4839
3D Model-Based Parameter Quantification on Resource Constrained Hardware using Double-Buffering1Institute of Medical Engineering, Graz University of Technology, Graz, Austria, 2Institute of Mathematics and Scientific Computing, University of Graz, Graz, Austria, 3Biotechmed, Graz, Austria
Synopsis
Reconstructing 3D parameter maps of huge volumes entirely on the GPU is highly desirable due to the offered computation speed-up. However, GPU memory restrictions limit the coverable volume. To overcome this limitation, a double-buffering strategy in combination with model-based parameter quantification and 3D-TGV regularization is proposed. This combination warrants whole volume reconstruction while maintaining the speed advantages of GPU-based computation. In contrast to sequential transfers, double-buffering splits the volume into blocks and overlaps memory transfer and kernel execution concurrently, hiding memory latency. The proposed method is able to reconstruct arbitrary large volumes within 5.3 min/slice, even on a single GPU.
Introduction
Scan time reduction of MR parameter quantification with model-based reconstruction1,2,3,4,5 usually involves iterative optimization techniques. Computationally this leads to long reconstruction times coupled with possibly huge memory requirements. Recently, GPU acceleration for model-based reconstruction from highly subsampled data acquisition was proposed3,4,5. These approaches suffer from memory limitations of the available GPUs and are thus applied slice-by-slice in 2D3,4 or on small volumes5. The aim of the present work is to overcome memory limitations by making use of double-buffering6 which enables reconstruction of arbitrarilly large volumes on even a GPU. Double-buffering was recently applied to