4848
Reinforcement Learning for Automated Reference-free MR Image Quality Assessment1Diagnostic and Interventional Radiology, University Hospital of Tuebingen, Tübingen, Germany, 2Institute of Signal Processing and System Theory, University of Stuttgart, Stuttgart, Germany, 3School of Biomedical Engineering and Imaging Sciences, King's College London/St Thomas' Hospital, London, United Kingdom
Synopsis
Reinforcement learning is a method aiming to model a learner similar to human learning behavior. In this study, we investigate the possibility to utilize this technique to select an optimal feature set for automated reference-free MR image quality assessment. In our proposed setup, we use Q-learning and a random forest classifier to provide feedback to the learner. Moreover, we investigate a combination of multiple reinforcement learning models. Results show that our random-forest-based reinforcement learning setup can achieve higher accuracies than the previously used support vector machines or feature-based deep neural networks combined with traditional feature reduction like PCA.
Introduction
Nowadays, MR imaging is routinely used as a crucial tool in clincal diagnostics. Due to the long acquisition times and various technical or patient-related factors, MR images are prone to artifacts and subsequent degradation of image quality. How well radiologists can perform a diagnosis strongly depends on the quality of the acquired images, making image quality assessment an important task. Since manual assessment is time consuming, especially for large amounts of acquired data (e.g. epidemiological studies like the German NAKO1), we proposed an automated reference-free approach using Support Vector Machines (SVM) or Deep Neural Networks (DNN), including techniques like active learning to reduce the high labeling effort2-5.
To further improve the achieved classification accuracy of 91.2%/92.5% (SVM/DNN), we focused our research on the selection of the right subset of features we extracted from MR images. Having used principal component analysis in previous studies, we now investigate the possibility of using reinforcement learning6 (RL) to select the best features for our task. This method is based on behavioral psychology and models a software agent who learns by interacting with and getting feedback from an environment, trying to take actions which maximize a reward (Figure 1).
In this study, we investigate a combination of reinforcement learning
with random forest classification to select the best features for
training the classifier on our data set. Furthermore, we propose a
strategy of
multi-model
reinforcement learning (MRL) to further increase and stabilize
classifier performance. In contrast to multi-agent reinforcement
learning techniques commonly used in data science7, we do
not train our system with multiple agents, but train one-agent
systems independently and merge their results after the training is
completed. To the best of our knowledge, this approach has not been used for automated assessment of image quality before.
Methods
Our data set consists of 100 3D images acquired from 100 patients and healthy volunteers, resulting in a total of 2911 2D slices we used for training and evaluation. Experienced radiologists were asked to rate the images according to perceived image quality on a 5-point Likert scale. Using ImFEATbox8, we extracted Nf = 5543 image features (GLCM, run length, LBP, fractal dimension, gradient-based and Zernike features). To get more robust results, we randomly split the data set 5 times in training (70%) and evaluation (30%) samples and used the mean accuracy of the 5 data sets as final result.
Random forest (RF) is a machine learning method based on decision trees9,10 . It relies on the combination of the training results of an ensemble of decision trees which are trained with different feature subsets. In this study, RFs are used to provide the feedback from the environment in the reinforcement learning setup in form of the accuracies. The general setup of our RL system is depicted in Figure 2.
We use Q-learning6, i.e. which action is taken by the agent is determined by the Q-function which describes the value of an action a in state s. These values are stored in the Q table and updated each iteration based on the gained reward rn.
The final decision is determined by the $$$\epsilon$$$-policy6, which gives the probability that action a is chosen in state s and ensures explorative behaviour of the agent.
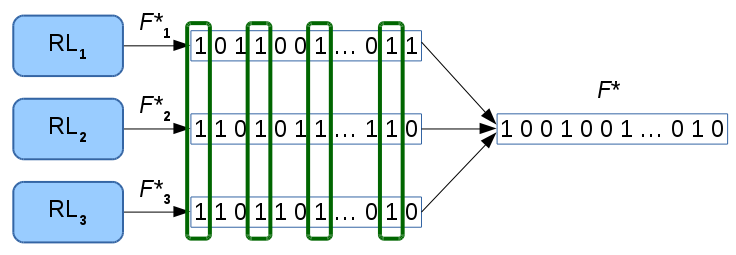
Since the results of RL were less stable than when training an RF with the full feature set and still needed a high number of features, we additionally explored MRL (Figure 3).
