4864
Build-a-FLAIR: The synthetic generation of T2-FLAIR contrast from T2-weighted and diffusion metric images through a deep neural network.1Radiology, Medical College of Wisconsin, Milwaukee, WI, United States, 2Neurosurgery, Medical College of Wisconsin, Milwaukee, WI, United States
Synopsis
A deep neural network is presented to synthetically generate T2FLAIR weighted images from other standard neuroimaging acquisitions. Network performance improved with input images that share components with similar physical sources of contrast as the T2FLAIR contrast, while performance was degraded when disparate sources of contrast, like fractional anisotropy, were included. This suggests that a level of feature engineering is appropriate when building deep neural networks to perform style transforms with respect to MRI contrast, with input features containing shared physical sources of contrast with the desired output contrast. In the optimally trained network, pathology present in the acquired T2FLAIR images and not present in the training dataset was correctly reconstructed.
Summary
Preliminary results suggest that synthetic T2-FLAIR contrast can be generated by a deep neural network with input from a combination of T1-, T2-weighted, and diffusion parametric maps. Reduction in this set of input contrasts degrades model performance, likely due to the loss of pertinent physical information. Inclusion of contrasts without direct relationship to T2FLAIR contrast also negatively impact results. A level of feature engineering, based upon the physical principles which yield contrast in MRI, is beneficial when developing deep neural networks for synthetic contrast modulation.Introduction
Applications of deep neural networks to medical imaging have proliferated with the availability of deep learning APIs. In this proliferation, we describe the generation of images with T2FLAIR weighted contrast from other standard neuroimaging contrasts. While other work has shown deep learning style transfers to generate MRI contrast [1,2], this focuses upon the selection of inputs based upon the physical processes that yield MRI contrast.
T2FLAIR contrast is generated through a T2-weighted acquisition with an inversion preparation to null free water. T2-weighted images preserve signal from free water. Diffusion acquisitions include images in which the signal from diffusing water is attenuated, and derived parameters, including mean diffusivity (MD, how freely water diffuses) and fractional anisotropy (FA, how water preferentially diffuses in a given direction).
We hypothesize that T2-weighted, and diffusion metrics contain sufficient information to synthetically generate T2FLAIR images. It is further hypothesized that the addition or subtraction to this core set of contrasts will degrade the generation of synthetic T2FLAIR images.
Methods
Images of controls were acquired as part of a study of sports related concussion. The imaging, performed on a GE Healthcare MR750 with a Nova Medical 32-channel head coil, included anatomical, functional, and structural series for a full scan time of one hour. Here, an MPRAGE (184 sagittal 1mm isotropic resolution , TE 2ms, TR 4700ms, TI 1060ms), T2-weighted Cube (180 sagittal 1mm isotropic resolution, TE 93ms, TR 2505ms, ETL 140), T2FLAIR weighted Cube (180 sagittal 1mm isotropic resolution, TE 118ms, TR 6002ms, TI 1600ms, ETL 230), and diffusion tensor imaging (DTI; 47 sagittal 3mm isotropic resolution, TE 67ms, TR 5250ms, 30 directions b=1000s/mm^2, 30 directions b=2000s/mm^2, ) series were analyzed. All images were converted into NIFTI format. A diffusion tensor model was fit to the DTI acquisition using FSL [3] to yield MD, FA and baseline (not diffusion weighted) maps. All data were registered within the subject using FLIRT [4], and resampled with cubic interpolation to match the resolution of the acquired MPRAGE images using functions in NiBabel.