the non-uniform FFT (NUFFT)7. Here, we extend this approach to accelerate computation of a complete iterative reconstruction problem, i.e. a previously developed iteratively regularized Gauss-Newton (IRGN) algorithm for 3D T1-mapping from accelerated golden-angle radial-stack-of-stars data using total-generalized-variation (TGV) constraints5. For evaluation purposes the reconstruction times and accordances in image quality of the proposed strategy are compared against the unoptimized reconstruction. The proposed algorithm is implemented in Python/PyOpenCL8 and is therefore platform independent.Methods
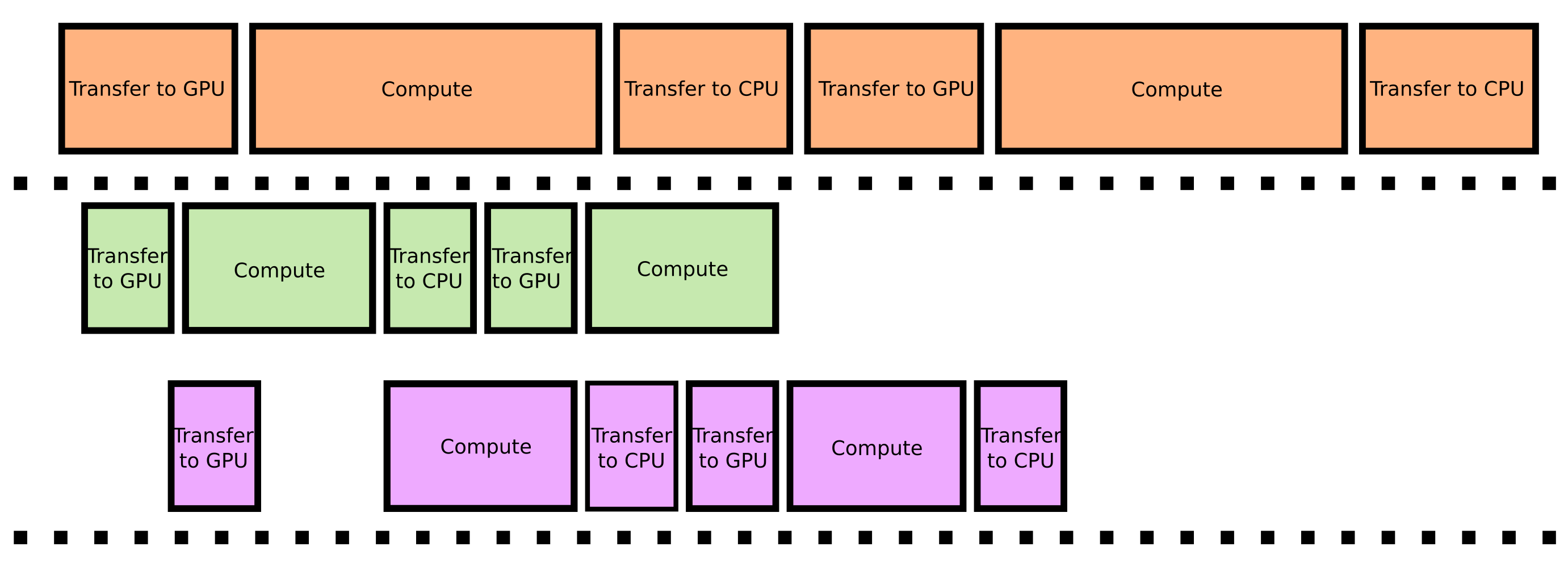
Double-buffering requires the separability of the involved operations, NUFFT and 3D TGV regularization, into blocks that fit in GPU memory. For 3D stack-of-stars data this can be achieved by a splitting in fully sampled slice direction. The NUFFT is applied to blocks of k-space and the regularization in parameter space can be exactly computed if an overlap of one slice is used and the correct boundary conditions are met. Synchronization in CPU memory is necessary in each iteration but would lead to severe performance degradation due to memory bandwidth restrictions. Double-buffering utilizes the independent copy and compute engines of recent GPUs to overlap transfer from CPU to the GPU memory with the execution of specific computation kernels (see scheme in Figure 1). Thus, the required synchronization in every iteration can be hidden behind computation of NUFFT and finite differences operations. To demonstrate the equality of the double-buffering based 3D reconstruction to conventional reconstruction on the GPU5 a PyOpenCL implementation is used to mitigate possible differences between CUDA and OpenCL. Parameter