4785
ShiftNets: Deep Convolutional Neural Networks for MR Image Reconstruction & the Importance of Receptive Field of View1Electrical Engineering, Stanford University, Stanford, CA, United States, 2Radiology, Stanford University, Stanford, CA, United States, 3Bioengineering, Stanford University, Stanford, CA, United States
Synopsis
Deep learning has been applied to the Parallel Imaging problem of resolving coherent aliasing in image domain. Convolutional neural networks have finite receptive FOV, where each output pixel is a function of a limited number of input pixels. For uniformly undersampled data, a simple hypothesis is that including the aliased peak in the receptive FOV would improve suppression of aliasing. We show that a simple channel augmentation scheme allows us to resolve aliasing using 50x fewer parameters than a large U-Net with millions of parameters and a global receptive FOV. This method was tested on retrospectively undersampled knee volumes.
Introduction
MR reconstruction algorithms using Convolutional Neural Networks (CNNs) have attracted significant interest due to their rapid performance at test time. We demonstrate that the CNN's receptive Field of View (FOV) is an essential part of attaining high fidelity reconstructions. This is important for random undersampling, which distributes a pixel's energy across the entire image and achieves higher accelerations compared to uniform undersampling1. We trained a U-Net2 to perform a uniformly undersampled reconstruction task and show that a simple channel augmentation scheme leads to superior suppression of aliasing. This augmentation scheme achieves high quality reconstructions with 50× fewer parameters than the comparison U-Net with a large receptive FOV. This offers validity to recent neural network approaches that incorporate both image domain and k-space operations in randomly undersampled reconstructions3,4. This work was presented in part at the ISMRM ML Workshop Part II5.Theory
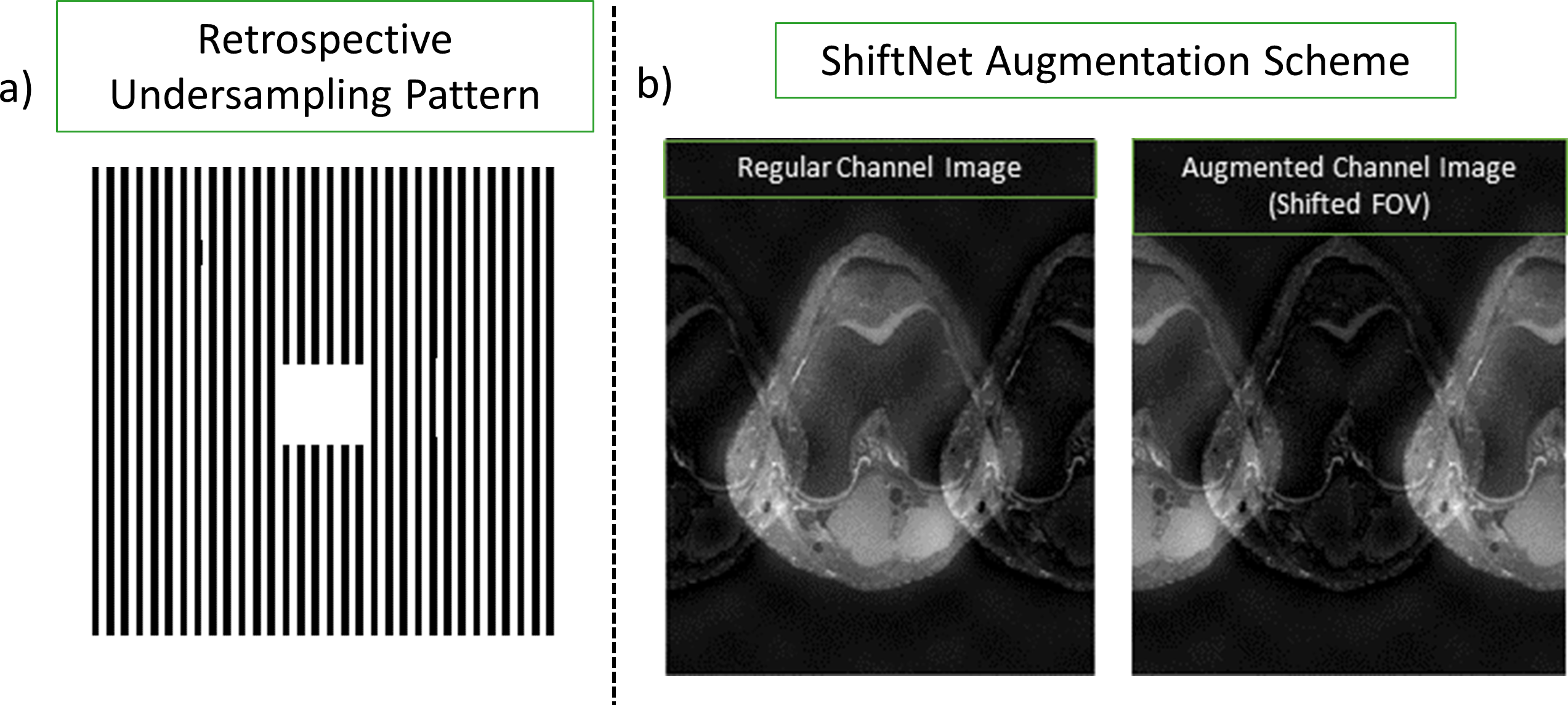
In a 2× uniformly undersampled image, the energy required to reconstruct a pixel is located FOV/2 away. CNNs have a limited receptive FOV6, where each output pixel is a function of a fraction of the input. We expect that a network with the FOV/2 aliased replica within its receptive FOV would be better