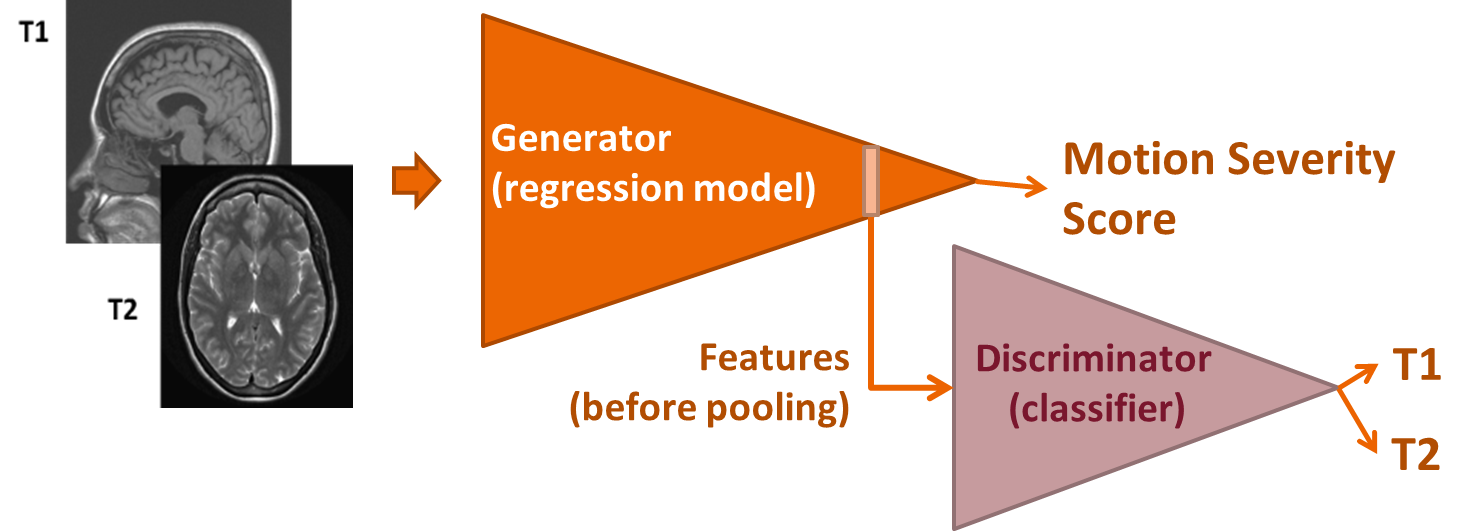
Motion-contaminated images for training and testing were synthesized from motion artifact-free images. A data set from the Human Connectome Project (HCP)6 containing both T1- and T2-weighted images (dataset size: T1: ~75k, T2: ~75k 2D images) collected using 3T MR scanners from a single vendor were used for training and 1% reserved for testing (referred to as HCP below). Around 64,000 clinical T2-weighted 2D images collected at Mount Sinai hospital using 1.5T MR scanners from two vendors were used exclusively for testing (referred to as MtSinai below). Motion artifacts were introduced into the original datasets by means of a custom-tailored routine5 considering time-dependent translation and k-space sampling order. The simulated motion varied in frequency and severity to cover realistic scenarios. The target quality scores of the image motion detection regression were chosen to be the mean structural similarity index (M-SSIM) computed from the motion-simulated image with respect to the original motion-free image. Data augmentation (rotation by π/2, π, 3 π/2, and flips along horizontal and vertical image axis) was performed on the training data. The automated motion assessment routine is based on a 2D DenseNet regression model (no. dense blocks: 2, growth rate: 3, no. filters in first convolutional layer: 