maps of ten central slices of a full brain VFA data set are reconstructed with both methods and compared by means of a pixel-by-pixel relative error. For double-buffering, a block size of five was chosen but could have been as small as one slice and as large as GPU memory permits. Further, a rough benchmark of the proposed, the OpenCL implementation, and the original algorithm5 based on the gpuNUFFT9 is performed. Last, reconstruction of the full brain data set using the proposed algorithm with a block size of ten is shown. All reconstructions are done on a desktop PC equipped with a Nvidia GTX 1080 Ti using OpenCL 1.2 and CUDA 9 and with the preprocessing and B1 correction steps10 described previously5.Results
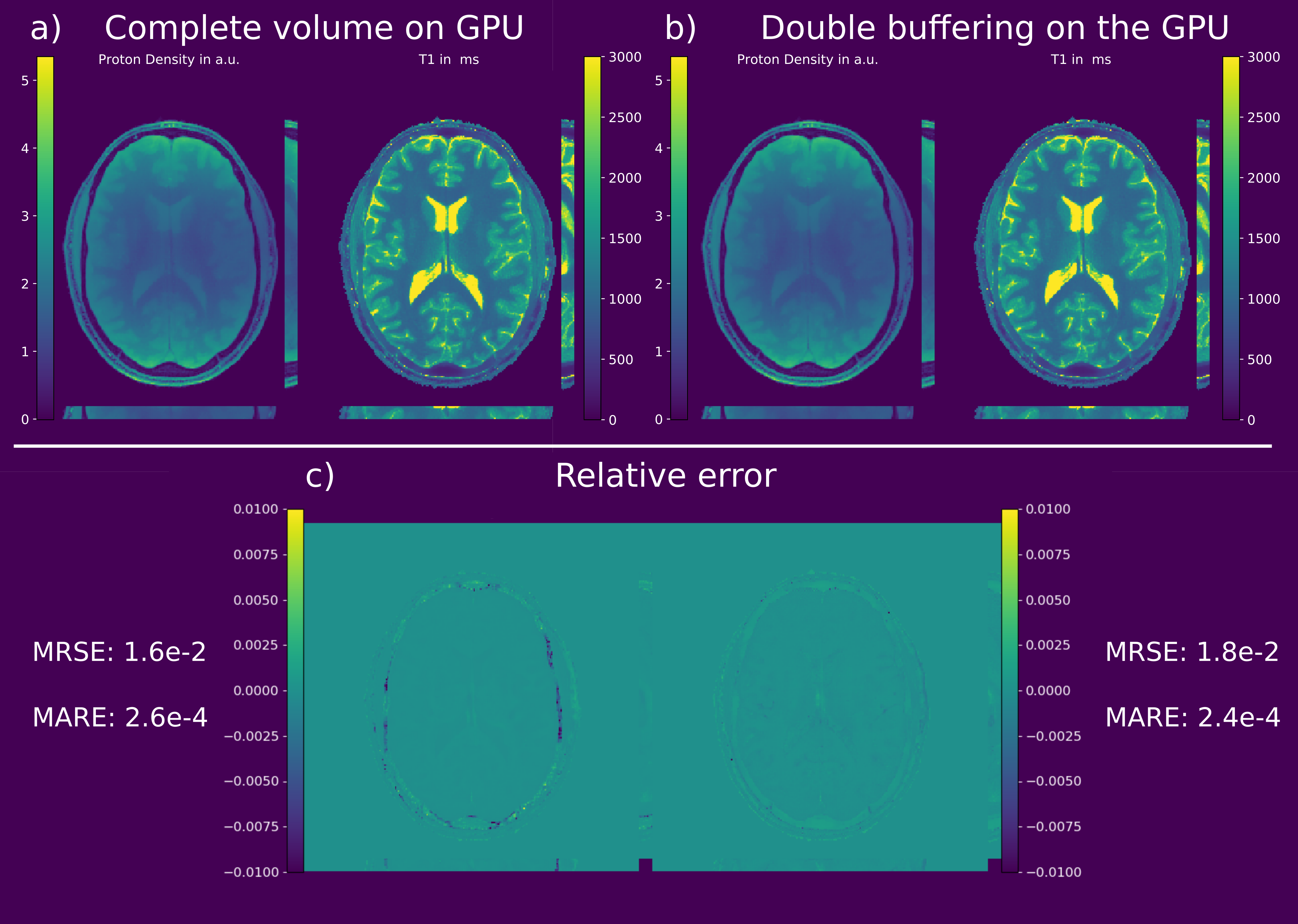
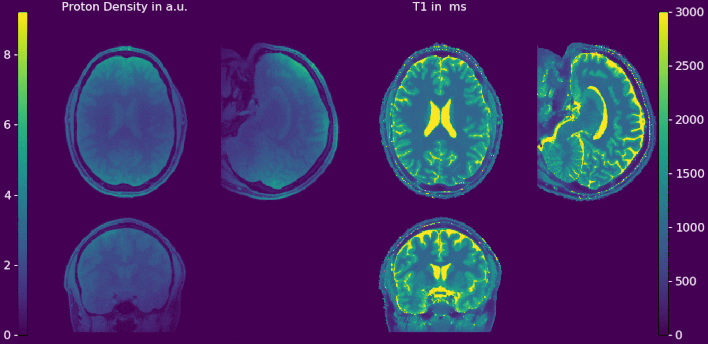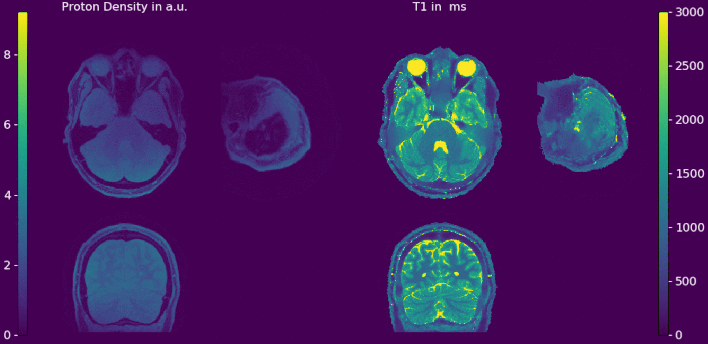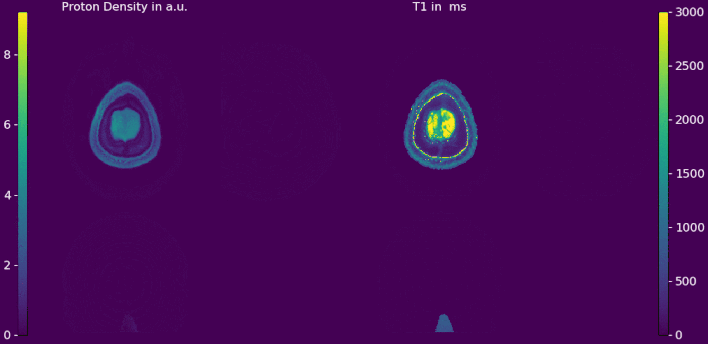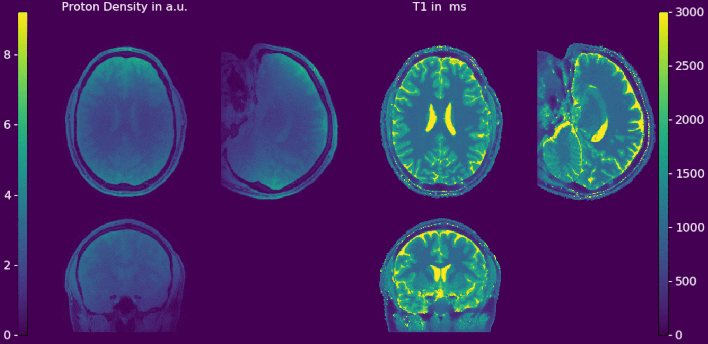
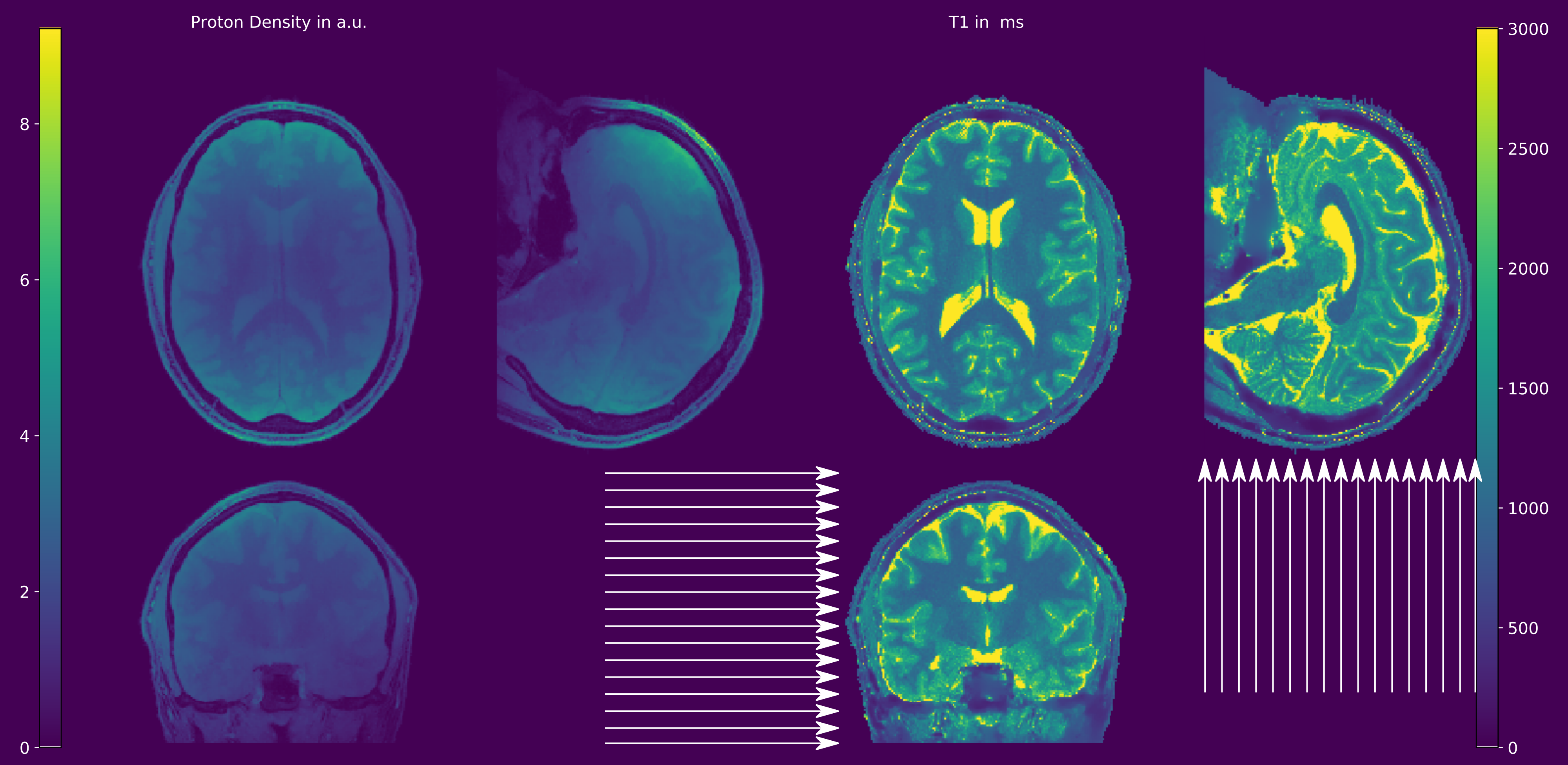
Double-buffering yields results with numerically neglectable differences compared to 3D regularization on the whole volume (Figure 2a and 2b). The relative error between the proposed strategy and a standard reconstruction is shown in Figure 2c. After 12 iterations only small deviations can be observed at the skull. No edges or deviations are visible at block boundaries. Computation time of the double-buffered reconstruction is twice as fast as the gpuNUFFT9 based algorithm but 1.5 times longer than OpenCL with a single transfer (Table 1). Full brain T1 and pseudo proton density maps are shown in Figure 3 and 4. Again, no boundaries between the individual blocks are visible. Without streaming reconstruction requires 34 GB of memory, three times the size of available GPU memory, and would take 8.7 h/slice days on the CPU. The proposed strategy reduces reconstruction time to 5.3 min/slice and takes just 4.7 GB of GPU memory.Discussion
