4798
Random forests and DenseNet: a comparative study of brain gliomas segmentation1Padova Neuroscience Center, University of Padova, Padova, Italy, 2Department of Information Engineering, University of Padova, Padova, Italy
Synopsis
Machine Learning techniques can provide useful automatic tools. Segmentation of brain tumors is a time consuming task that could potentially beneficiate from its automation. This work investigate and compare the performances of two frameworks: Random forest and DenseNet. The former is a well known framework and the latter is a novel technique based on deep learning.
Introduction
Machine Learning provides important tools for brain gliomas segmentation1. Many approaches have been recently proposed and the advent of Deep Learning led to an exponential growth of the field. In this work, we compared a state of the art framework, the Random Forest2, already applied for segmentation purposes, with a novel framework, the DenseNet3. The comparison was performed taking into consideration the ability of both algorithms to segment the whole tumour component. The long term goal of our study will be to use the results of this framework to better inform image registration to a standard template, to mask the tumour and finally to automatically retrieve maps of the homologous hemisphere that could serve as a reference for multi-parametric mapping analysis.Methods
Dataset: We
used the BraTs 2017 challenge1
dataset (285 patients diagnosed with glioma, acquired in a
multi-center fashion). The dataset was sub-divided in training (190),
test (65) and validation set (20). Each patient dataset comprised a
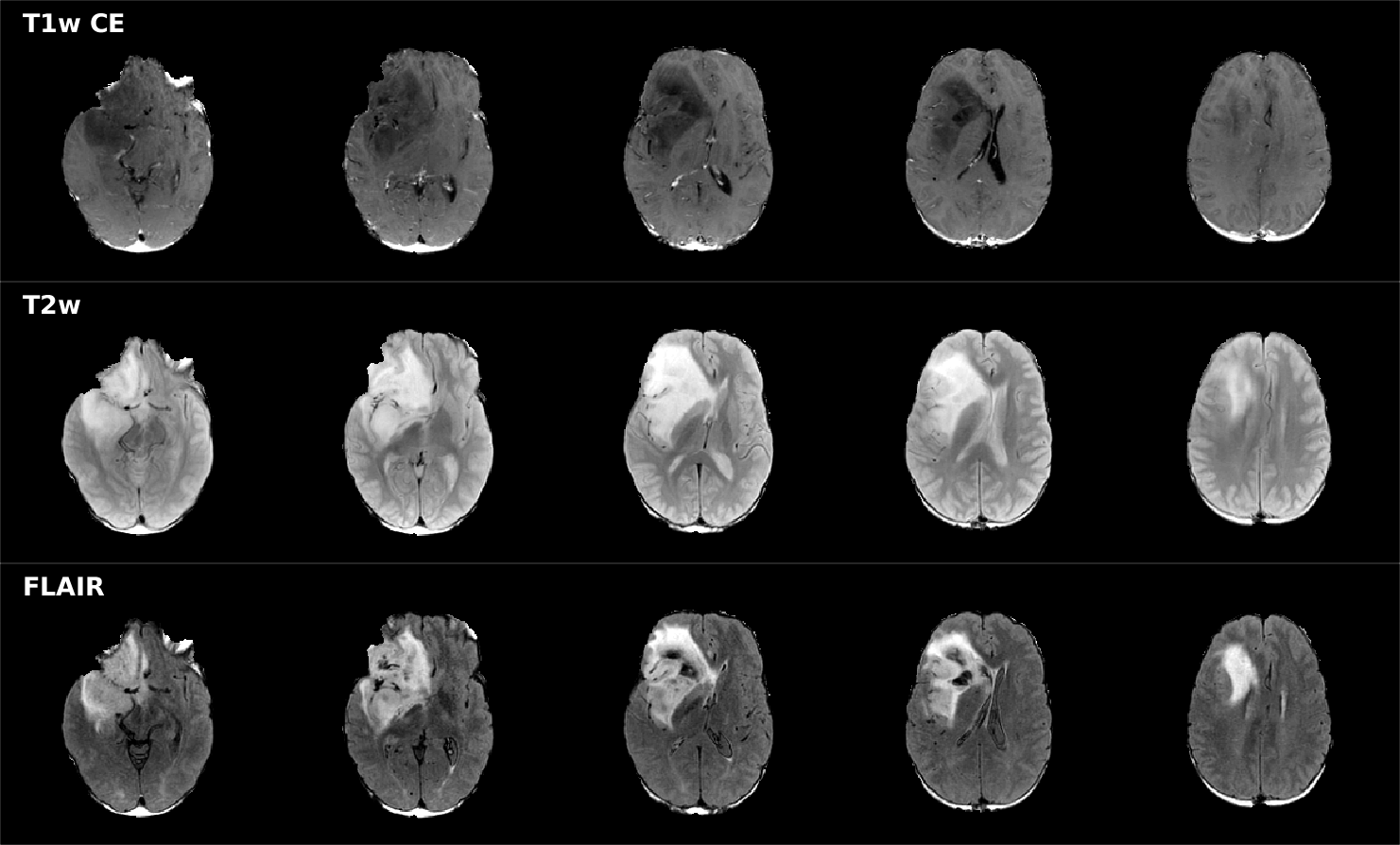
T1-weighted, a T2-weighted, a FLAIR and a post contrast T1-weighted
image. Pre-processing consisted of co-registration to the same
structural space, interpolation to the same resolution (1x1x1 mm),
skull-stripping1 and z-score normalization to avoid polarization
in parameter estimation. The dataset included also a manual
segmentation of the tumour. For this work, we focused on the
segmentation of the whole tumour component (Figure 1).
Models:
The
segmentation process was compared using two frameworks: Random
Forests2
(RF) and DenseNet3.
Both models were trained and evaluated on 2D images. Random Forests
were enhanced with both statistical features and textures (patch of
5x5 voxels were used to calculate the features) based on Heralick’s
et al work4.
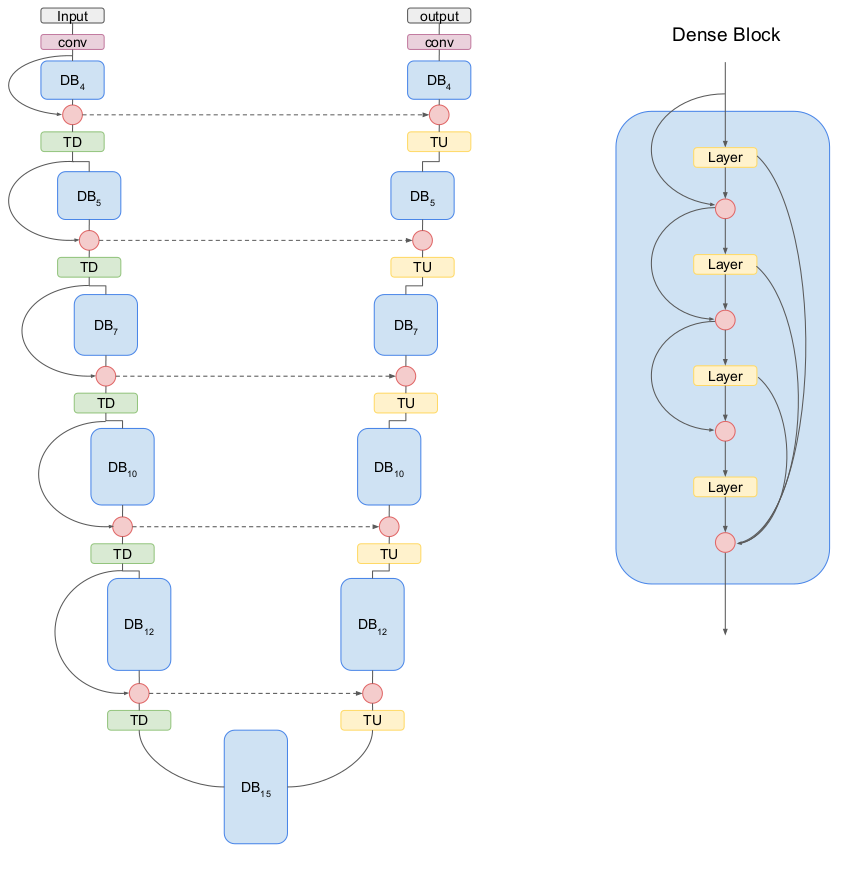
Among many recently introduced DenseNet architectures we decided to
implement the one-hundred layers Tiramisu network5
(Figure
2). More specifically, we implemented the Fully Convolutional
DenseNet-103 (FCD103). All models were implemented in Python 3.6: RF
were implemented using SciKit-learning package (v.
