4777
Probabilistic Optimization of Cartesian k-Space Undersampling Patterns for Learning-Based Reconstruction1Institute for Biomedical Engineering, University and ETH Zurich, Zurich, Switzerland
Synopsis
Learning-based methods offer improved reconstruction accuracy for compressed Sensing MRI. However, most modern methods assume the sampling trajectory to be predefined. In order to further increase reconstruction quality, we present a method for adaptive design of Cartesian undersampling masks. The proposed method delivers sampling trajectories that allow to improve reconstruction accuracy by 26% and 6% compared to the random and state-of-the-art interleaved variable density patterns, respectively.
Introduction
The choice of the undersampled (US) k-space trajectory has been shown to have a prominent effect on reconstruction accuracy for standard [1] and machine learning (ML) based compressed sensing (CS) methods [2]. Optimization of the k-space sampling trajectory for nonlinear reconstruction was approached by Seeger et al. in [3] from a Bayesian model selection perspective, employing Laplace approximation of the evidence around the maximum a posteriori solution. However, most ML reconstruction algorithms are designed to recover the mean or the mode of the posterior, where Laplace approximation does not hold. Given evident improvements in reconstruction accuracy and speed provided by ML approaches [4], trajectory optimization techniques for such algorithms are highly desired. In this work we consider optimization of probabilistic sampling via Gumbel-Softmax approximation [5] as a strategy to k-space trajectory design. Being inherently stochastic, our approach allows to leverage information from large datasets. Experiments on dynamic cardiac cine MRI demonstrate that both acquisition noise and image regularities are regarded.Methods
ML based approaches for image reconstruction involve minimization of the reconstruction error on the training set $$$\mathcal{T}$$$ w.r.t. parameters $$$\Theta$$$ of the reconstruction network $$$\mathcal{V}_\Theta(\mathbf{z},\mathbf{m})$$$ that maps input k-space $$$\mathbf{z}$$$ to image $$$\mathbf{x}$$$, given a binary undersampling mask $$$\mathbf{m}$$$. Formally, to optimize undersampling patterns, one can evaluate gradients of the reconstruction error w.r.t. the US mask and employ continuous relaxation of the mask sparsity measure, e.g. the L1-norm $$$\|\mathbf{m}\|_1$$$. However, our initial experiments show that such strategy fails to find sparse solutions, preferring fractional values of $$$\mathbf{m}$$$ that cannot be used to select the optimal US pattern.
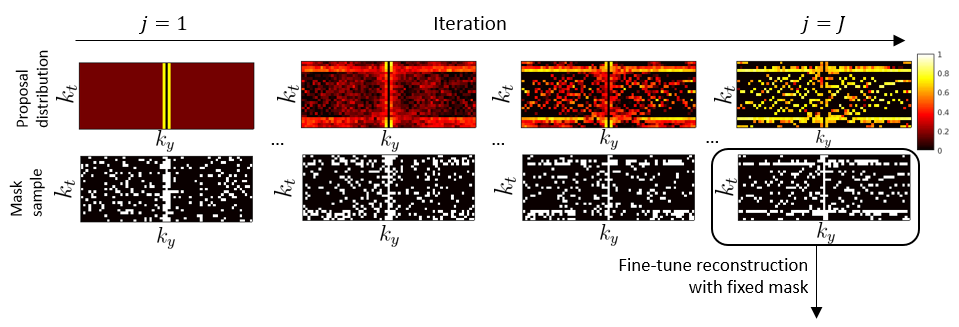
Instead, we propose a probabilistic relaxation by assuming that the k-space sample $$$z_i$$$ is acquired with probability $$$\sigma(l_i)=1/(1+\exp(-l_i))$$$, yielding a Bernoulli distribution $$$\mathcal{B}(\sigma(l_i))$$$ of the proposed US masks. The target sampling rate $$$r$$$ poses constraints on logits $$$l_i$$$ that are optimized w.r.t. reconstruction accuracy:$$\min_{l_i}\mathop{\mathbb{E}}_{\{m_i\sim\mathcal{B}(\sigma(l_i))\}_{i\leq N_p}} \min_{\Theta} \mathop{\mathbb{E}}_{\mathbf{x}^\text{gt},\mathbf{z} \in\mathcal{T}} \|\mathcal{V}_\Theta(\mathbf{m}\odot\mathbf{z}, \mathbf{m})-\mathbf{x}^\text{gt}\|_1,\quad\text{s.t.} \sum_{i\leq N_p}\sigma(l_i)=N_pr.$$ In the discrete case, optimization of sampling parameters $$$l_i$$$ is extremely challenging. Therefore, we employ the recently proposed approach based on Gumbel distributed differentiable straight-through samples [5]. The algorithm is summarized in Figure 1 and can be seen as optimization of inference network $$$\mathcal{V}_\Theta$$$ weighted by Gumbel samples, followed with a projection step to enforce the desired sampling rate $$$r$$$.