32), yielding a scalar quality score for each input image. An adversarial discriminator based on a DenseNet (input: 9x32x32, no. dense blocks: 2, growth rate: 3, no. filters in first convolutional layer: 12) is added for classification of T1 vs. T2 image contrast. The discriminator is fed with the features generated by the regression model at the position of the last layer before pooling. Its main goal is to generate features for the regression model that are independent of the MRI contrast (see Fig. 1). The overall regression loss = Lgen - λLdiscr, where Lgen is the L1-norm of regression target scores, and Ldiscr is an adversarial term containing the classification loss (cross entropy) of the discriminator (here λ=0.5). Both generator and discriminator employed Adam optimization. A non-adversarial network using the same regression model was trained as well for comparison. Finally, a quality score threshold was set to derive an image classification between an “acceptable” and “unacceptable” image quality.RESULTS AND DISCUSSION
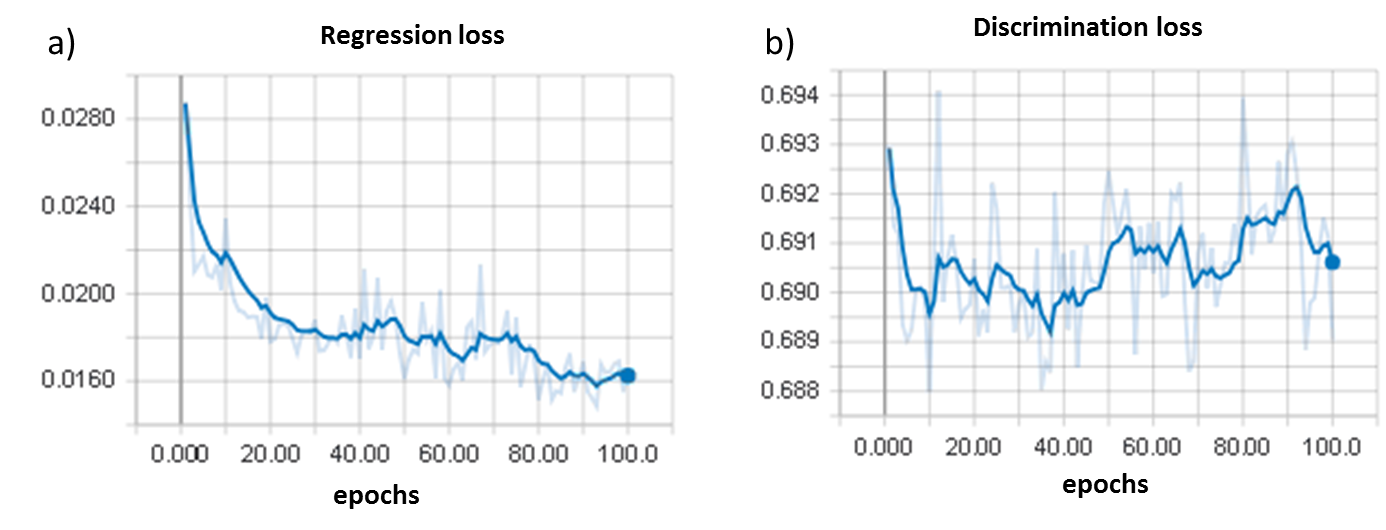
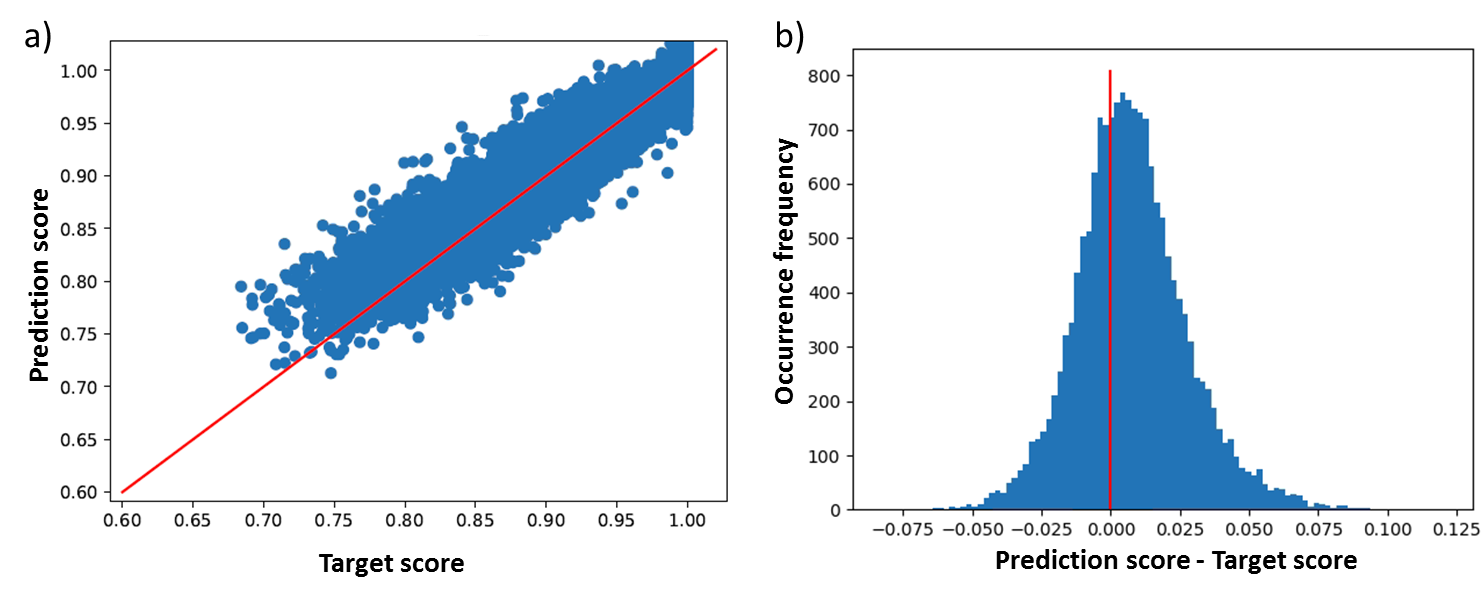
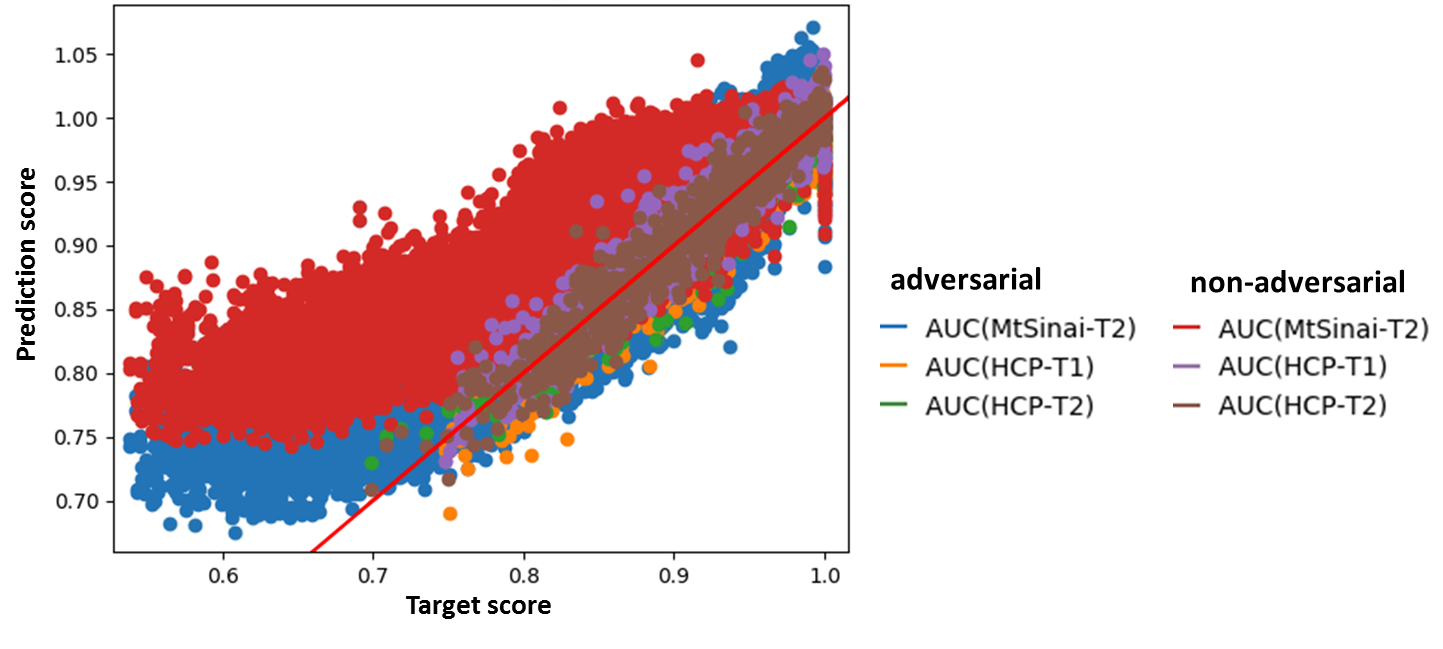
The discriminator training loss (Fig. 2a) and the regression validation loss (Fig. 2b) indicate proper regression training, while the discriminator appropriately fails to improve discerning the MRI contrasts. Fig. 