0.19.0)
while FCD103 was implemented in pytorch (v0.41).
Training:
RF: ten decision trees were ensemble, Gini criterion was used to
evaluate the quality of split, no constraints were introduced on
minimum number of leaf or on the impurity of the split, bootstrap was
used in decision tree building. Training time for RF was
approximately 78 hours. FCD103 network was trained using the cross
entropy loss criterion and the RMSprop optimizer with learning rate
of 1e-4 and weight decay of 1e-4. The training lasted for 60 epochs.
Adjustment of learning rate was performed after each epoch. We did
not perform any pre-training on the FCD103 to better compare RF and
FCD103 performances based on a single dataset. Training time was
approximately 22 hours (Nvidia Titan XP GPU).
Testing:
Performance
metrics were calculated on the whole tumour component on the testing
set. The validation set was used only for FCD103 parameters
evaluation and was not used in the comparison. Dice score, Hausdorff
distance at 95th
percentile, sensitivity and specificity were computed as a complete
measure of goodness of the segmentation process.
Results
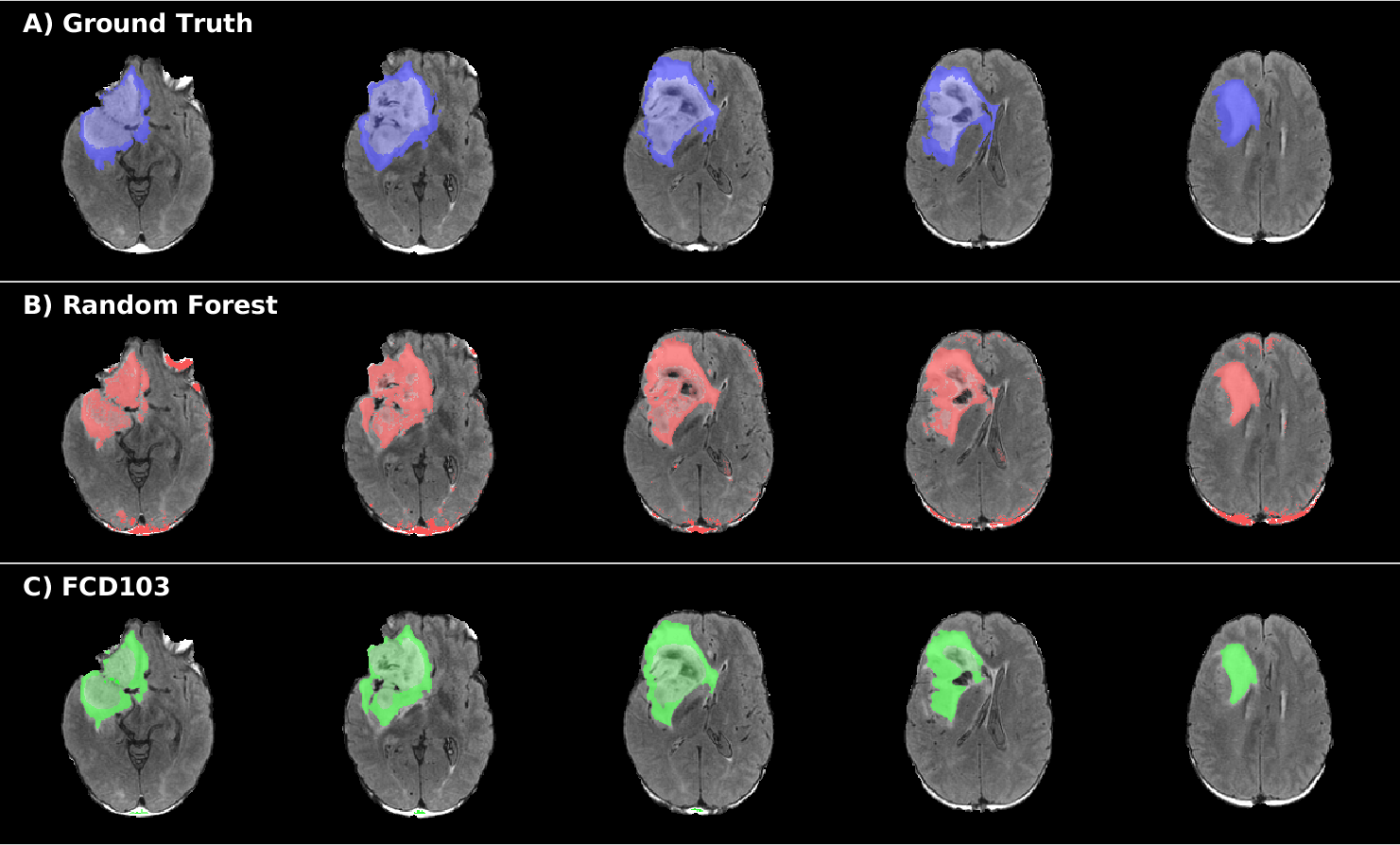
Quantitative segmentation score results are reported in Table 1. Both methods reached good values in Dice score (>0.9) and had similar specificity, while the Hausdorff distance was higher (worse performance) for RF compared to FCD103. FCD103 showed also higher sensibility than RF. RF yielded in general isolated voxels misclassified both inside and outside of the tumour boundaries (Figure 3B). FCD103 segmentation was more regular and smoother than RF one and furthermore it did not yield almost any wrongly classified isolated voxel (Figure 3C).Discussion
