4813
Relevance-guided Feature Extraction for Alzheimer's Disease Classification1Department of Neurology, Medical University of Graz, Graz, Austria
Synopsis
Using FLAIR images we separated Alzheimer's patients (n=106) from controls (n=173) by using a deep convolutional neural network and found that the classifier might learn irrelevant features e.g. outside the brain. Preprocessing of MRI plays a crucial but often neglected role in classification and therefore we have developed a method enforcing the relevant features to be within brain tissue and, thus, eliminated the influence of precomputed brain masks. While our relevance-guided training method reached the same classification accuracy, incorporating relevance improved feature identification in an anatomically more reasonable manner.
Introduction
Deep learning techniques have become increasingly utilized in medical applications, including image reconstruction, segmentation, and classification.1,2 In particular for classification tasks deep learning methods have achieved high predictive accuracy, reaching in many cases human level performance. However, despite the good performance those models are not easily interpretable by humans, which is essential to gain trust into the prediction.3 Especially medical applications require to verify that the high accuracy of those models is not the result of exploiting artifacts in the data.
Our experiments on Alzheimer's disease (AD) classification based on MRI data showed that Deep Neural Networks (DNN) might learn irrelevant features outside the brain or only learn to evaluate the quality of the used skull stripping algorithm. Concerned by this finding, we investigate in this work which MRI features are relevant for the classification of patients with AD when compared to healthy controls. Additionally, we propose a method that allows to add prior knowledge to the training process, by focusing the training on relevant features. This has the effect that the trained model gets invariant to certain data preprocessing steps.
Methodology
Dataset. We retrospectively selected 226 MRI datasets from 106 patients with probable AD (mean age=71.5±8.0 years) from our outpatient clinic and 226 MRIs from 173 age-matched healthy controls (mean age=70.2±8.1 years) from an ongoing community dwelling study. Patients and controls were scanned using a consistent quantitative MRI protocol at 3 Tesla (Siemens TimTrio) including structural T1-weighted imaging and a FLAIR sequence (0.9x0.9x3mm³, TR/TE/TI=10s/70ms/2500ms, 44 slices). Brain masks from each subject were obtained using SIENAX from FSL using parameters: -B "-f 0.35 -B".4 The data was split up into 180 training, 23 validation and 23 test images.
Standard classification network. For our experiments we utilize a simple classification network, which uses the combination of a single convolutional layer followed by a down-convolutional layer as the main building block. The overall network stacks three of those main building blocks before passing the data through three fully connected layer. Each layer is followed by a Rectified Linear Unit (ReLU) nonlinearity, except for the output layer where a Softmax activation is applied.
Relevance-guided classification network. To focus the network on relevant features, we propose a relevance-guided network architecture, that extends the given classification network with a relevance map generator (cf. Figure 1 for details). In order to do so we implemented the deep Taylor decomposition ($$$z^{+}$$$-rule) to generate the relevance maps of each input image depending on the classifier's current parameters.5 Moreover we extended the classifier's categorical cross entropy loss by the following additional term
$$loss_{relevance}(\mathbf{R}, \mathbf{M}) = -\mathbf{1}^{T}vec(\mathbf{R}⊙\mathbf{M})\textrm{,}$$
where $$$\mathbf{R}$$$ denotes the relevance, $$$\mathbf{M}$$$ is a predefined mask, $$$vec(\mathbf{A})$$$ denotes the row major vector representation of $$$\mathbf{A}$$$, and $$$\mathbf{1}$$$ is a vector where all elements are set to one. Note, that the negative sign accounts for the maximization of the relevance, and $$$⊙$$$ denotes the Hadamard product.
Experimental Results
We train models with and without skull stripping as a preprocessing step and compare against our relevance-guided model. Note, that each model is trained using Adam for 300 epochs where the batch size is set to 8.6
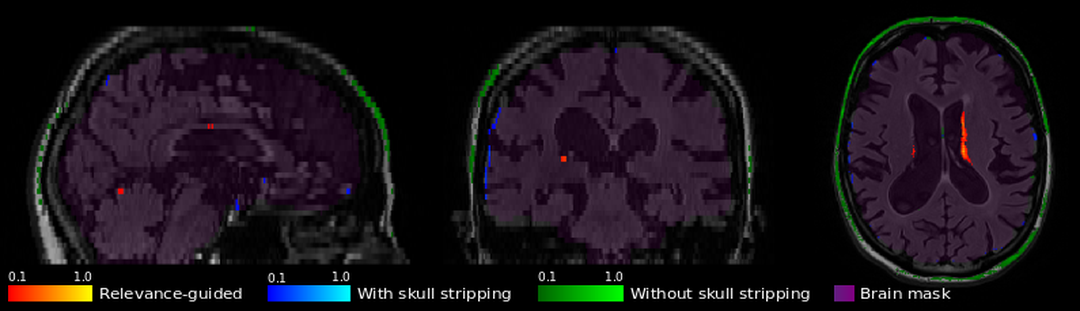
The resulting classification accuracy between control subjects and AD shows similar performance on the testset for the compared models (with skull stripping: 85%; without skull stripping: 87%; relevance-guided: 85%). However, when considering the corresponding relevance maps, shown in Figure 2, we obtain interesting insights about the trained features of the different models. We found that removing the skull creates artificial edges at the border between brain and background, which are learned as features for classification, whereas avoiding skull stripping completely causes relevant information to be outside the brain for some cases. The map from relevance-guided training on the other hand shows relevant regions inside the brain, in the presented case likely a combination of ventricle atrophy and white matter hyperintensities.
Discussion and Conclusion
We presented a relevance-guided classification network for the task of Alzheimer's disease classification. The network allows to focus on predefined image regions, presently brain tissue. Our method incorporates brain masks into a term of the loss function during training, which eliminates the dependency of the prediction on the quality of those masks and consequently also offers the possibility to identify anatomical regions at a subject-level relevant for the classification decision. Further work will include multiple MRI sequences (magnetization transfer, R2, R2*, diffusion) and identify which contrasts and anatomical structures bear relevant information for this classification task.Acknowledgements
This research was supported by a NVIDIA GPU hardware grant.References
[1] Zhou T, Thung K-H, Zhu X, Shen D. Effective feature learning and fusion of multimodality data using stage-wise deep neural network for dementia diagnosis. Hum Brain Mapp. 2018.
[2] Liu S, Liu S, Cai W, Pujol S, Kikinis R, Feng D. Early diagnosis of Alzheimer’s disease with deep learning. 2014 IEEE 11th International Symposium on Biomedical Imaging (ISBI). IEEE. 2014; 1015–1018.
[3] Samek W, Binder A, Montavon G, Lapuschkin S, Muller K-R. Evaluating the Visualization of What a Deep Neural Network Has Learned. IEEE Trans Neural Netw Learning Syst. 2017;28: 2660–2673.
[4] Smith SM, Zhang Y, Jenkinson M, Chen J, Matthews PM, Federico A, et al. Accurate, Robust, and Automated Longitudinal and Cross-Sectional Brain Change Analysis. Neuroimage. 2002;17: 479–489.
[5] Montavon G, Lapuschkin S, Binder A, Samek W, Müller K-R. Explaining nonlinear classification decisions with deep Taylor decomposition. Pattern Recognit. 2017;65: 211–222.
[6] Kingma DP, Ba J. Adam: A Method for Stochastic Optimization. CoRR,vol. abs/1412.6980, 2014.
Figures