4833
MR Research in the cloud - preliminary results at Columbia University1Flywheel, Cambridge, MA, United States, 2Columbia University MR Research Center (CMRRC), Columbia University, New York, NY, United States
Synopsis
MR researchers are challenged with managing large data sets, scaling complex computational analyses, and supporting cross-functional collaboration. To tackle these challenges, Columbia University has fully integrated their data management and processing in the cloud to take advantage of high-performance yet low-cost storage, scalable on-demand compute resources, and secure regulatory-compliant infrastructure for sharing of data and algorithms. The result is a platform that has enabled more efficient workflows, greater productivity, and multi-site collaboration.
Motivation
Although significant investments have been made in the time, effort and technology required to acquire MR data for diagnostics and biomedical research, less attention has been given to capturing, archiving, analyzing, interpreting and sharing this valuable data resource. Researchers are challenged by managing large data volumes, computationally intensive analyses, and the need to share this data through collaboration inter or intra-institutional [1]. Providing a computational environment in which these algorithms can run reliably with current and previously acquired data has also become more complicated, challenging the quality and continuity of lab output. More efficient and effective scientific data management is needed to increase scientific productivity. In this abstract, we present how Columbia University’s Zuckerman Institute (ZI) has met these challenges. The ZI now automatically captures all MR data and stores it (with tertiary data) in the cloud to take advantage of long-term data archiving and scalable, on-demand computation. This data is made available through a managed access for all investigators to use for the parent experimental and for progenic virtual studies, retrieved, analyzed and interpreted by custom algorithms also located on the same cloud instance. The methods for this strategy are presented below.Methods
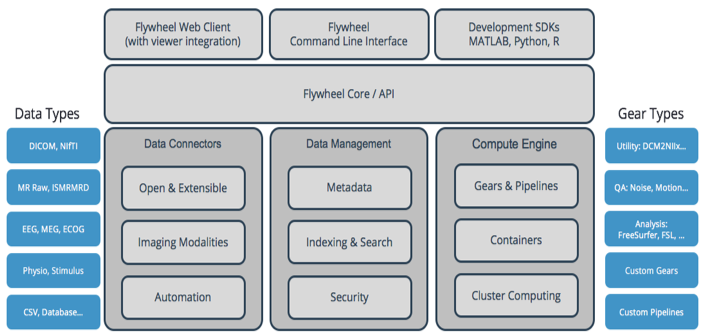
MR researchers at Columbia have adopted data management and analysis platform, Flywheel [2], which is integrated and hosted on Google’s Cloud Platform (GCP)[3]. Flywheel, a third-party software platform, integrates directly with the two (2) Siemens 3 Tesla Prisma MR scanners and Bruker 9.4 Tesla animal scanner at the ZI to capture data, such that data is imported from the scanner without user intervention (data tagged on the console is automatically sorted and organized when it lands in platform). Data is analyzed for pre- and post-processing within this platform on GCP using containerized algorithms, known as “Gears”. The aforementioned Gears are encapsulated computing environments that leverage Linux containers which completely isolate the necessary computation stack, removing the need to manage dependencies across disparate libraries and algorithms. The Gears at the ZI were provided by the platform or custom built by the researchers (description of Flywheel’s architecture is seen in Fig. 1).Results
The following data and computation workflow have been implemented at ZI:
· Data connectors are configured to communicate directly with the two Siemens scanners and one Bruker scanner to automatically “pull” data into a Flywheel instance on the GCP.
· Routine pre-processing Gears, Quality Assurance (QA) and data conversion gears such as DICOM files to the NIfTI file format, are automatically triggered once data enters the platform. The QA algorithms provide information such as SNR, motion, and spikes for that particular acquisition.
· Data in the platform is viewed and downloaded using a web app, or command-line-interface (CLI) tool, or various language-specific software development kits (SDKs). Data can also be securely shared outside of the institution. Currently, Columbia researchers collaborate (share data, algorithms, files) with 12 external institutions using the platform.
· The Compute Engine allows the use of Gears or creation of their own. The Gears consist of algorithms ranging from Quantitative Susceptibility Mapping (QSM) [4] to commonly used software packages used for image and statistical analysis. Custom Gears are versioned and given supporting meta-data such as author, maintainer, and description. Multiple Gears reside in the Core and interact with each other to create additional Gears. Today, researchers can run up to 50 concurrent gears on the cloud with scalable virtual machine (VM) deployment. Since July 2017, over 150,000 gears have been run by researchers at ZI. More statistics on research at Columbia is seen in Table 1.
· Data on the platform can be searched, and isolated as a sub-group referred to as a collection. After QA analysis, the data can be labelled manually or via SDK to generate a “learning” data set. With the platform’s API, neural network algorithms can access the isolated data to perform AI/machine learning and leverage scalable compute on the cloud.
Discussion and Conclusion
The acquisition, archiving, sharing, and analysis schema described herein meet the requirement of ZI’s scientific data management network. Automatic data capture and analysis have led to reproducible data pre-processing. By employing the container technology described, researcher’s data and custom applications reside on the platform and are fully deployed on the cloud to leverage scalable computation and long-term archiving. Finally, data, algorithms and analysis are shared through a distributed network to support and promote collaboration.Acknowledgements
No acknowledgement found.References
[1] B. Wandell, et. al, Data management to support reproducible research. ARXIV, Quantitative Biology – Quantitative Methods, Bibliographic Code: 2015arXiv150206900W,[2] https://flywheel.io/, [3]https://cloud.google.com/, [4]C. Liu,"Susceptibility tensor imaging," MRM, vol. 63, no. 6, pp. 1471--1477, 2010.Figures