4863
Synthesizing T2 Maps from Morphological OAI Scans Using Conditional GANs and a Split U-Net1Martinos Center, Massachusetts General Hospital, Charlestown, MA, United States, 2Harvard Medical School, Boston, MA, United States, 3Physics, Harvard University, Cambridge, MA, United States, 4Stanford University, Stanford, CA, United States
Synopsis
We explore the feasibility of artificially adding an exam to an MRI scan protocol by synthesizing the desired exam from the acquired images. To achieve this, we both use a normal U-Net as well as a modified U-Net structure, which takes advantage of prior information of which exams of the protocol are most relevant to the high-resolution and low-resolution components of the desired contrast. We demonstrate results based on synthesizing T2 relaxation time maps using imaging data obtained from the Osteoarthritis Initiative.
Introduction
MRI scan protocols usually involve several scans of the same anatomy with different contrast. Often, due to time constraints, not all desired scans can be fit into the protocol. As an example, in the Osteoarthritis Initiative (OAI), 12 minute long MESE T2 maps were only acquired in the right knee to save time1. However, all the scans share information through the Bloch equations and common tissue parameters. Given enough training data, a neural network may learn to predict the missing scan from the acquired data. This way, more information can be achieved from the protocol, or the protocol can be shortened without losing information.Methods
The dataset used consisted of in-vivo sagittal double-echo in steady-state (DESS), turbo-spin echo (TSE), and multi-echo spin-echo (MESE) scan data from the OAI. The data was automatically resampled and adjusted so that the FOV and sampling matrix of the DESS and TSE scans were the same as for the MESE scans. T2 maps were automatically computed from the MESE scans with an exponential fit and used as target images for the network to produce, with DESS and TSE scans as input.
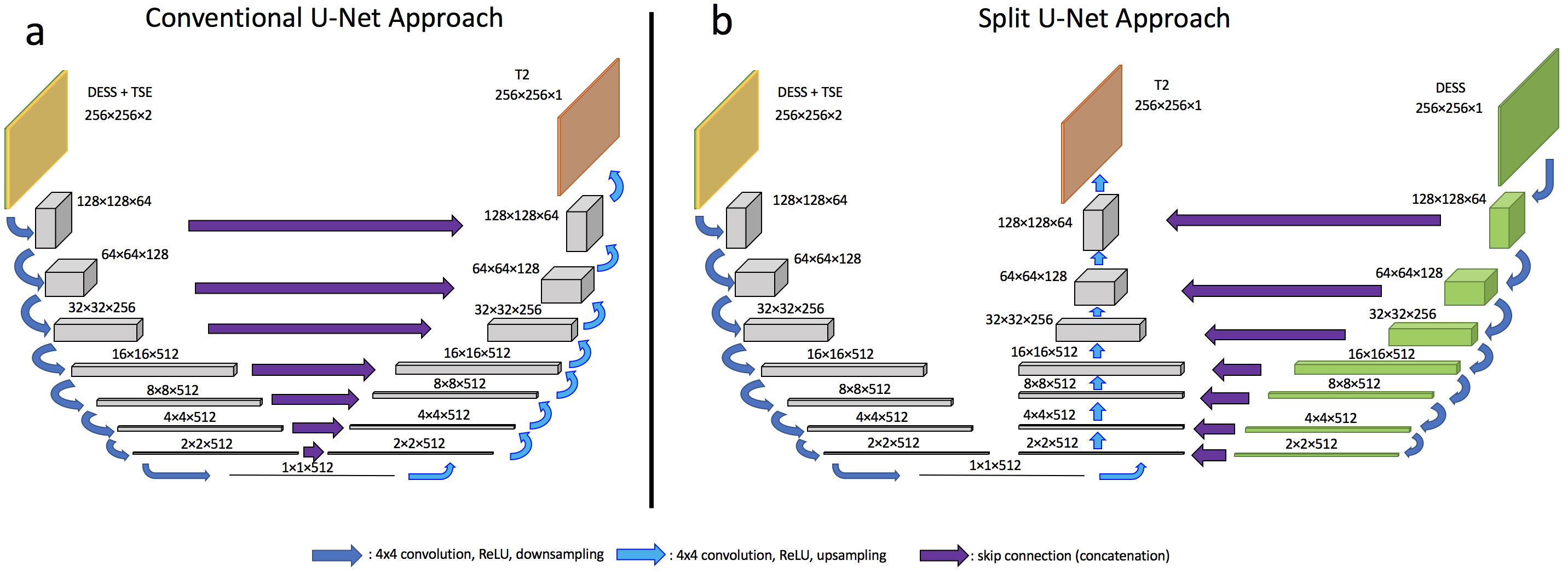
For the network architecture, we used a conditional GAN approach2, inspired by the Pix2Pix methodology3. For the discriminator, we used a patchGAN structure. For the generator, the MRI sequences were inserted as image channels to a U-Net4. In the standard U-Net, skip connections between downsampling and upsampling layers provide high-resolution information for reconstruction. In our case, we have the additional prior information that the DESS scan is most relevant for the high-resolution structure of the MESE maps, as it has thinner slices (being 3D) than other sagittal scans in the protocol, resulting in less partial voluming. Therefore, we explored a split U-Net architecture as shown in Figure 1. The left pathway takes in the DESS and TSE scans as two channels and performs convolution and pooling operations that downsample to a bottleneck layer and then upsample again through the middle pathway, like a conventional encoder-decoder. The right pathway includes only the DESS channel and is used only for the skip connections. This is equivalent to weighted skip connections in a conventional U-Net, with the TSE channel weight forced to 0. The results were compared to those with a regular U-Net.
