4808
Automated Knee MRI Semantic Segmentation with Generative Adversarial Networks1Department of Radiology, University of Cambridge, Cambridge, United Kingdom
Synopsis
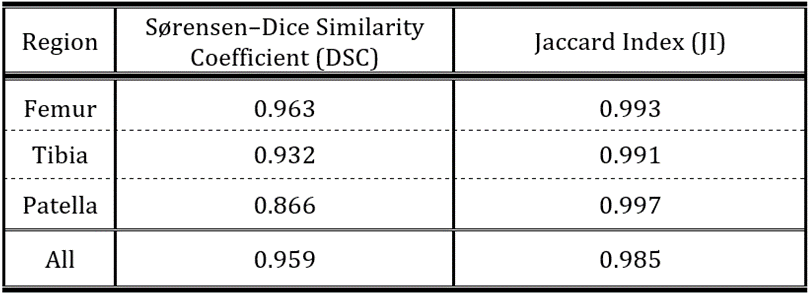
We describe a fully automated deep learning approach for generating semantic segmentation maps of the knee joint. A conditional Generative Adversarial Network (cGAN) was trained on 3D fat-saturated spoiled gradient recalled-echo MRIs of the knee from nine individuals (nimages=778) to generate segmentation maps containing the patella, femur and tibia. The trained network was tested with a separate dataset of one individual (nimages=80). The mean Sørensen–Dice Similarity Coefficient (DSC) was 0.959 and Jaccard Index was 0.985 for all three compartments. These results suggest that cGANs can perform accurate bony segmentation of the knee.
Introduction
Osteoarthritis (OA) is a common degenerative disorder affecting one or multiple diarthrotic joints and a major cause of physical disability in the adult population1,2. In recent years, advanced Magnetic Resonance Imaging (MRI) methods have been developed for evaluating joint health of the knee, which can improve treatment strategies prior to irreversible joint damage3,4. However, for both clinical and research usage, a significant amount of time is spent on generating segmented image masks for calculations such as bone shape and texture.
Convolutional neural networks, in particular U-Net5 and SegNet6, have shown great promise in their usage for automating this image segmenting process of musculoskeletal MRIs7,8. Nevertheless, a drawback of CNNs is that they require training of manually designed loss functions