at resolving undersampling artifacts. To validate this hypothesis, we introduce a channel augmentation scheme that shifts the input coil images by FOV/2 in the undersampling direction and concatenates it to the input, thus doubling the number of input channels. We refer to networks that employ this scheme as ShiftNets5. The uniform undersampling pattern used in this work and a diagram of the channel augmentation scheme are shown in Figure 1.Methods
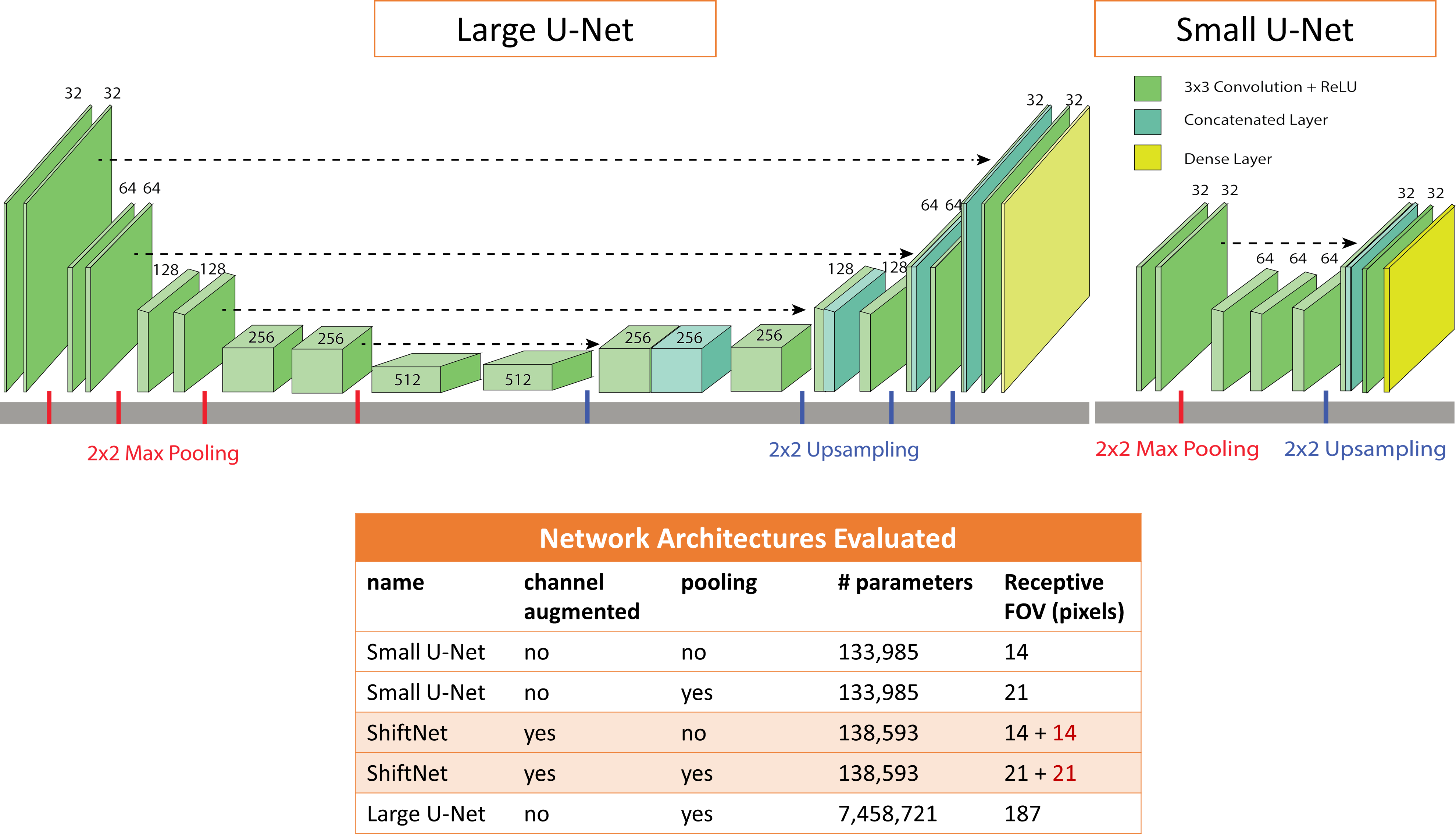
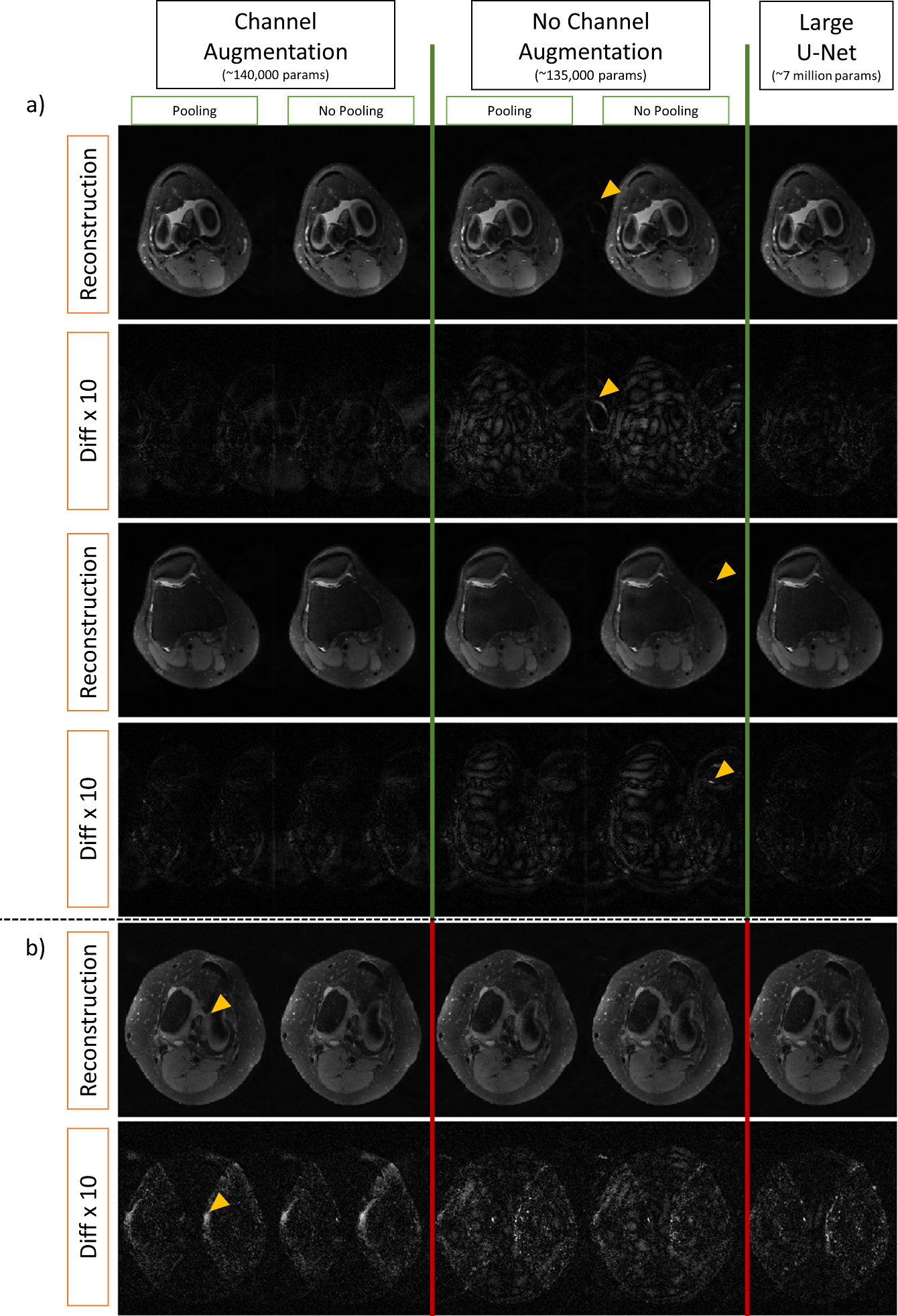
3D knee volumes from mridata.org were used for the reconstruction task7. Each volume has a matrix size of 320 x 320 x 256 and 8 channels. Five knee volumes were used for training, one for calculating validation loss, and four for test. Axial coil magnitude images were retrospectively undersampled by a factor of 2× retaining 13 lines in the center. We tested three network architectures shown in Figure 2. A large U-Net with 7.4 million weights, similar to the network presented in 8, was compared to a small U-Net (∼135,000 weights), and a small U-Net employing the channel augmentation scheme (∼140,000 weights). The small