4793
Spatio-Temporal Undersampling Artefact Reduction with Neural Networks for Fast 2D Cine MRI with Limited Data1Department of Radiology, Charité - Universitätsmedizin Berlin, Berlin, Germany, 2Physikalisch-Technische Bundesanstalt (PTB), Braunschweig and Berlin, Germany, 3School of Biomedical Engineering and Imaging Sciences, King’s College London, London, United Kingdom
Synopsis
A well-known bottleneck of neural networks is the requirement of large datasets for successful training. We present a method for reduction of 2D radial cine MRI images which allows to properly train a neural network on limited datasets. The network is trained on spatio-temporal slices of healthy volunteers which are previously extracted from the image sequences and is tested on patients data with known heart dysfunction. The image sequences are reassembled from the processed spatio-temporal slices. Our method is shown to have several advantages compared to other Deep Learning-based methods and achieves comparable results to a state-of-the-art Compressed Sensing-based method.
Introduction
Deep Learning has been widely applied for reduction of undersampling artefacts in different imaging1 a well-known bottleneck of neural networks is the requirement of large datasets for a successful training.Data-augmentation is usually applied to artificially enlarge the given dataset and make the network more robust with respect to unseen examples. In this work, we investigate the applicability of a Deep Learning-based method using a limited dataset. We reduce undersampling artefacts in 2D radial cine MRI by applying a U-net in spatio-temporal space.Methods
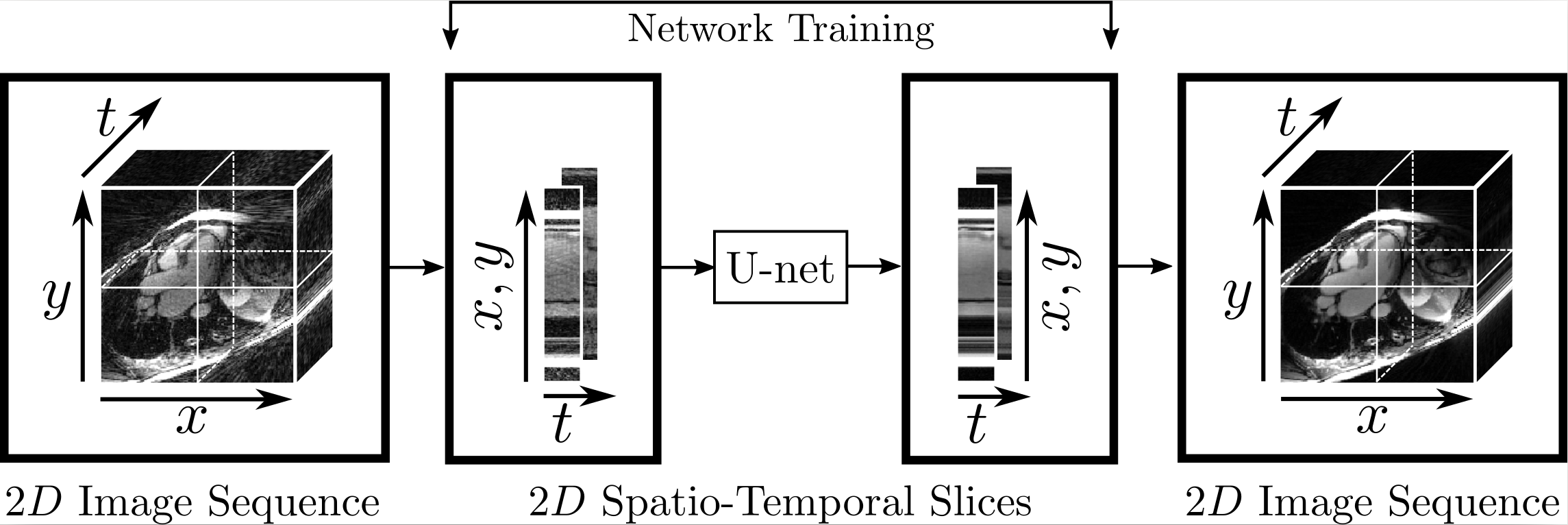
Data acquisition and image reconstruction: 2D Golden Radial data was acquired continuously during a 10 s breathhold in 15 healthy volunteers and 4 patients with known heart dysfunction (TE/TR 3/1.5ms, FA 60°) 2. For each subject, Nz = 12 slices of shape Nx x Ny = 320 x 320 were acquired in long-axis orientations. The inplane resolution was 2 mm, the slice thickness 8 mm. Based on a recorded ECG-signal, the first Nθ = 1130 radial lines (i.e. 3.3s of data acquisition) were retrospectively separated into Nt = 30 cardiac phases using a sliding window approach. Each cardiac phase was reconstructed with a standard gridding approach (NUFFT) 3.
