4772
A Deep Learning Accelerated MRI Reconstruction Model's Dependence on Training Data Distribution1Spinoza Centre for Neuroimaging, Netherlands, Netherlands, 2Department of Radiation Oncology, the Netherlands Cancer Institute & Spinoza Centre for Neuroimaging, Amsterdam, Netherlands, 3Spinoza Centre for Neuroimaging, Amsterdam, Netherlands, 4Department of Radiation Oncology, the Netherlands Cancer Institute, Amsterdam, Netherlands, 5Academic Medical Center, Amsterdam, Netherlands
Synopsis
Recurrent Inference Machines (RIM) are deep learning inverse problem solvers that have been shown to generalize well to anatomical structures and contrast settings it was not exposed to during training. This makes RIMs ideal for accelerated MRI reconstruction, where the variation in acquisition settings is high. Using T1- and T2*-weighted brain scans and T2-weighted knee scans, we compare the RIM's performance when trained on only a single type of data against the case where all three data types are present in the training set. We present results that show an overall model robustness, but also indicate a slight preference for training on all three types of data.
Introduction
Deep learning has made large advances in recent years on the problem of reconstructing sparsely sampled MR-images, and can now be considered viable alternatives or extensions to compressed sensing [1, 2, 3]. However, there is an issue of data generalization, as it is challenging to have the training procedure account for the many different acquisition settings and anatomies that are encountered in the lab or a clinical setting. Recurrent Inference Machines (RIM) [4] have been shown to handle data from distributions that are absent in the training set relatively well, leading to only slight degradation in reconstruction quality [1]. In this work, we expand on our analysis of the RIM’s performance by quantifying the effect of having more than one data type represented in the training set.Methods
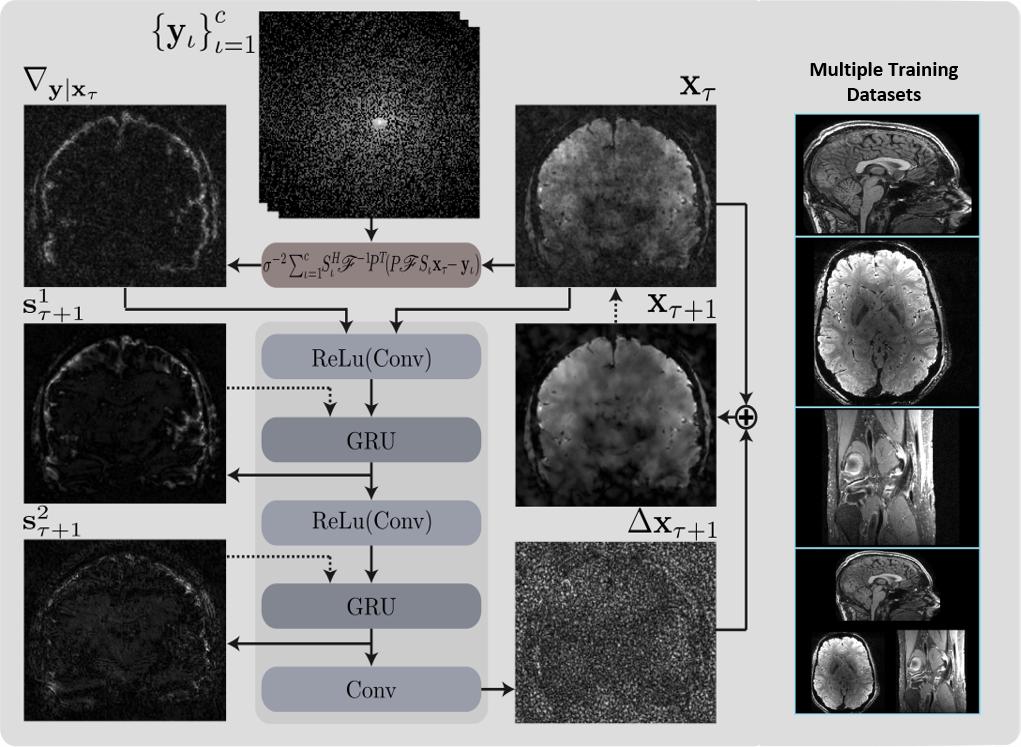
RIMs are recurrent neural networks, where each step produces a new estimate of the final reconstruction. This estimate is fed as input to the next step, enabling the model to evaluate its own estimate of a prior distribution gradient with respect to this reconstruction state. Since the log-likelihood is known analytically from the MR-data acquisition process, its gradient with respect to the current reconstruction is given explicitly as another input. In this way, the model learns to find a reconstruction in agreement with the maximum a posteriori objective. The recurrent unit consists three convolutional layers interleaved by two Gated Recurrent Units (GRU) [5], as shown in Figure 1. We used the mean square error averaged over 8 recurrent steps as a loss function.