Scans from 100 subjects, comprising 2722 slices, were used for training over 200 epochs with random shifting and mirroring applied at each epoch, taking roughly 24 hours to train, on two NVIDIA Pascal-architecture GTX 1080 Ti’s (11 GB GPU RAM each). The trained networks were then tested on 281 images from 10 subjects. Due to normalization, the results are not in milliseconds, but the relative comparison between the reference T2 map and synthesized map is still valid as they have the same scale.
Results
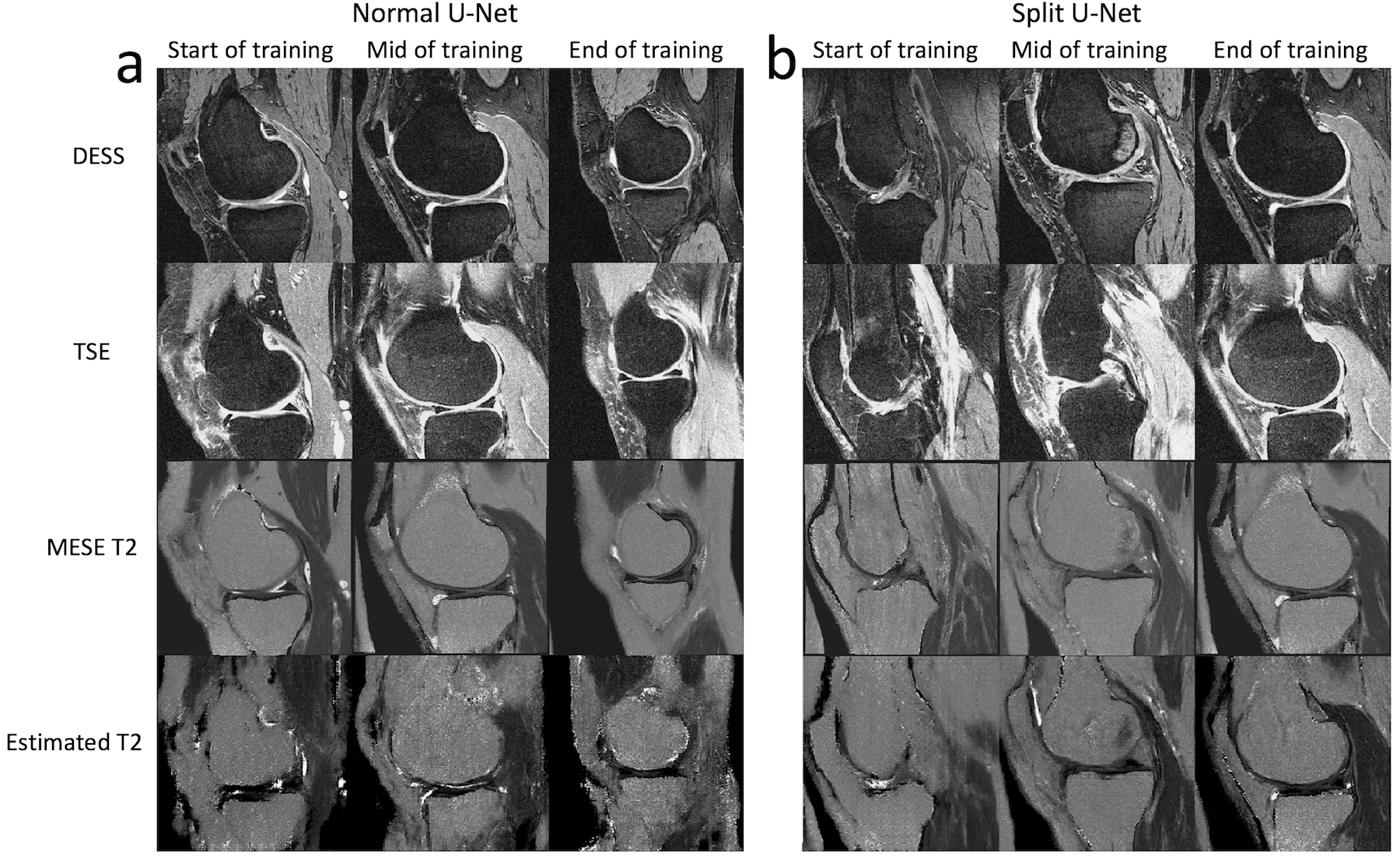
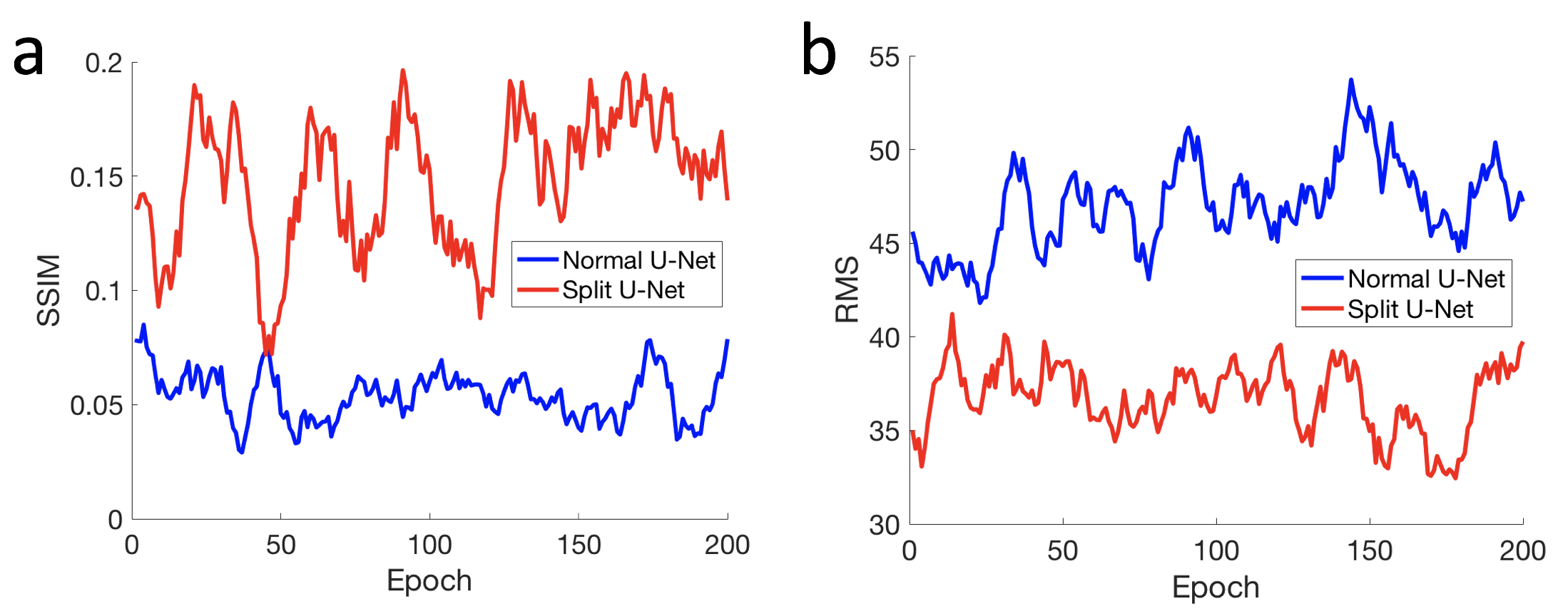
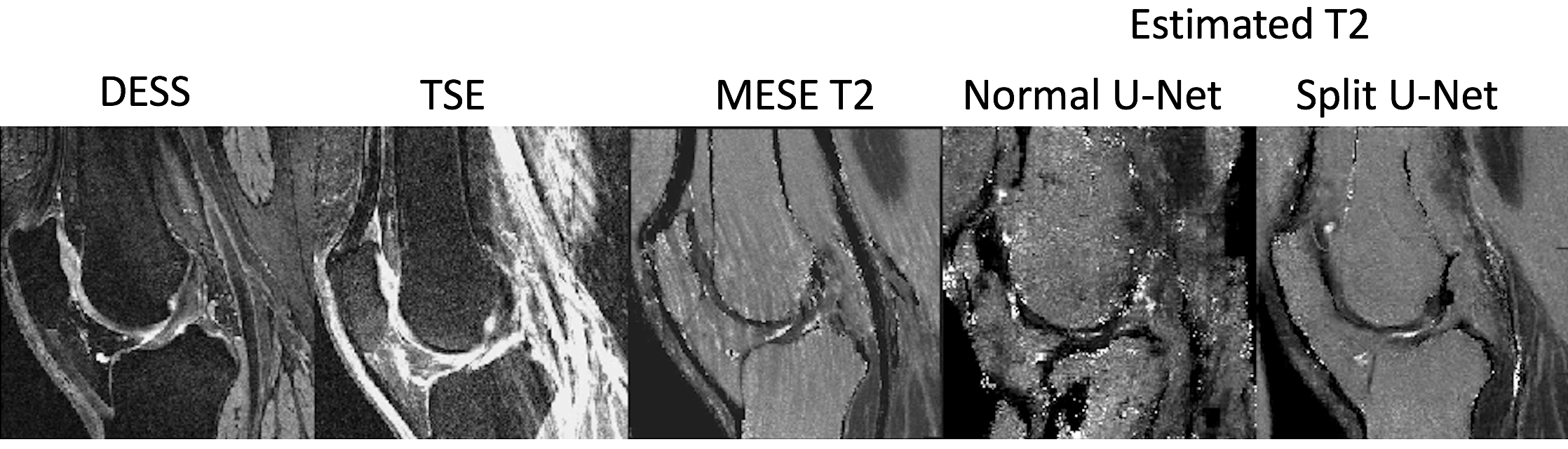
Sample images are shown in Figure 2 at the beginning, middle, and end of training for the two network architectures. The images show the results not changing much for either network through the training, but the results from the modified U-Net visually seem better. This is also demonstrated in Figure 3, which shows the structural similarity index (SSIM) and root-mean-square (RMS) between