for different image segmentation or contrast generation tasks. Designing an effective loss function can be laborious and still not be optimal, and generate outputs with blurry boundaries9. Generative adversarial networks (GANs)10 can overcome this constraint by employing two neural networks, a generator and a discriminator, which are trained simultaneously and competitively against each other.
The aim of this study was to implement and evaluate a conditional GAN for automated semantic segmentation of the patellar, femoral and tibial bones including their surrounding cartilages.
Methods
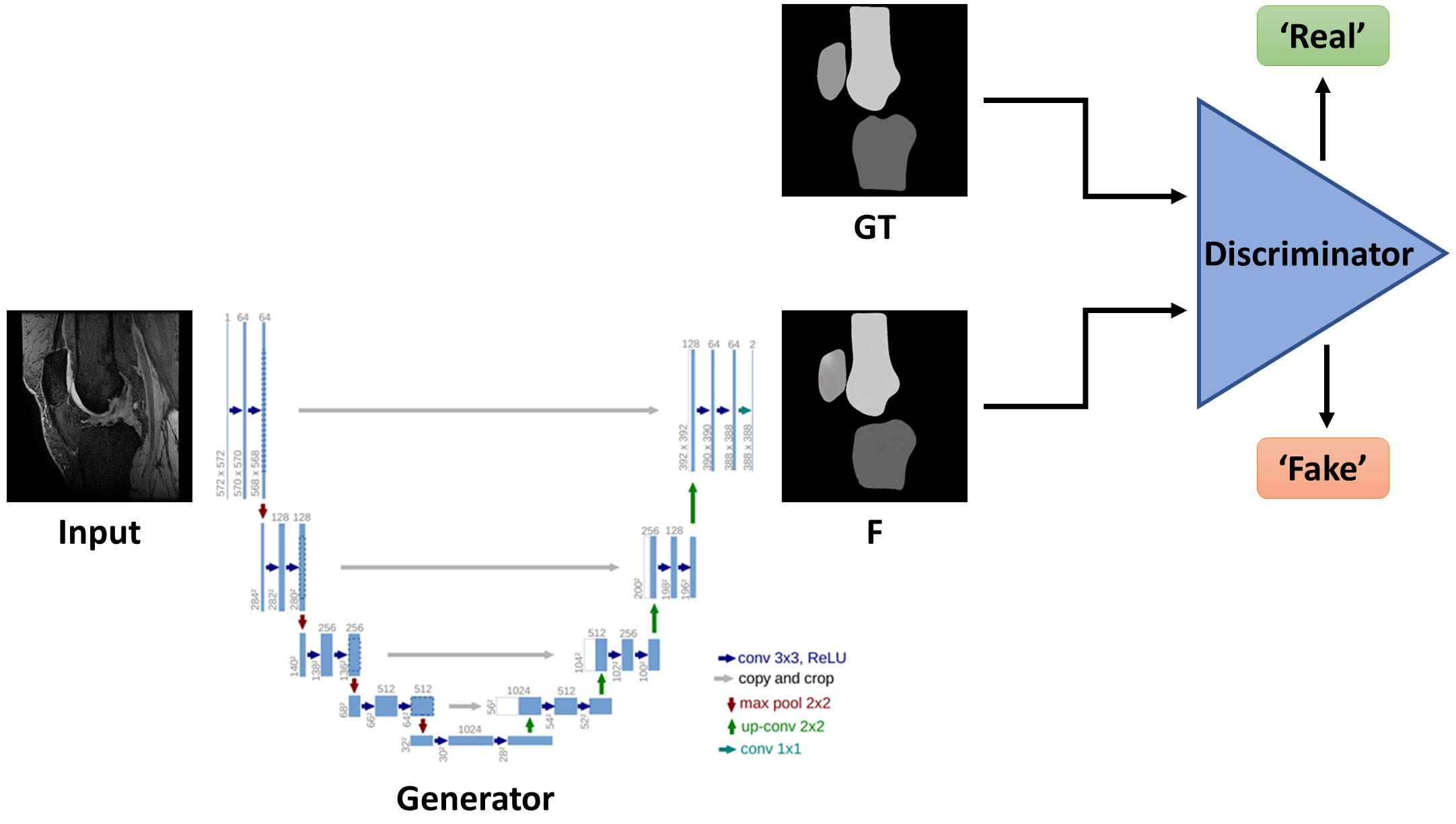
A conditional GAN (cGAN)11, a type of deep learning architecture, was used for machine learning of a segmented mask within PyTorch (Torch v0.5, CUDA v9.0) using a NVIDIA Quadro P6000 GPU. The cGAN generates an image from one network type, such as a U-Net, from which a second network, the discriminator, attempts to determine whether the image is “real” or “fake”. A cGAN generates an image from typically random noise z and receives additional image information as input. The generator used in this work uses the U-Net encoder-decoder architecture, which was trained to generate images that are indistinguishable from a target image (i.e., the segmented map). The discriminator performed a patch-wise (64x64) classification and then averaged all patches to create a binary output of whether the generated image was more ‘fake’ or ‘real’ than noise fed into the generator12. To reduce blurring and ensure low-frequency correctness, the L1 distance is incorporated into the loss function of the cGAN. The structure of a cGAN is illustrated in Figure 1.