We used three types of data: 12 subjects underwent brain scans on two systems; one Philips 7T scanner with a 32-channel head coil, using a 3D T2*-weighted 6-echo FLASH protocol at a 0.7mm resolution, with a scan time of 22 minutes, and; one Philips 3T scanner with a 32-channel head coil, using a 3D T1-weighted MPRAGE protocol at 1.0mm resolution, with a scan time of 10 minutes. The third data type was taken from [6], which contains 20 knee scans acquired on a GE 3T scanner with a 8-channel knee coil, using a T2-weighted FSE protocol at 0.5-0.6mm resolution, with a scan time of 15 minutes. We used 2 subjects for validation and testing, and the remaining subjects for training.
We trained 4 RIMs, three of which were trained separately on the three types of data, whereas the final model was trained on all three types of data combined. For this training procedure, we made sure to sample an equal ratio of datapoints from the three distributions. The models to evaluate were picked based on the performance on the validation sets, and these were then cross-evaluated on the test sets of all three data types.
Results & Discussion
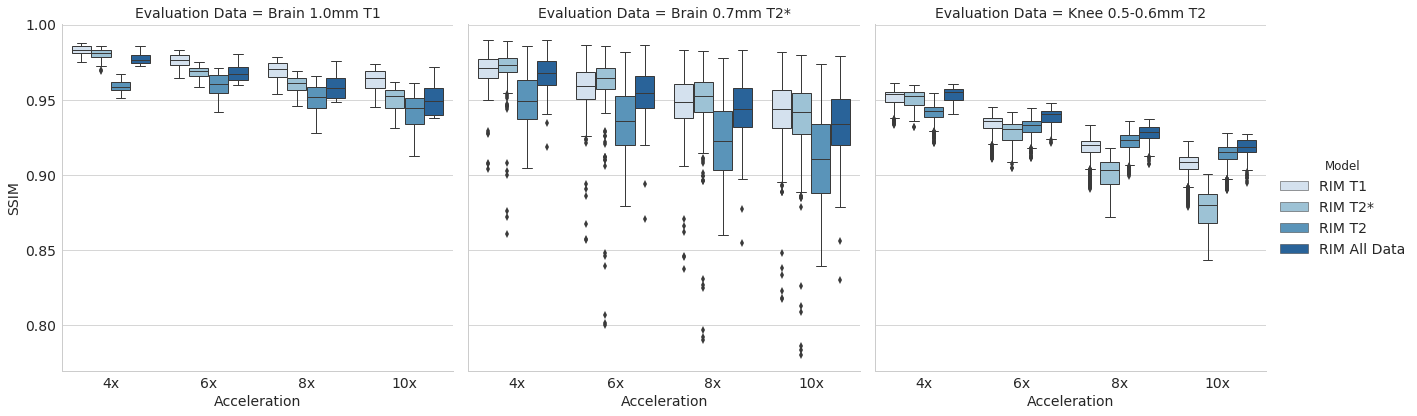
Figure 2 shows the structural similarity (SSIM) of the four models’ reconstructions to the fully sampled images in the test sets.
For T1- and T2*-weighted brains, our results indicate a small negative impact caused by the presence of T2-weighted knees in the training set. A larger improvement is seen when compared to the model trained on knees only.
Examining the case of reconstructing T2-weighted knees, there is a positive effect from using a broader training data distribution, where the model exposed to knees and brains is doing better than the model only trained on knees. This counter-intuitive result warrants further investigation, but we hypothesize that the model trained on only knees is struggling due to the acquisition sequence. Relative to the real-valued image component, the complex-valued image component is close to zero nearly everywhere, perhaps leading to less learning stimulus for parameters assigned to the complex image channel.