In all experiments we use variational networks $$$\mathcal{V}_\Theta(\mathbf{z},\mathbf{m})$$$ described in [4, 6] with 9 layers, each containing 35 filters of size $$$5^2$$$ and $$$5^3$$$ pixels for 2D and 2D+t datasets, respectively.Each filter is accompanied by a potential function parametrized by linear interpolation of 31 values placed on an equidistant grid. For proposal US mask optimization we use a fixed sampling rate of $$$r=0.20$$$, and perform $$$J=10\cdot10^4$$$ optimization steps, while optimization w.r.t. $$$\Theta$$$ and $$$\{l_i\}_{i=1}^{N_p}$$$ was performed with the Adam algorithm [7] and learning rate of $$$10^{-3}$$$.The center of the k-space was always sampled.
Dynamic 2D cardiac MRI datasets were acquired on 1.5 and 3T systems (Philips Healthcare, Best, The Netherlands) with pixel size of 1.4x1.4x8 mm$$$^3$$$ and 25 dynamics, yielding 375 short-axis scans downsampled to $$$65\times65\times25$$$ pixel grid. Random smooth phase information was retrospectively added to images and single receiver coil is assumed to model data acquisition with Cartesian k-space trajectory.
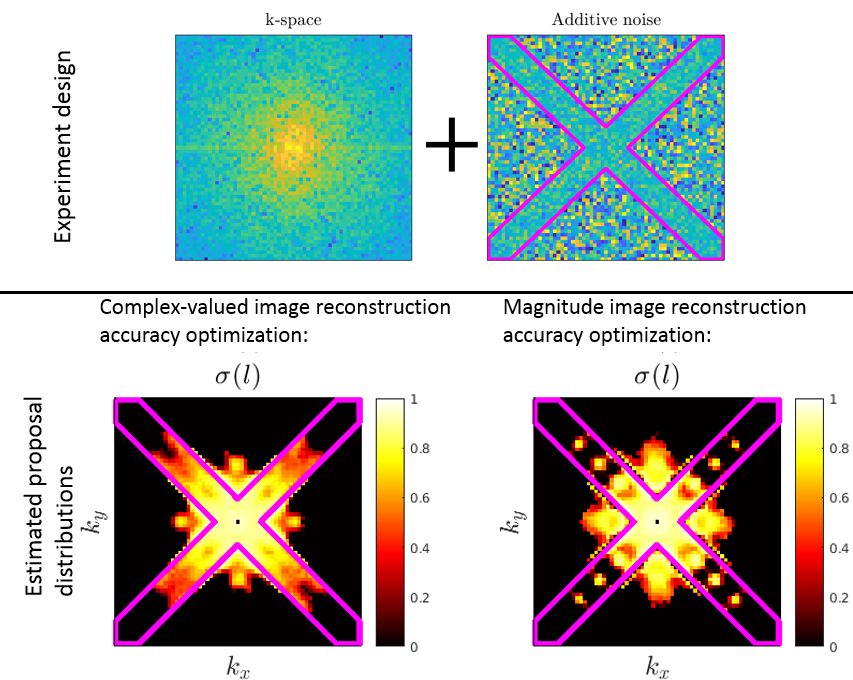
In 2D reconstruction experiments we retrospectively add inhomogeneous Gaussian noise to k-space, as illustrated in Figure 2. The US mask is optimized for reconstruction in terms of complex and magnitude image reconstruction error.
For 2D+t reconstruction experiment we perform US mask optimization in the spatiotemporal Fourier domain $$$t\text{-}k_y$$$ on noise-free k-space data. In practice, the variance of the proposal distribution reduces during optimization, since fixed US masks introduce predictable aliasing patterns that are easier to be filtered out by the network. Therefore, we perform fine-tuning of $$$\mathcal{V}_\Theta$$$ on a single sample from optimal proposal distribution $$$\mathcal{B}(\sigma(t^\star_i))$$$, as illustrated in Figure 3.
Results
Our method could successfully reveal the underlying noise distribution in the k-space as can be seen in Figure 2. Moreover, we hypothesize that magnitude-tuned reconstruction pattern lead to a higher sampling rate at high frequencies, since low-frequency phase components are dismissed.