This work investigated how a well established framework (RF) performed in brain glioma segmentation and compared its performance with that of a recently introduced convolutional network (FCD103). Both approaches provided similar performance in term of Dice score and specificity. RF showed however a worse performance for the Hausdorff distance, which could be caused by the presence of spurious voxels misclassified outside the tumour region. Post processing operations exploiting regularization approaches were not used to purely compare how these two frameworks extract and learn optimal features.Conclusion
Both RF and FCD103 performed well in the whole tumour segmentation task; however, FCD103 produced more regular boundaries and more robust segmentation maps. Therefore, FCD103 should be preferred to the RF framework (even if enhanced with statistical features and Haralick textures) when a whole brain segmentation task has to be performed.. Further studies should extend the 2D FCD103 approach to a 3D approach, that could potentially improve even further the performance of the segmentation providing regular boundaries also in the z-direction.Acknowledgements
We gratefully acknowledge the support of NVIDIA Corporation with the donation of the Titan X Pascal GPU used for this research.References
1B. H. Menze et al., “The Multimodal Brain Tumor Image Segmentation Benchmark (BRATS),” IEEE Trans. Med. Imaging, vol. 34, no. 10, pp. 1993–2024, Oct. 2015.
2Breiman, Leo. "Random forests." Machine learning 45.1 (2001): 5-32.
3Huang, Gao, et al. "Densely Connected Convolutional Networks." CVPR. Vol. 1. No. 2. 2017.
4R. M. Haralick, K. Shanmugam, and I. ’hak Dinstein, “Textural Features for Image Classification,” IEEE Trans. Syst. Man Cybern., vol. SMC-3, no. 6, pp. 610–621, 1973.
5Jégou, Simon, et al. "The one hundred layers tiramisu: Fully convolutional densenets for semantic segmentation." IEEE CVPRW, 2017.
Figures