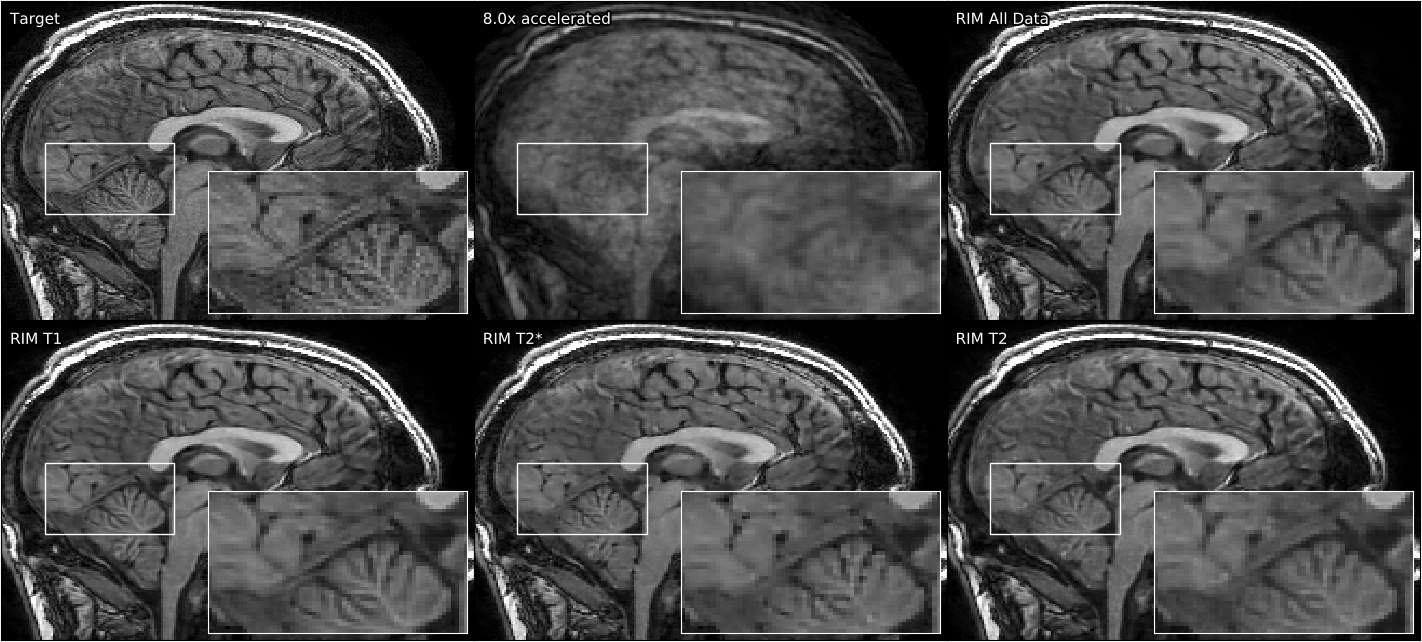
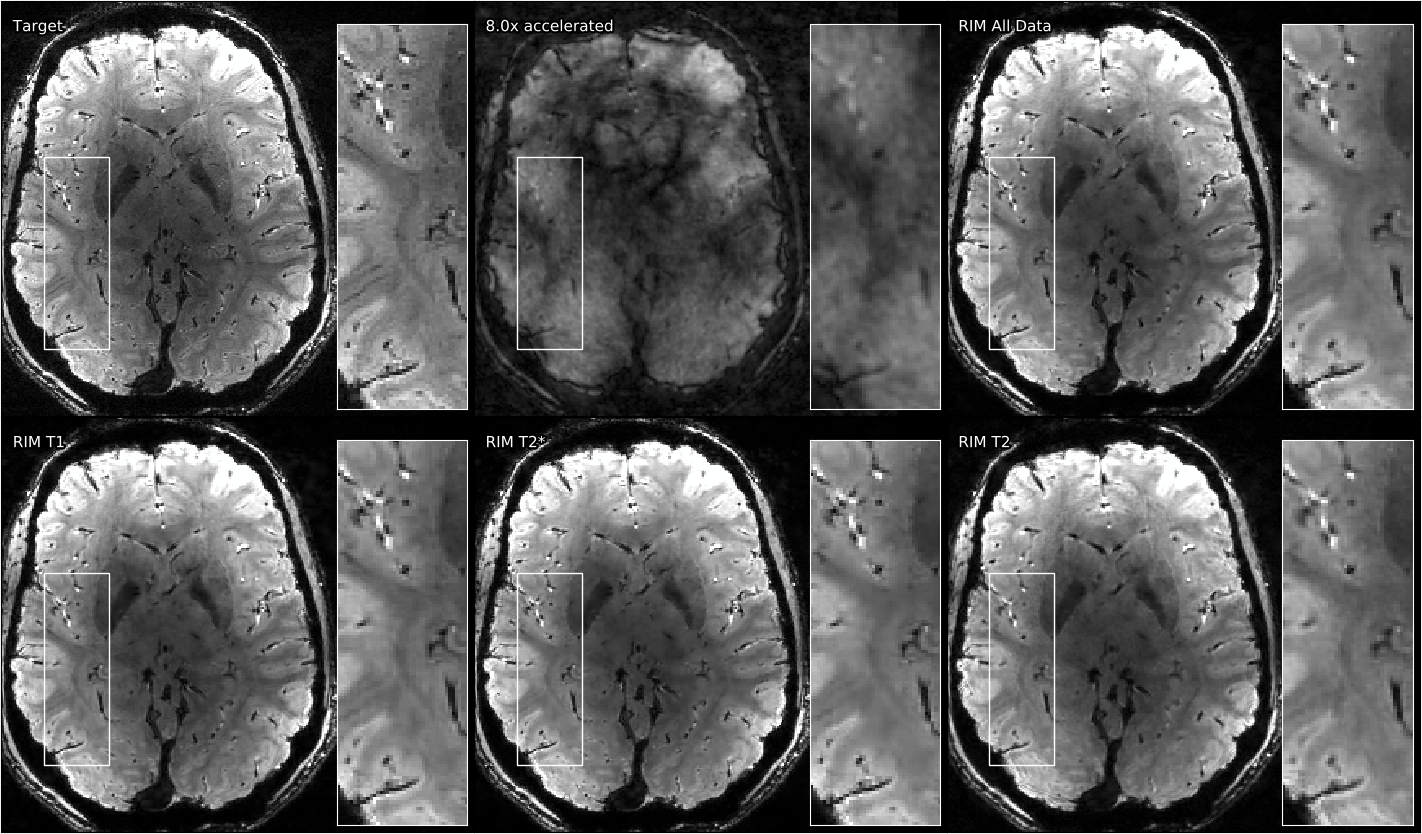
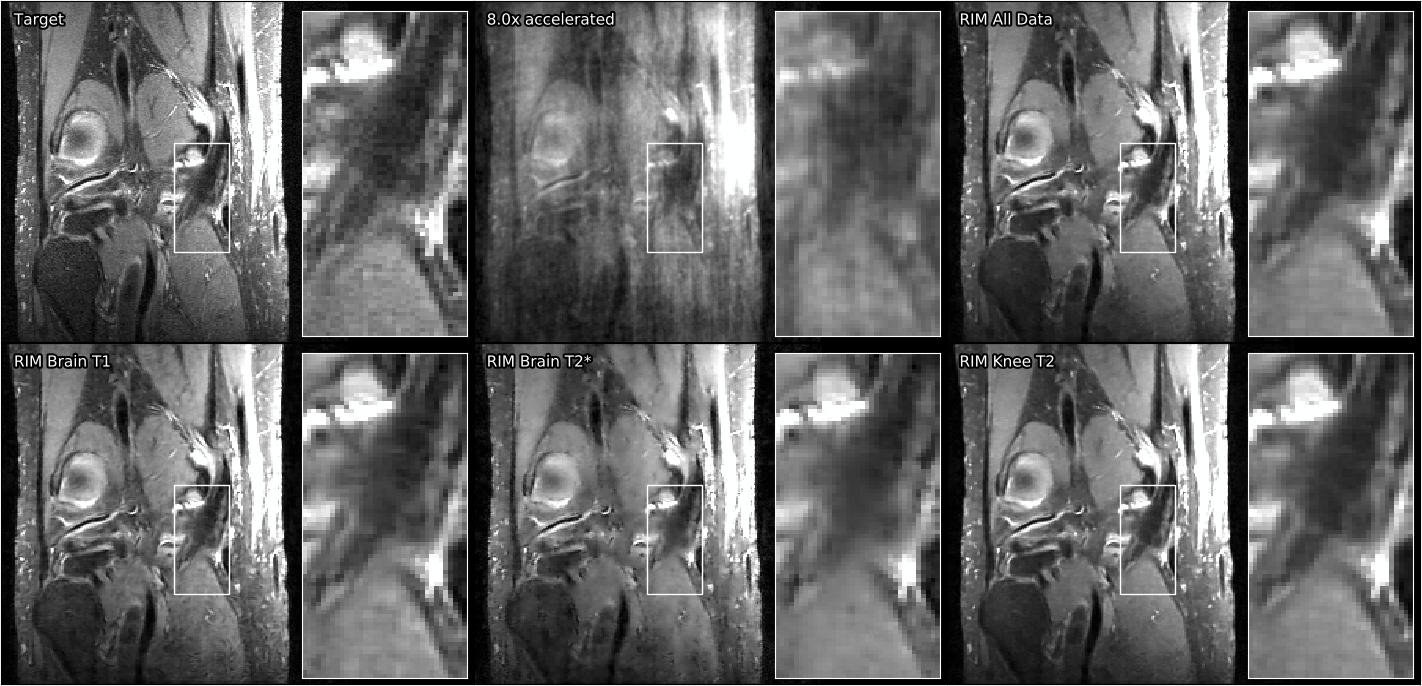
Qualitative results on all three datasets can be seen in Figures 3, 4, and 5. The performance difference is difficult to perceive with the eye, but a notable exception can be seen in Figure 5: The model trained on T2*-weighted brain images is struggling to reconstruct T2-weighted knee data, creating smudged boundaries.
Conclusion
RIMs are robust to changes in the input data, both with respect to the scan sequence and the underlying anatomy. No cases were seen where the model suffered significantly from being exposed to too many types of data during training, but we did identify a case where the performance was visibly inferior when a