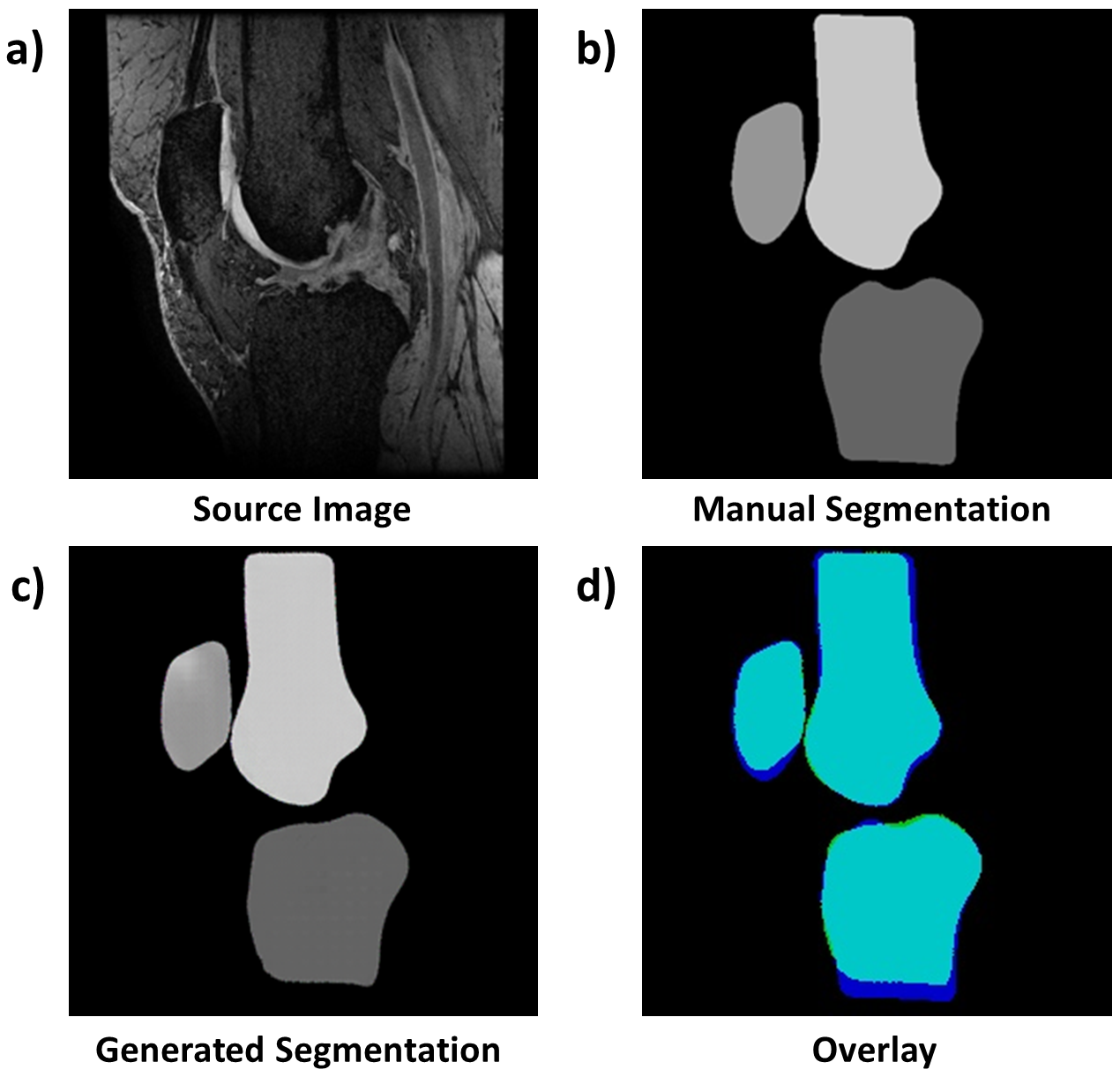
3D fat-saturated spoiled gradient recalled-echo (3D-SPGR FS) images from ten participants (5 healthy volunteers; 5 patients with mild-to-moderate OA (Kellgren-Lawrence grade 2-3)) acquired on a 3.0T MRI system (MR750 GE Healthcare, Waukesha, WI, USA) using an 8-channel transmit/receive knee coil were used as source images in this study (Fig. 2a). 3D-SPGR FS sequence parameters were: field-of-view=150mm, matrix size=512x380 zero-filled interpolated to 512x512, voxel size=0.29x0.29x1mm3. Segmented masks of the patella, tibia, and femur with their respective surrounding cartilage (‘real’ images, Fig. 2b) were created from the MRIs using a fully-manual segmentation. This data-set consisted of 3D training sets from nine participants (nimages=778) and a test set from a single participant (nimages=80). The Sørensen–Dice Similarity Coefficient (DSC) and the Jaccard Index (JI) were used to evaluate the overlap between the generated segmentation and the manual segmentation.
Results
Training took ≈2 hours for 200 epochs. Segmentation post-training on a single slice took ≈0.13s.