The similarity of the blocked scheme to standard reconstruction after 12 Gauss-Newton iterations supports numerical accuracy of both methods. Considering the amount of iterations, 3300 in total, the observed differences are negligible and are due to propagation of numerical inaccuracies throughout iterations. Increase in reconstruction time (Table 1) stems from not perfectly hidden memory transfers behind computations. Reconstruction time could be further improved by modifying the gridding process7. No errors or boundary effects in block direction are visible within the whole volume .Conclusion
With the proposed reconstruction framework using double-buffering a drastic decrease in reconstruction time could be achieved. Reconstruction time of the investigated model-based reconstruction framework for isotropic whole-brain T1-mapping from accelerated RAVE-VFA data could be reduced from 8.7 h/slice (CPU) to 5.3 min/slice. Additionally, the Python/PyOpenCL implementation is independent of the given platform and facilitates the applicability even on resource constrained hardware.Acknowledgements
This work is funded and supported by the Austrian Science Fund (FWF) under grant “SFB F32‐N18” (SFB “Mathematical Optimization and Applications in Biomedical Sciences”); NVIDIA Corporation Hardware grant support; Oliver Maier is a Recipient of a DOC Fellowship (24966) of the Austrian Academy of Sciences at the Institute for Medical Engineering at TU Graz.
References
1. Block KT, Uecker M, Frahm J. Model-Based Iterative Reconstruction for Radial Fast Spin-Echo MRI. IEEE Traansactions on Medical Imaging, Vol. 28, No. 11, November 2009