U-Nets were tested with and without pooling. We augmented the dataset by randomly applying a vertical or horizontal flip to the training set at every epoch. Training was done over 300 epochs using an Adam optimizer with a learning rate of 0.001, decay of 0.01, batch size of 10, and MSE loss.Results
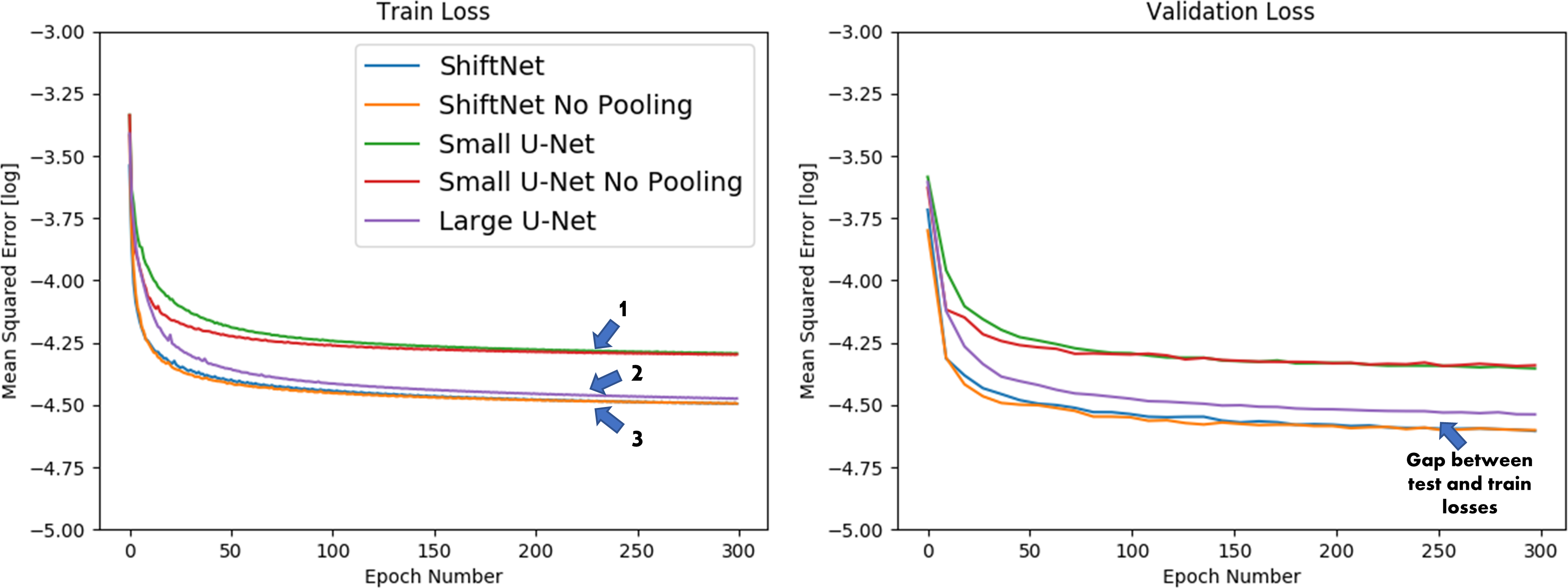
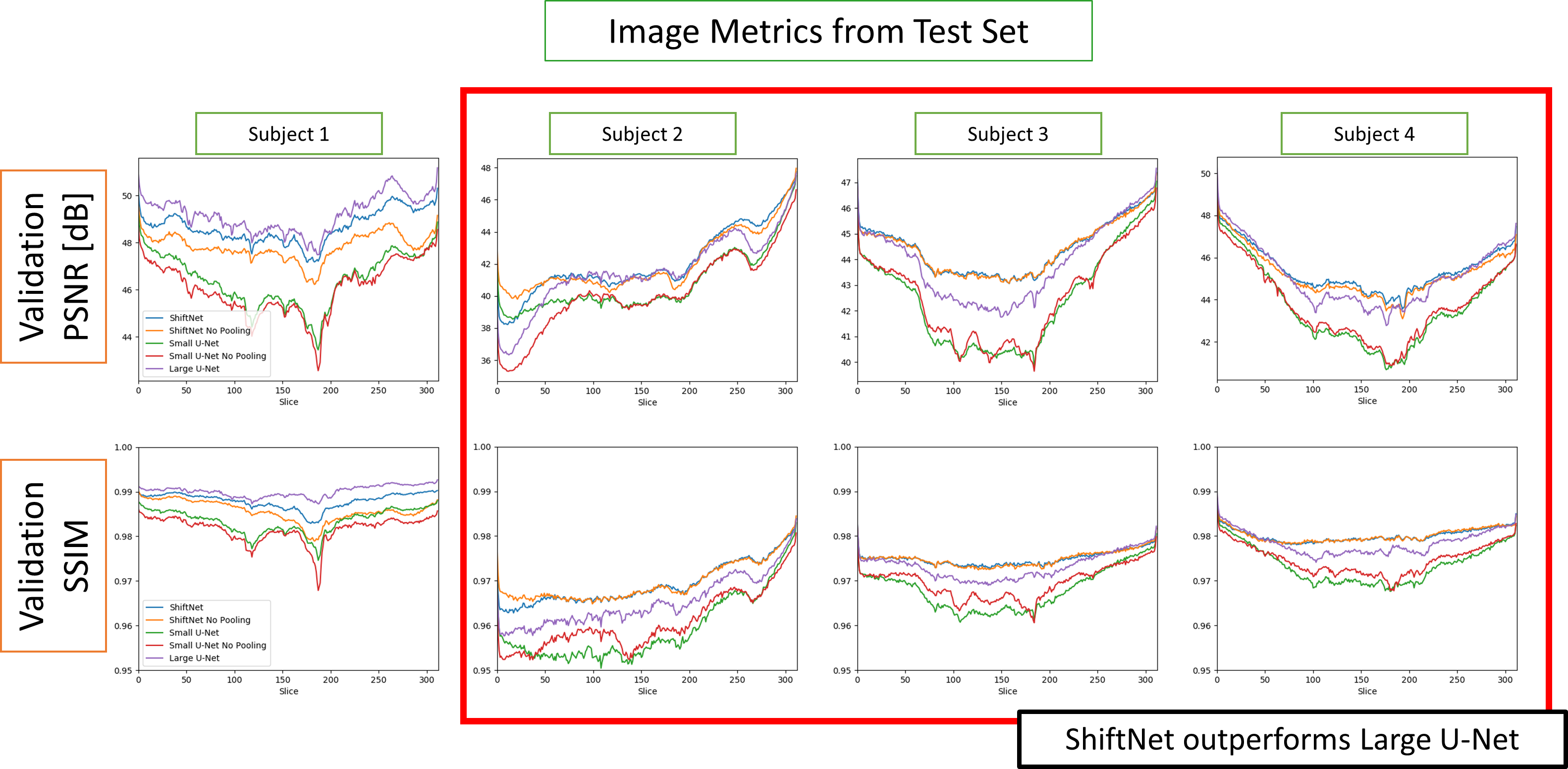
Training and validation losses, and quantitative error metrics from the test set in Figure 3 demonstrate that channel augmentation is advantageous in the small U-Net. In the training loss, we see three distinct trends which are denoted by blue arrows. Trend (1) comprises of networks without channel augmentation. Trend (2) comprises of networks with channel augmentation: the ShiftNets. Trend (3) is the large U-Net. While all three networks achieve high PSNR and SSIM, there is a clear gap between the network with a small receptive FOV and the comparison networks. ShiftNets achieve SSIM and PSNR image metrics comparable to the large U-Net with 50x fewer weights. Pooling layers provide negligible benefits. Reconstructions from the validation set are shown in Figure 5. While