Figure 2c shows the generated segmentation from the example images in Figure 2a and 2b. Figure 2d depicts the overlapping area (cyan) between the manual (blue) and generated (green) segmentation maps by the proposed cGAN. The mean DSC for all regions was 0.959 and mean JI was 0.985, showing a high similarity between the test and manual sets. DSCs/JIs for each region are in Table 1. A small amount of intensity thresholding was required to obtain binary masks on the predicted masks (+/-20% of the predicted value) (Figure 3).
Discussion
This work demonstrated high DSC scores for automated segmentation of three knee joint regions. The tibia and femur had high DSC scores, while the patella achieved the lowest DSC score. The patellar training might be less constrained due to its high inter-subject variability when compared to the larger tibial and femoral regions. The segmentation of the tibia fails at its lower regions where B1 transmit and receive homogeneity is poor due to characteristics of the coil (cp. Fig. 2a & d).
The number of segmented regions were limited in this data-set due to the time-consuming nature of manual segmentation. Further work to increase the number of training masks will allow better training and achieve higher segmentation accuracy.
Conclusion
This work demonstrated a method for accurate semantic segmentation of three bony knee compartments with the use of cGANs, which we hope can improve the accuracy and time efficiency for evaluating joint health.Acknowledgements
We acknowledge the support of Robert L Janiczek (Experimental Medicine Imaging, GlaxoSmithKline, London, UK) and Alexandra R Morgan-Roberts (Independent Clinical Imaging Consultant, Munich, DE). This work was supported by GlaxoSmithKline, Addenbrooke's Charitable Trust, and the National Institute of Health Research Cambridge Biomedical Research Centre.References
1. Goldring, M. B., Culley, K. L. & Otero, M. Pathogenesis of Osteoarthritis in General. in Cartilage: Volume 2: Pathophysiology (eds. Grässel, S. & Aszódi, A.) (Springer International Publishing, 2017). doi:10.1007/978-3-319-45803-8
2. Martel-Pelletier, J. et al. Osteoarthritis. Nat. Rev. Dis. Prim. 2, (2016).
3. Matzat, S. J., van Tiel, J., Gold, G. E. & Oei, E. H. G. Quantitative MRI techniques of cartilage composition. Quant. Imaging Med. Surg. 3, 162–74 (2013).
4. Li, X. & Majumdar, S. Quantitative Magnetic Resonance Imaging of Articular Cartilage and its Clinical Applications. J. Magn. Reson. Imaging 38, 991–1008 (2013).
5. Ronneberger, O., Fischer, P. & Brox, T. U-Net: Convolutional Networks for Biomedical Image Segmentation. 1–8 (2015). doi:10.1007/978-3-319-24574-4_28
6. Badrinarayanan, V., Kendall, A. & Cipolla, R. SegNet: A deep convolutional encoder-decoder architecture for image segmentation. arXiv Prepr. arXiv1511.00561 39, 2481–2495 (2015).
7. Liu, F. et al. Deep convolutional neural network and 3D deformable approach for tissue segmentation in musculoskeletal magnetic resonance imaging. Magn. Reson. Med. 79, 2379–2391 (2018).
8. Norman, B., Pedoia, V. & Majumdar, S. Use of 2D U-Net Convolutional Neural Networks for Automated Cartilage and Meniscus Segmentation of Knee MR Imaging Data to Determine Relaxometry and Morphometry. Radiology 288, 177–185 (2018).
9. Pathak, D., Krahenbuhl, P., Donahue, J., Darrell, T. & Efros, A. A. Context Encoders: Feature Learning by Inpainting. arXiv Prepr. arXiv1604.07379v2 1–12 (2016). doi:10.1109/CVPR.2016.278
10. Goodfellow, I. J. et al. Generative Adversarial Networks. arXiv Prepr. arXiv1406.2661v1 1–9 (2014). doi:10.1001/jamainternmed.2016.8245
11. Mirza, M. & Osindero, S. Conditional Generative Adversarial Nets. arXiv Prepr. arXiv1411.1784v1 1–7 (2014).
12. Isola, P., Zhu, J. Y., Zhou, T. & Efros, A. A. Image-to-image translation with conditional adversarial networks. Proc. - 30th IEEE Conf. Comput. Vis. Pattern Recognition, CVPR 2017 5967–5976 (2017). doi:10.1109/CVPR.2017.632
Figures