2. Sumpf TJ, Uecker M, Boretius S, Frahm J. Model-based nonlinear inverse reconstruction for T2 mapping using highly undersampled spin-echo MRI. J Magn Reson Imag 2011; 34(2):420–428
3. Roeloffs, V. , Wang, X. , Sumpf, T. J., Untenberger, M. , Voit, D. and Frahm, J. (2016), Model‐based reconstruction for T1 mapping using single‐shot inversion‐recovery radial FLASH. Int. J. Imaging Syst. Technol., 26: 254-263. doi:10.1002/ima.22196
4. Wang, X. , Roeloffs, V. , Klosowski, J. , Tan, Z. , Voit, D. , Uecker, M. and Frahm, J. (2018), Model‐based T1 mapping with sparsity constraints using single‐shot inversion‐recovery radial FLASH. Magn. Reson. Med, 79: 730-740. doi:10.1002/mrm.26726
5. Maier O., Schoormans J., Schloegl M., et al. Rapid T1 quantification from high resolution 3D data with model‐based reconstruction. Magn Reson Med. 2018;00:1–18. DOI: 10.1002/mrm.27502
6. Harris M. How to Overlap Data Transfers in CUDA C/C++. https://devblogs.nvidia.com/how-overlap-data-transfers-cuda-cc/#disqus_thread. Website accessed on 31.10.2018
7. Smith DS, Sengupata S, Smith SA, Welch EB. Trajectory optimized NUFFT: Faster non‐Cartesian MRI reconstruction through prior knowledge and parallel architectures. Magn Reson Med 2018; DOI: 10.1002/mrm.27497
8. Klöckner A, Pinto N, Lee Y, Catanzaro B, Ivanov P, Fasih A. PyCUDA and PyOpenCL: A scripting-based approach to GPU run-time code generation. Parallel Computing 2012; 38: 157-174.
9. Knoll, F.; Schwarzl, A,; Diwoky, C.; Sodickson DK.: gpuNUFFT - An Open-Source GPU Library for 3D Gridding with Direct Matlab Interface. Proc ISMRM p4297 (2014).
10. Lesch A, Schloegl M, Holler M, et al. RUltrafast 3D Bloch‐Siegert B+1‐mapping using variational modeling. Magn Reson Med. 2008. doi:10.1002/mrm.27434.
Figures