all networks have good performance, difference maps show that unresolved aliasing is more prevalent in the network with a receptive FOV that excludes the aliased replica.Discussion
ShiftNet slightly outperformed the large U-Net for three subjects and slightly underperformed for one subject. A possible cause for this relative improvement is that fewer layers in ShiftNet improve gradient propagation, improving convergence. A second possibility is that there is reduced overfitting in the small U-Net, as evidenced by the validation loss gap between ShiftNet and the large U-Net, shown in Figure 2.
Our preliminary study considered magnitude images with a small undersampling factor. Applying the channel augmentation scheme to higher undersampling factors could yield larger reconstruction differences when compared to the reference while reducing the number of parameters required for the network. The results here suggest that explicitly incorporating k-space operations that affect a global spatial scale, would improve a neural network’s ability to resolve random undersampling artifacts.
Conclusion
We demonstrated that receptive field of view affects the reconstruction of undersampled images. This suggests that incorporating k-space operations into a network architecture is important for achieving high quality reconstructions.Acknowledgements
GE Healthcare.References
[1] Lustig M, et al. Sparse MRI: The application of compressed sensing for rapid MR imaging. MRM, 2007.
[2] Ronneberger O, et al. U-Net: Convolutional Networks for Biomedical Image Segmentation. arXiv:1505.04597, 2015.
[3] Diamond S, et al. Unrolled Optimization with Deep Priors. arXiv:1705.08041, 2017.
[4] Eo T, et al. KIKI-net: cross-domain convolutional neural networks for reconstructing undersampled magnetic resonance images. MRM, 2018.
[5] Lee P, et al. ShiftNets: Deep Convolutional Neural Networks for MR Image Reconstruction & the Importance of Receptive Field of View. ISMRM ML Workshop Part II, 2018.
[6] Krizhevsky A, et al. ImageNet Classification with Deep Convolutional Neural Networks. NIPS, 2012.
[7] Epperson K, et al. Creation of Fully Sampled MR Data Repository for Compressed Sensing of the Knee. SMRT, 2013.
[8] Lee D, et al. Deep artifact learning for compressed sensing and parallel MRI. arxiv:1703.01120, 2017.
Figures