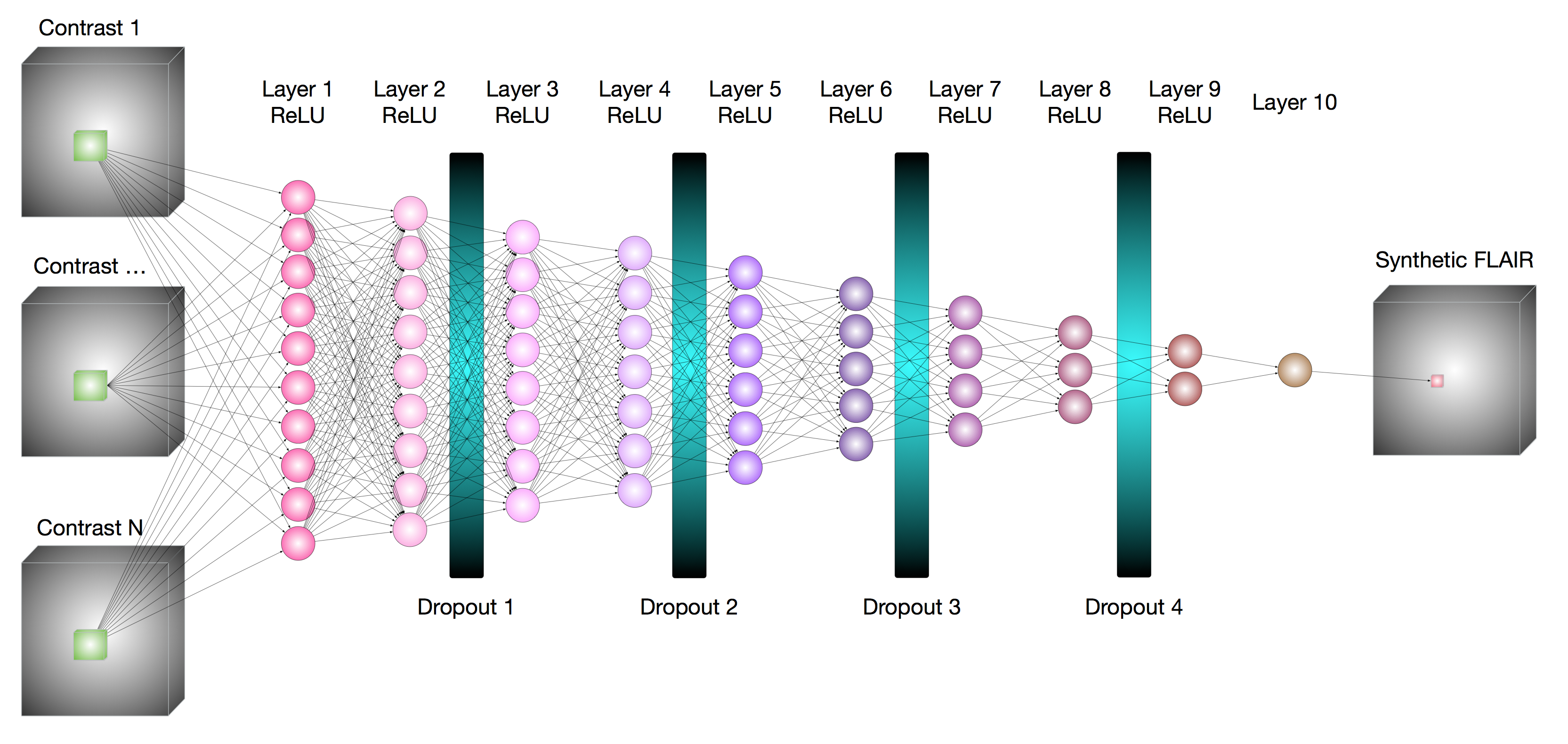
A neural network, shown in Figure 1, was built using PyTorch [4]. Input points were defined by a 3D kernel, which was empirically determined to be 5x5x5 in a compromise of computational time and model performance, around the voxel to be synthesized.
This work includes 13 imaging sessions, with two sessions withheld from training. One session with a white matter hyper-intensity diagnosed on the T2FLAIR image was segregated for final comparison between the synthetically generated images and ground truth--all training images were free from pathology. Another session was reserved for validation of the model during fitting, thereby monitoring the progress and potential over-fitting. From each of the remaining 11 imaging sessions, in each epoch of the training process 2000 voxels were randomly selected from one session for T2FLAIR contrast generation. Training included 500 epochs, and gradients were updated following batches of 100 voxels. The session used for training was randomly selected at each epoch. Model performance was evaluated through the structural similarity index, SSIM, between the generated image and the acquired T2FLAIR image.