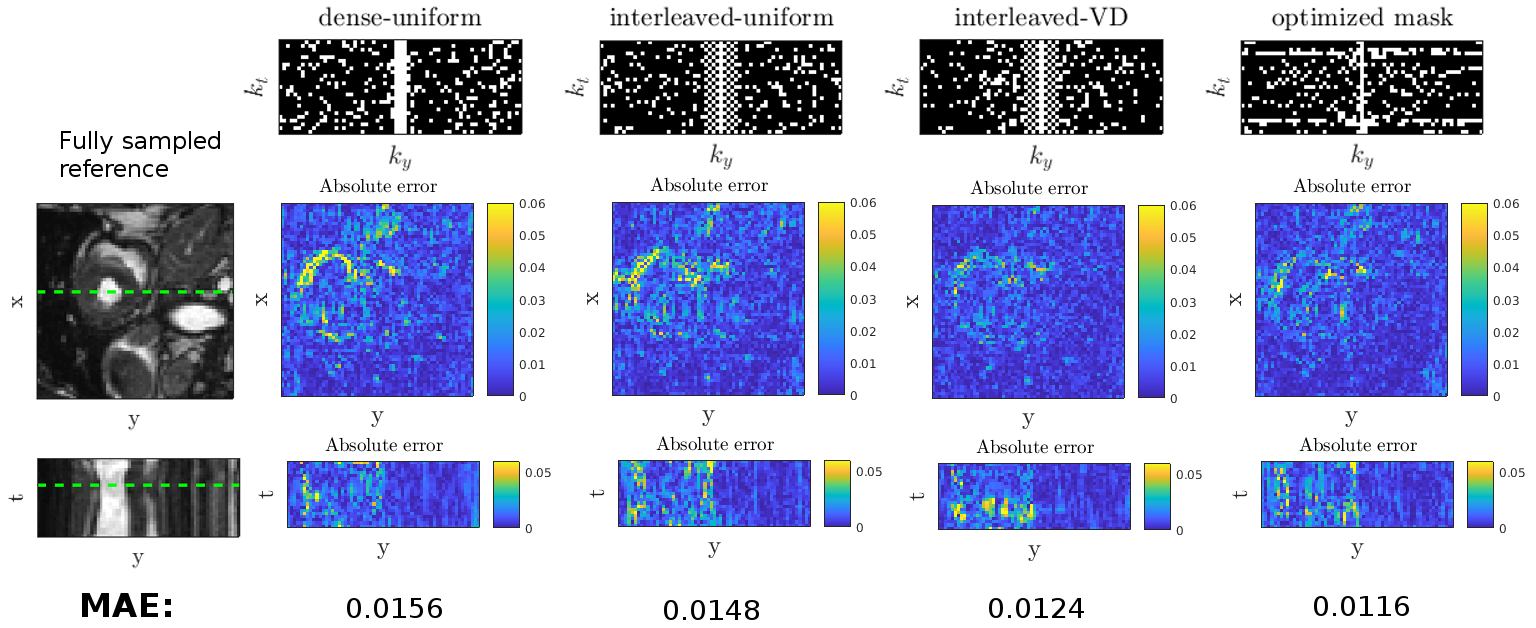
The k-space trajectories for 2D+t reconstruction were compared against combinations of dense, interleaved and random US patterns summarized in Figure 4. The manually designed interleaved US pattern with variable sampling density improves reconstruction accuracy over random patterns by 20%, while the proposed optimized mask further improves accuracy by 6% without using any expert knowledge.
Conclusion
In this work, we have presented a stochastic method for k-space trajectory optimization with learning-based reconstruction. The proposed approach recovered US masks that allowed to improve reconstruction accuracy of learned reconstruction networks by 6%. Moreover, the method was shown to select informative k-space sample positions.Acknowledgements
The authors acknowledge funding from the European Union’s Horizon 2020 research and innovation programme under grant agreement No 668039.References
[1] Johannes Schmidt, Claudio Santelli, and Sebastian Kozerke. Optimized k-t Sampling for Combined Parallel Imaging and Compressed Sensing Reconstruction. Proc. Intl. Soc. Mag. Reson. Med. 22, 2014.
[2] Florian Knoll, Kerstin Hammernik, Erich Kobler, Thomas Pock, Michael Recht, and Daniel K Sodickson. Assessment of the generalization of learned image reconstruction and the potential for transfer learning. MRM, 2018.
[3] Matthias Seeger, Hannes Nickisch, Rolf Pohmann, and Bernhard Scholkopf. Optimization of k-space trajectories for compressed sensing by Bayesian experimental design. MRM, 2010.
[4] Kerstin Hammernik, Teresa Klatzer, Erich Kobler, Michael Recht, Daniel Sodickson, Thomas Pock, and Florian Knoll. Learning a variational network for reconstruction of accelerated MRI data. MRM, 2018.
[5] Eric Jang, Shixiang Gu, and Ben Poole. Categorical reparameterization with Gumbel-Softmax. arXiv preprint arXiv:1611.01144, 2016.
[6] Valery Vishnevskiy, Sergio Sanabria, and Orcun Goksel. Image reconstruction via variational network for real-time hand-held sound-speed imaging. MLMIR, 2018.
[7] Diederik P Kingma and Jimmy Ba. Adam: A method for stochastic optimization. arXiv preprint:1412.6980, 2014.
Figures