Artefact reduction using neural networks: We reduced undersampling artefacts arising from the NUFFT reconstruction of the undersampled k-space data by training a neural network on the data considered in the spatio-temporal domain. For this purpose, we constructed our training set by extracting two-dimensional spatio-temporal slices from the image sequences, see Figure 1. We used a slightly modified version of the U-net 4 which performs max-pooling only along the spatial dimension. The network is trained to map the spatio-temporal slices of the NUFFT reconstructions to the corresponding ground truth slices obtained with a kt-SENSE5 reconstruction using Nθ = 3400 lines.
Evaluation: The training and validation set consist of image sequences of 13 and 2 healthy volunteers, respectively, while the test set consists of 4 patients. In order to investigate the applicability of the method for a small number of subjects, we fixed the number of healthy volunteers we extracted the spatio-temporal slices from and did not make use of any data-augmentation technique. We compared our proposed approach to several Deep Learning-based approaches for reducing undersampling artefacts in cine MRI as well as to a state-of-the-art Compressed Sensing-based method.
Results
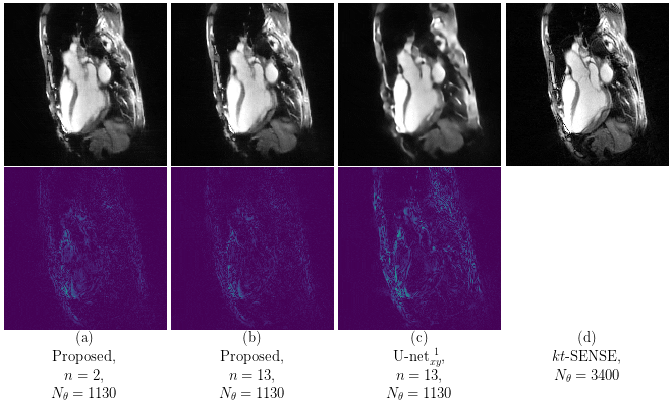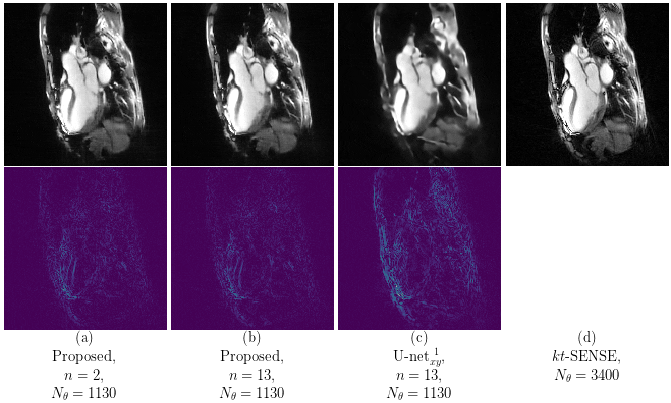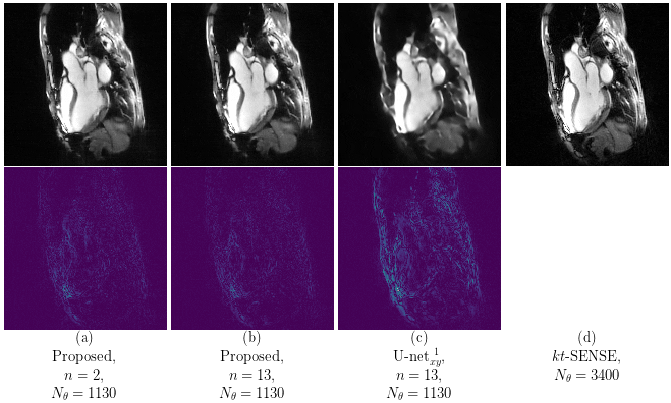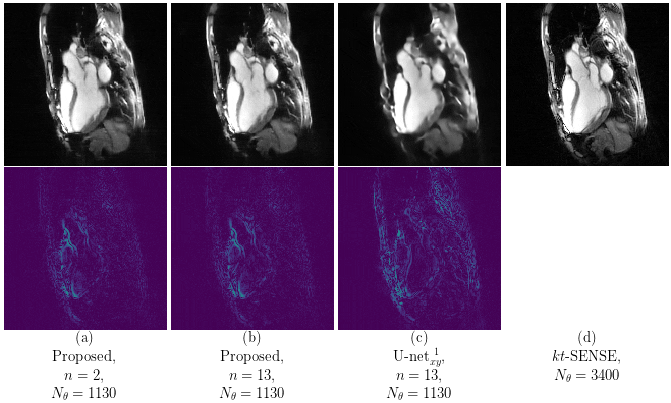