Results
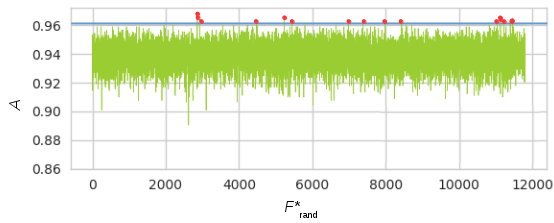
Results for the training of a random forest classifier with reinforcement learning and multi reinforcement learning are given in Figure 4. Figure 5 exemplarily shows the superiority of the proposed MRL approach compared to 11800 randomly selected feature subsets F*rand of size Nf*,opt,MRL. Over all 5 data sets used for training, only an average of 13 ( 0.11%) of the 11800 random feature sets yielded slightly better results than MRL.Discussion
In this study, we were able to increase classifier performance compared to previous studies. The utilization of RF as classifier increases classifier performance by 4.1%/2.9% compared to SVM/DNN, respectively. While the results for RF with RL were slightly lower than without, with MRL we were able to achieve a higher accuracy, resulting in an increase of 6.6%/5.1% to SVM/DNN. A possible drawback of the proposed method is that, due to its iterative nature, it increases computational effort compared to our previously used methods.Conclusion
The
utilization of RL, especially MRL, yields promising results for automated MR IQA. Additionally, we found that RF are better suited
classifiers for this task than the previously used SVM/DNN.Acknowledgements
No acknowledgement found.References
1. F. Bamberg , H.-U. Kauczor, S. Weckbach, C. L. Schlett, M. Forsting, S.C. Ladd, K. H. Greiser, M.-A. Weber, J. Schulz-Menger, T. Niendorf, T. Pischon, S. Caspers, K. Amunts, K. Berger, R. Bülow, N. Hosten, K. Hegenscheid, T. Kröncke, J. Linseisen, M. Günther, J. G. Hirsch, A. Köhn, T. Hendel, H.-E. Wichmann, B. Schmidt, K.-H. Jöckel, W. Hoffmann, R. Kaaks, M. F. Reiser, H. Völzke, For the German National Cohort MRI Study Investigators: “Whole-body MR imaging in the German national cohort: rationale, design, and technical background. Radiology 277(1):206–220, May 2015
2. T. Küstner, P. Bahar, C. Würslin, S. Gatidis, P. Martirosian, NF. Schwenzer, H. Schmidt and B. Yang: "A new approach for automatic image quality assessment", Proceedings of the Annual Meeting ISMRM 2015, June 2015, Toronto, Canada.
3. T. Küstner, S. Gatidis, A. Liebgott, M. Schwartz, L. Mauch, P. Martirosian, H. Schmidt, N. Schwenzer, K. Nikolaou, F. Bamberg, B. Yang and F. Schick: “A machine-learning framework for automatic reference-free quality assessment in MRI”, Magnetic Resonance Imaging, 53, 134 - 147, 2018. doi: https://doi.org/10.1016/j.mri.2018.07.003
4. A. Liebgott, T. Küstner, S. Gatidis, F. Schick an B. Yang: "Active Learning for Magnetic Resonance Image Quality Assessment", Proceedings of the 41th IEEE International Conference on Acoustics, Speech and Signal Processing ICASSP 2016, March 2016, Shanghai, China.
5. A. Liebgott, D. Boborzi, S. Gatidis, F. Schick, K. Nikolaou, B. Yang and T. Küstner: "Active learning for automated reference-free MR image quality assessment: analysis of the influence of intra-batch redundancy on the number of required training samples", Proceedings of the Joint Annual Meeting ISMRM-ESMRMB 2018, June 2018, Paris, France.
6. R. S. Sutton, A. G. Barto: “Reinforcement Learning: An Introduction.” MIT Press, 1998.
7. L. Buşoniu, R. Babuška and B. De Schutter: “Multi-agent reinforcement learning: An overview.” Innovations in Multi-Agent Systems and Applications – 1, chapter 7, vol. 310 of Studies in Computational Intelligence, Berlin, Germany: Springer, pp. 183–221, 2010.
8. A. Liebgott, T. Küstner, H. Strohmeier, T. Hepp, P. Mangold, P. Martirosian, F. Bamberg, K. Nikolaou, B. Yang and S. Gatidis: “ImFEATbox: a toolbox for extraction and analysis of medical image features”, International Journal of Computer Assisted Radiology and Surgery, Sep 2018. Springer Verlag, ISSN 1861-6429. doi: https://doi.org/10.1007/s11548-018-1859-7
9. T. K. Ho: “Random Decision Forests”, Proceedings of the 3rd International Conference on Document Analysis and Recognition, Montreal, QC, 14–16 August 1995, pp. 278–282.
10. L. Breiman: “Random forests,” Machine learning, Bd. 45, Nr. 1, S. 5–32, 2001. doi: https://doi.org/10.1023/A:1010933404324
Figures