the MESE map and the synthesized map for the two approaches over the epochs. The modified network gives higher SSIM and lower RMS. Results from the test dataset, shown in Table 1, give similar results. As shown in Figure 4, the method can also give less imaging artifacts than the acquired MESE T2 map.Discussion
Our GAN enforces the generator to arise from a plausible distribution of training data samples, yielding high-quality results. The split U-Net likely performs better since it’s not oversaturating the network with high resolution detail, helping the GAN parameterize the training data distributions better. While the split U-Net has shown superior performance to the conventional U-Net for our application, the important result is that a neural network can be trained to predict a scan missing from an MRI protocol from acquired data. For example, T2 maps in the left knee in the OAI could be synthesized, saving about 12 minutes per patient. This could result in shorter scanning protocols to the benefit of patients, researchers, clinicians, and medical payers. In the future, these promising results will be further improved. More scans from the OAI can be used as input data and the T2 values will be scaled back to yield maps in milliseconds.Conclusion
A neural network architecture with cGANs and a modified U-Net can be used to synthesize a scan missing from a scan protocol.Acknowledgements
DARPA 2016D006054References
[1] Peterfy et al. The osteoarthritis initiative: report on the design rationale for the magnetic resonance imaging protocol for the knee. Osteoarthritis and Cartilage, 2008; 16: 1433-1441. [2] Goodfellow et al. Generative adversarial nets. In Advances in neural information processing systems, 2014: 2672-2680. [3] Isola et al. Image-to-image translation with conditional adversarial networks. arXiv 2017. [4] Ronneberger et al. U-net: Convolutional networks for biomedical image segmentation. In International Conference on Medical image computing and computer-assisted intervention, 2015: 234-241.Figures