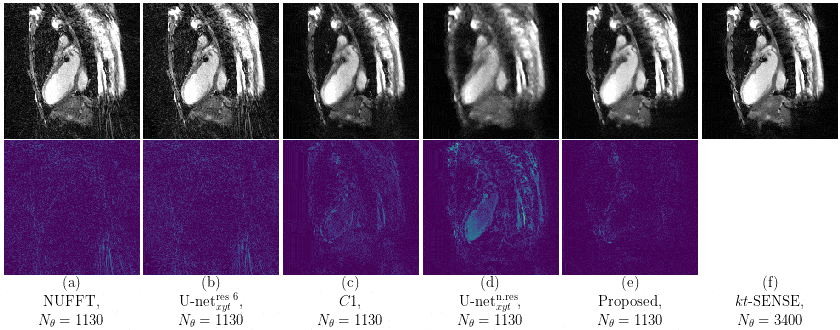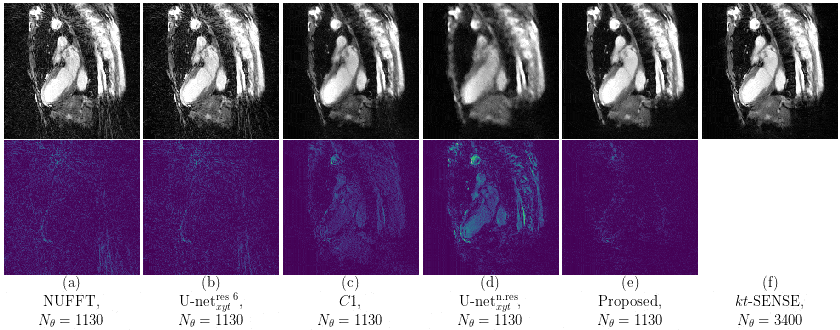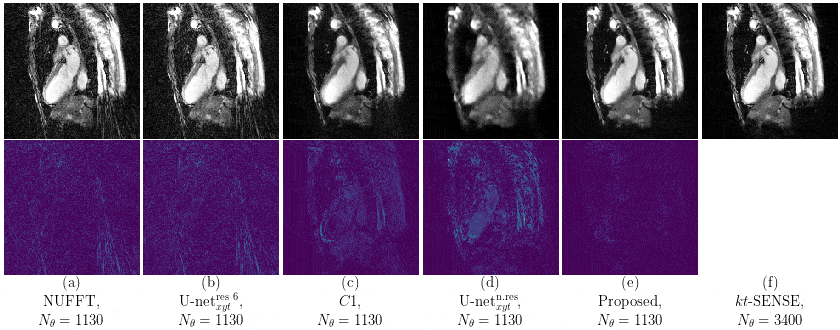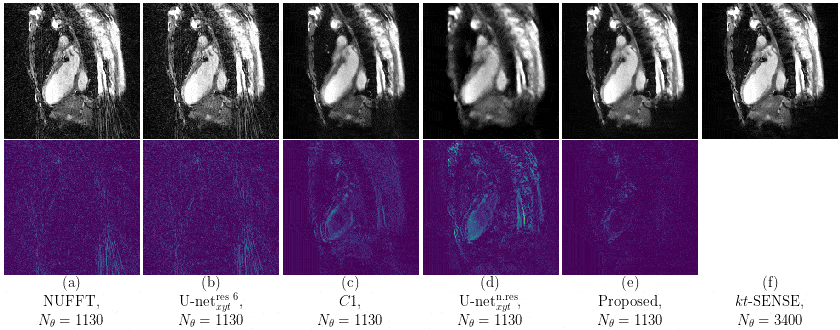
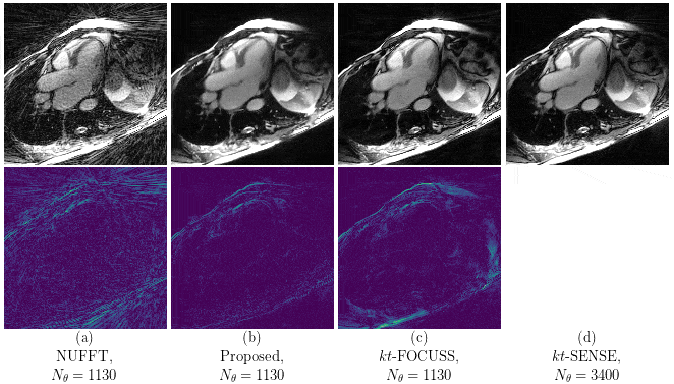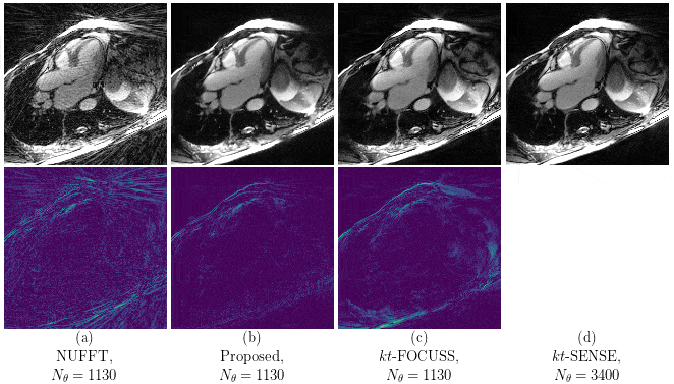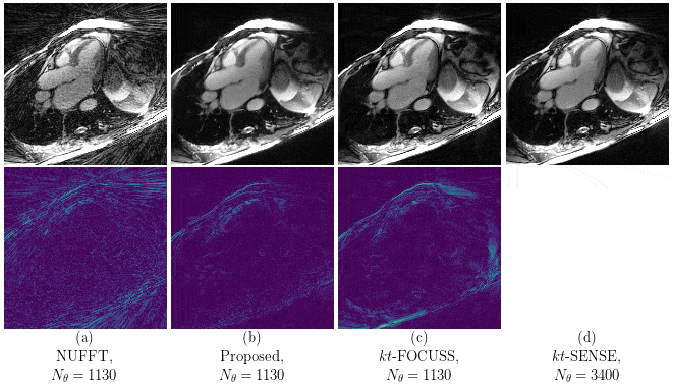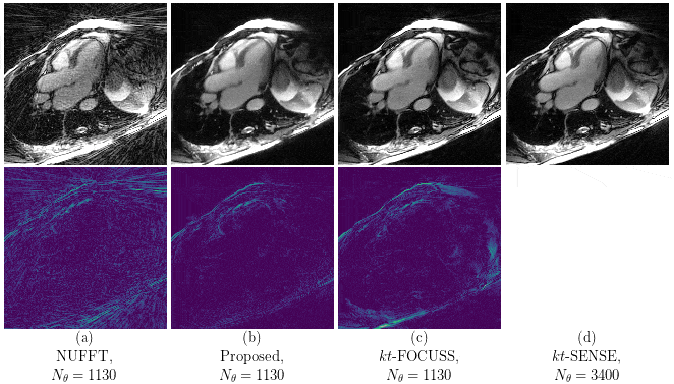
Our proposed method accurately removed the undersampling artefacts in all the images on the test set. When trained on data of two or more healthy volunteers, i.e. n≥2, our approach (U-netxt,yt) not only removed the undersampling artefacts but also well-preserved heart movement, see Figure 2. Without augmenting the data, a successful training (i.e. without immediate overfitting) in spatial domain was only possible for n≥8. However, our method yields visually superior results compared to the frame-wise trained U-net (U-netxy) 1 which tends to smooth out image details. For the sequence-wise training approach, the residual architecture U-netxytres 6 poorly reduced the artefacts, while other non-residual architectures as a single convolutional layer network (C1) or a non-residual U-net ( U-netxytn.res ) lost temporal information, see Figure 3 (c) and (d). Furthermore, our method delivered similar qualitative results when compared to cine images reconstructed with kt-FOCUSS 7, see Figure 4.Discussion
Given n subjects with Nz slices of size Nx x Ny with Nt cardiac phases, we have n · Nz · (Nx + Ny ) training samples, where in the frame-wise and the sequence-wise approach, the number of training samples reduces to n · Nz · Nt and n · Nz , respectively. Therefore, our method performs well even when trained on highly limited datasets. Since the spatio-temporal slices have a particularly simple-structure in contrast to the frames in spatial domain, the undersampling reduction is facilitated. Furthermore, our results are comparable to kt-FOCUSS in terms of image quality and preservation of the heart movement while the reconstruction time is reduced by orders of magnitude.Conclusion
We have tested the feasibility of our proposed method in various experiments and demonstrated that, using the spatio-temporal approach, it is possible to successfully train a neural network on limited datasets. No visible artefacts which could be attributed to the reassembling of the sequences from the spatio-temporal slices were visible inthe reconstructions. However, a limitation of the work is possible oversmoothing of the temporal profiles which might occur in the processing of the images and future work will focus on the design of network architectures which tackle the problem by more sophisticated building blocks such as perceptual or adversarial losses.Acknowledgements
A. Kofler and M. Dewey acknowledge support from the German Research Foundation (DFG), project number GRK 2260, BIOQIC. C. Wald and M. Dewey acknowledge funding from the Berlin Institute of Health.References
1. Jin Kyong Hwan, McCann Michael T, Froustey Emmanuel, Unser Michael. Deep convolutional neural network for inverse problems in imaging. IEEE Transactions on Image Processing. 2017;26:4509–4522.