model was evaluated on a type of data not included during training. Further research is required to verify whether more data actually improves the RIM's ability to generalize to additional types of data, or if the performance benefit is restricted to the same type of data it was trained on.
Acknowledgements
No acknowledgement found.References
1. Lønning K., Putzky P., Caan M.W.A., Welling M. Recurrent Inference Machines for Accelerated MRI Reconstruction, MIDL 2018.
2. Hammernik K., Klatzer T., Kobler E., Recht M. P., Sodickson D. K., Pock T., Knoll F. Learning a variational network for reconstruction of accelerated MRI data. Magnetic Resonance in Medicine 79 (6), 3055–3071, 2018.
3.Yang Y., Sun J., Li H., Xu Z. ADMM-net: A Deep Learning Approach for Compressive Sensing MRI. arXiv abs/1705.06869, 2017.
4. Putzky P., Welling M. Recurrent Inference Machines for Solving Inverse Problems. arXiv:1706.04008, 2017.
5. Cho K., van Merrienboer B., Gulcehre C., Bahdanau D., Bougares F., Schwenk H., Bengio Y., Learning Phrase Representations using RNN EncoderDecoder for Statistical Machine Translation. In: Empirical Methods in Natural Language Processing (EMNLP) conference 2014. Association for Computational Linguistics, Stroudsburg, PA, USA, pp. 1724–1734.
6. Epperson K, Sawyer AM, Lustig M, Alley M, Uecker M. Creation Of Fully
Sampled MR Data Repository For Compressed Sensing Of The Knee. In:
Proceedings of the 22nd Annual Meeting for Section for Magnetic
Resonance Technologists, Salt Lake City, Utah, USA, 2013.
Figures