3a displays the distribution of the predicted image quality scores versus the target values from HCP testing data. An analysis of the distribution of the differences between predicted and target scores (Fig. 3b) reveals vanishing regression bias of 0.008 and a regression standard deviation of around 0.020. To demonstrate the formation of generalized motion detection features, Fig. 4 displays the distribution of the predicted image quality scores versus the M-SSIM target values for an adversarial and a non-adversarial model trained on HCP T1 and T2 images, but additionally validated on MtSinai T2 data. All areas under the curve (AUC) are summarized in Fig. 4. On the MtSinai data, using an M-SSIM threshold of 0.99 for the image quality acceptance, the non-adversarial network showed a large prediction error (AUC = 0.81), while the adversarial network exhibits significantly better classification performance (AUC = 0.89). Besides the desired contrast-independence, this demonstrates a step towards independence of the motion detection routine with respect to the MR scanner model and other scan parameters.CONCLUSION
This proof-of-concept shows the validity of our adversarial training approach to deliver automated motion assessment of MR images in a contrast-, scanner model-, and scan parameter-independent fashion. An appropriate classification threshold score value has yet to be derived from a clinically determined quality ground truth.DISCLAIMER
This feature is based on research, and is not commercially available. Due to regulatory reasons, its future availability cannot be guaranteed.Acknowledgements
No acknowledgement found.References
1. Kober T, Marques J, Gruetter R, and Krueger G. Head Motion Detection Using FID Navigators. Magnetic Resonance in Medicine. 2011;66(1):135-143.
2. Mortamet B, Bernstein MA, Jack CR Jr, Gunter JL, Ward C, Britson PJ, Meuli R, Thiran JP, Krueger G, Alzheimer’s Disease Neuroimaging Initiative. Automatic Quality Assessment in Structural Brain Magnetic Resonance Imaging. Magnetic Resonance in Medicine. 2009;62(2):365–372.
3. Lorch B, Vaillant G, Baumgartner C, Bai W, Rueckert D, Maier A. Automated Detection of Motion Artefacts in MR Imaging Using Decision Forests. Journal of Medical Engineering 2017;2017:4501647.
4. Meding K, Loktyushin A, Hirsch M. Automatic detection of motion artifacts in MR images using CNNS. Proc. ICASSP 2017:811–815.
5. Braun S, Chen X, Odry B, Mailhe B, Nadar M. Motion Detection and Quality Assessment of MR images with Deep Convolutional DenseNets. Proc. ISMRM 2018:2715.
6. Van Essen DC, Smith SM, Barch DM, Behrens TE, Yacoub E, Ugurbil K, WU-Minn HCP Consortium. The WU-Minn Human Connectome Project: An overview. NeuroImage 2013;80:62-79.
Figures