2. Kolbitsch Christoph, Prieto Claudia, Schaeffter Tobias. Cardiac functional assessment without electrocardiogram using physiological self-navigation. Magnetic resonance in medicine. 2014;71:942–954.
3. Jackson John I, Meyer Craig H, Nishimura Dwight G, Macovski Albert. Selection of a convolution function for Fourier inversion using gridding (computerised tomography application). IEEE transactions on Medical Imaging. 1991;10:473–478.
4. Ronneberger Olaf, Fischer Philipp, Brox Thomas. U-net: Convolutional networks for biomedical image segmentation in International Conference on Medical image computing and computer-assisted intervention:234–241Springer 2015.
5. Tsao Jeffrey, Boesiger Peter, Pruessmann Klaas P. k-t BLAST and k-t SENSE: dynamic MRI with high frame rate exploiting spatiotemporal correlations. Magnetic Resonance in Medicine: An Official Journal of the International Society for Magnetic Resonance in Medicine. 2003;50:1031–1042.
6. Sandino Christopher M, Dixit Neerav, Cheng Joseph Y, Vasanawala Shreyas S. Deep convolutional neural networks for accelerated dynamic magnetic resonance imaging. In Proceedings of Medical Imaging meets Neural Information Processing Systems Conference, Long Beach, CA, 2017. p. 19.
7. Jung Hong, Sung Kyunghyun, Nayak Krishna S, Kim Eung Yeop, Ye Jong Chul. k-t FOCUSS: a general compressed sensing framework for high resolution dynamic MRI Magnetic resonance in medicine. 2009;61:103–116.
Figures