Results
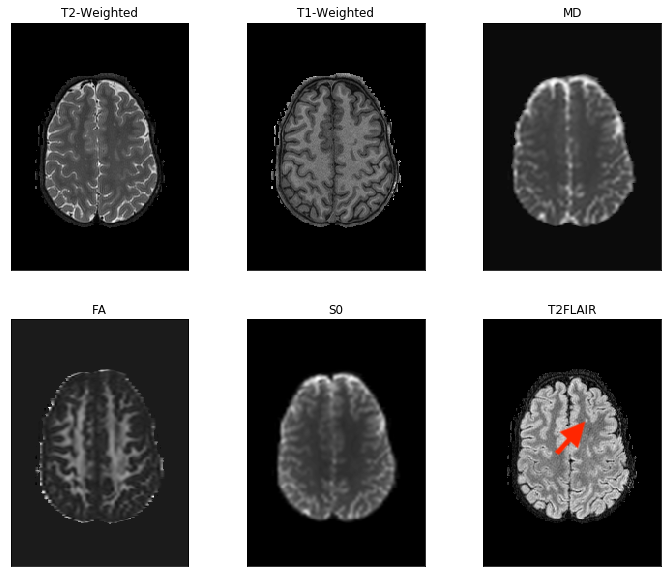
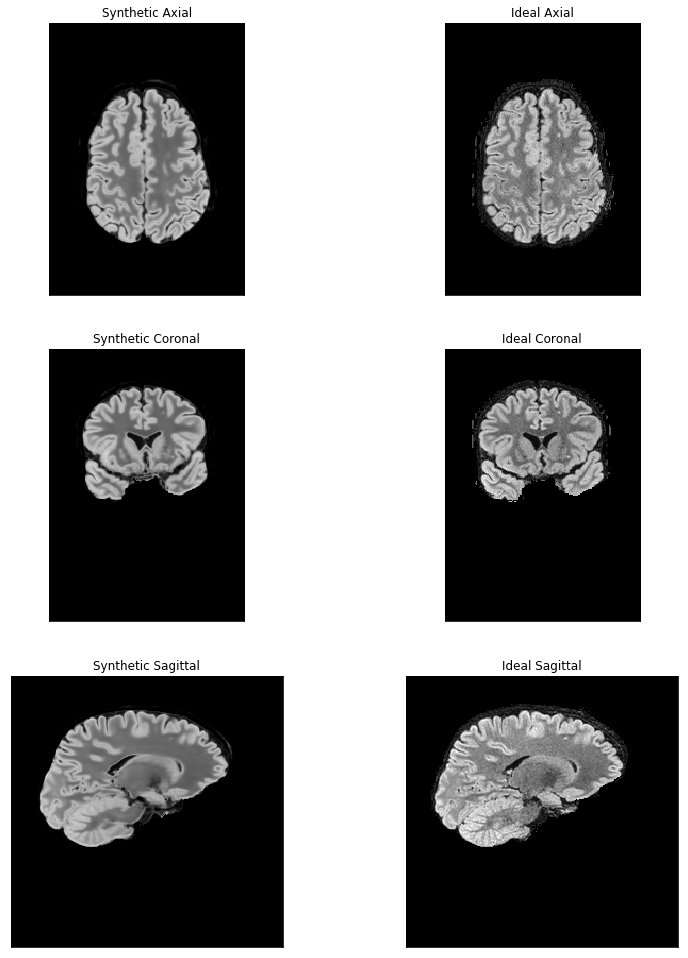
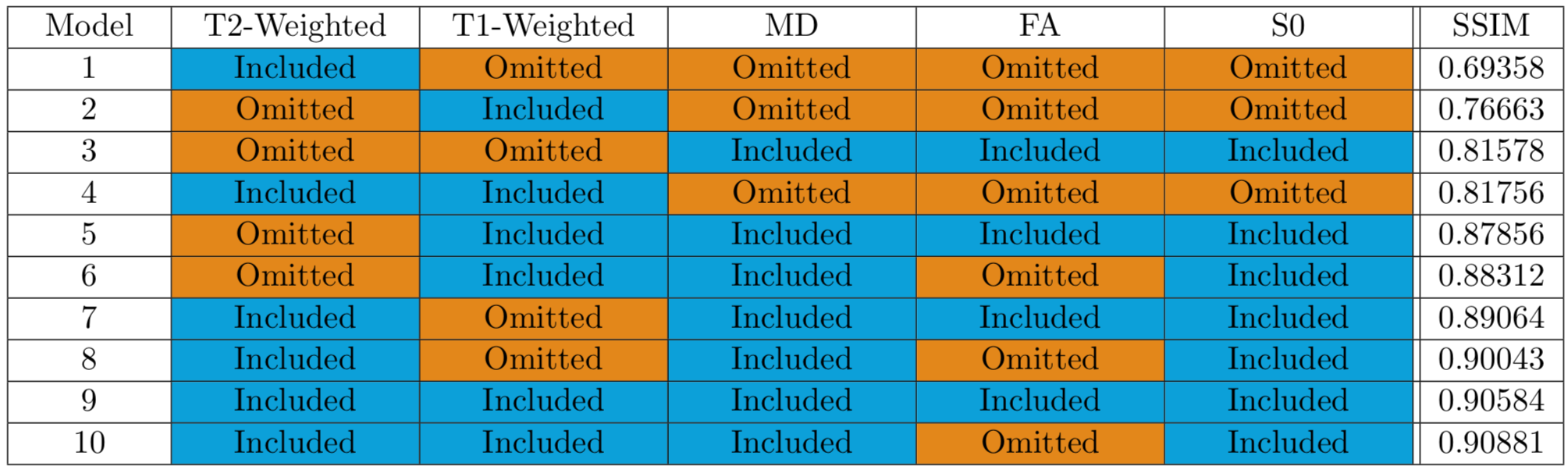
Figure 2 includes images from the dataset with pathology, which was withheld from the training process. A focal white matter hyper-intensity is apparent in the superior frontal lobe. Synthetic T2FLAIR images as well as acquired T2FLAIR images are shown in Figure 3. Figure 4 shows performances of varying Build-A-FLAIR inputs.Discussion & Conclusion
T2FLAIR images were reconstructed from input T1-, T2-weighted, and diffusion metric maps. Although the training set did not include pathologic white matter hyper-intensities, a pathologic hyper-intensity in the validation dataset was correctly reconstructed. Beyond that, with the reconstruction of each voxel based upon the effective application of multiple filters, fit across a number of brain regions and subjects, the reconstructed T2-FLAIR weighted images exhibit a level of de-noising, not unlike non-local means methods [5].
Finally, because T2FLAIR contrast is not based upon the asymmetry of water diffusion, models including FA exhibited poorer performance than those not including FA. While T1-weighted images offer some information which is consistent with T2FLAIR images (free water has a long T1), the inclusion of T1-weighted images offered less benefit than the inclusion of T2-weighted images.
Acknowledgements
This work was supported by the Defense Health Program under the Department of Defense Broad Agency Announcement for Extramural Medical Research through Award No. W81XWH-14-1-0561. Opinions, interpretations, conclusions and recommendations are those of the author and are not necessarily endorsed by the Department of Defense (DHP funds).References
[1] Park, et al. ISMRM 2018: 2794.
[2] Hurley, et al. ISMRM 2018: 2772.
[3] Jenkinson, et al. NeuroImage 62: 782-90 (2012).
[4] Jenkinson, et al. NeuroImage 17: 825-841 (2002).
[5] Baudes, et al. Image Processing On Line, 1: 208-212 (2011).
Figures