4770
Crowdsourced Quality Metrics for Image Reconstruction using Machine Learned Ranking1Medical Physics, University of Wisconsin - Madison, Madison, WI, United States, 2Radiology, University of Wisconsin - Madison, Madison, WI, United States, 3Radiology, University of California - San Francisco, San Francisco, CA, United States
Synopsis
In this work, we investigate a scheme for crowd sourcing image quality using machine learned metrics from user rankings of corrupted images. Using an HTML application, experienced observers ranked pairs of corrupted images with respect to image quality. A convolution neural network (CNN) was then trained to produce a quality score that was higher in the preferred images. The trained CNN was found to be more sensitive to artifacts from image blurring and wavelet compression than mean square error. Finally, preliminary use in training a machine learned image reconstruction is demonstrated.
Introduction
Machine learning can be used to create k-space to image neural network (NN) transformers which minimize image quality loss over a set of examples1-3. Such transformers require a performance metric to set what information can be lost across the reconstruction (e.g. noise, distortions), and what information must be retained (e.g. contrast, resolution). Common performance metrics are the mean squared error (MSE) or structural similarity (SSIM) of reconstructed images with a ground truth; however, it is well known that these metrics are often poor reflections of radiologic image quality. It would be preferred to train NN transformers for diagnostic tasks, either radiologist interpreted or machine learned. In this work, we investigate a scheme for crowd sourcing image quality using a machine learned metric from user rankings of corrupted images.Methods
Image Corruption: 3D complex, coil combined, T1 weighted brain structural images from 15 subjects were used to create 7,500 2D image pairs in the axial, sagittal, and coronal planes. For each pair, images were transformed to k-space, randomly undersampled (1-1.25x), apodized with a random Gaussian kernel (sigma=0-2kmax), and randomly wavelet compressed (0-50%). Images were scaled to minimize the MSE with the input, ground truth image, and saved as floating point complex values and as portable graphics format. Images were window leveled automatically using the central quarter of the image.
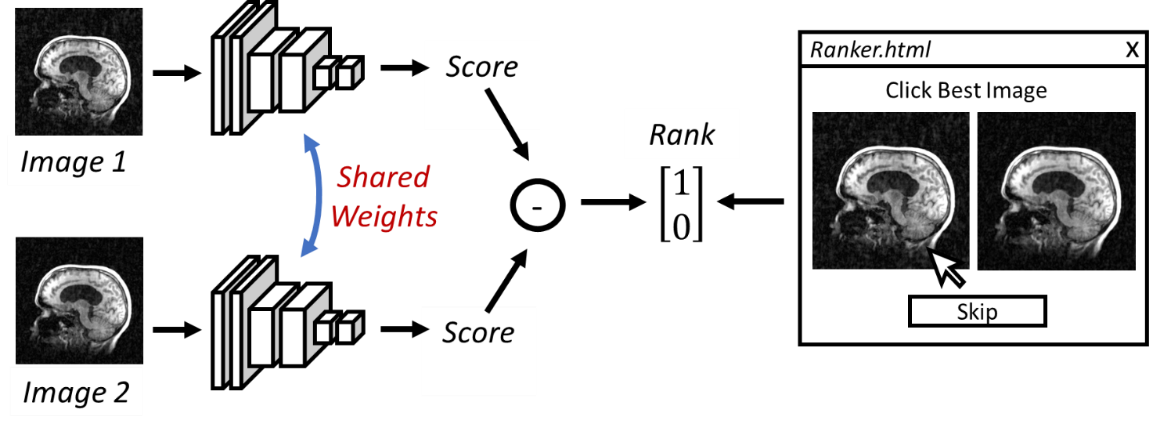
User Ranking: Image pairs were presented side by side to users experienced in evaluating T1 structural images in an HTML application, as shown in Figure 1. For each pair, users were asked to select the best image or skip the pair if the images were too similar to distinguish. Image pairs were selected at random from the database with repeated evaluation allowed.
Imaging Metric RankNet: To derive a quality metric, image pairs were fed to a RankNet4 based training schema shown in Figure 1. Each image is independently passed through a convolutional neural network (CNN) which aims to output a quality score. The quality scores are then subtracted and sigmoid activated to provide a rank preference. The CNN is trained using user ranks and cross entropy loss, augmentation, and 0.9/0.1 validation split. In this work, we used a ResNet architecture with few base filters (16) and bottlenecks per loop (2).
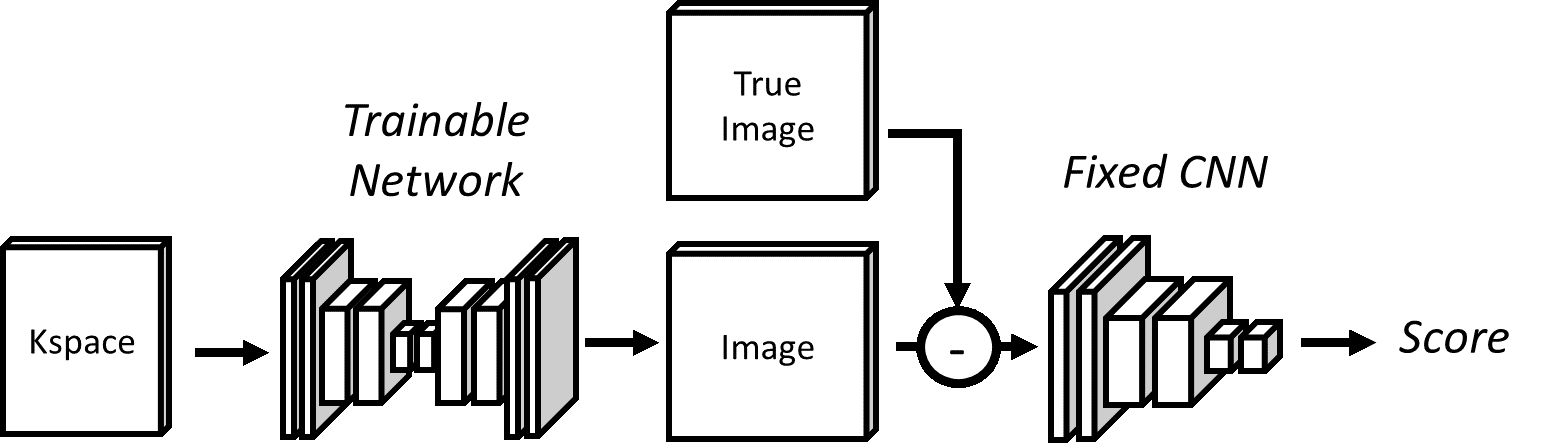
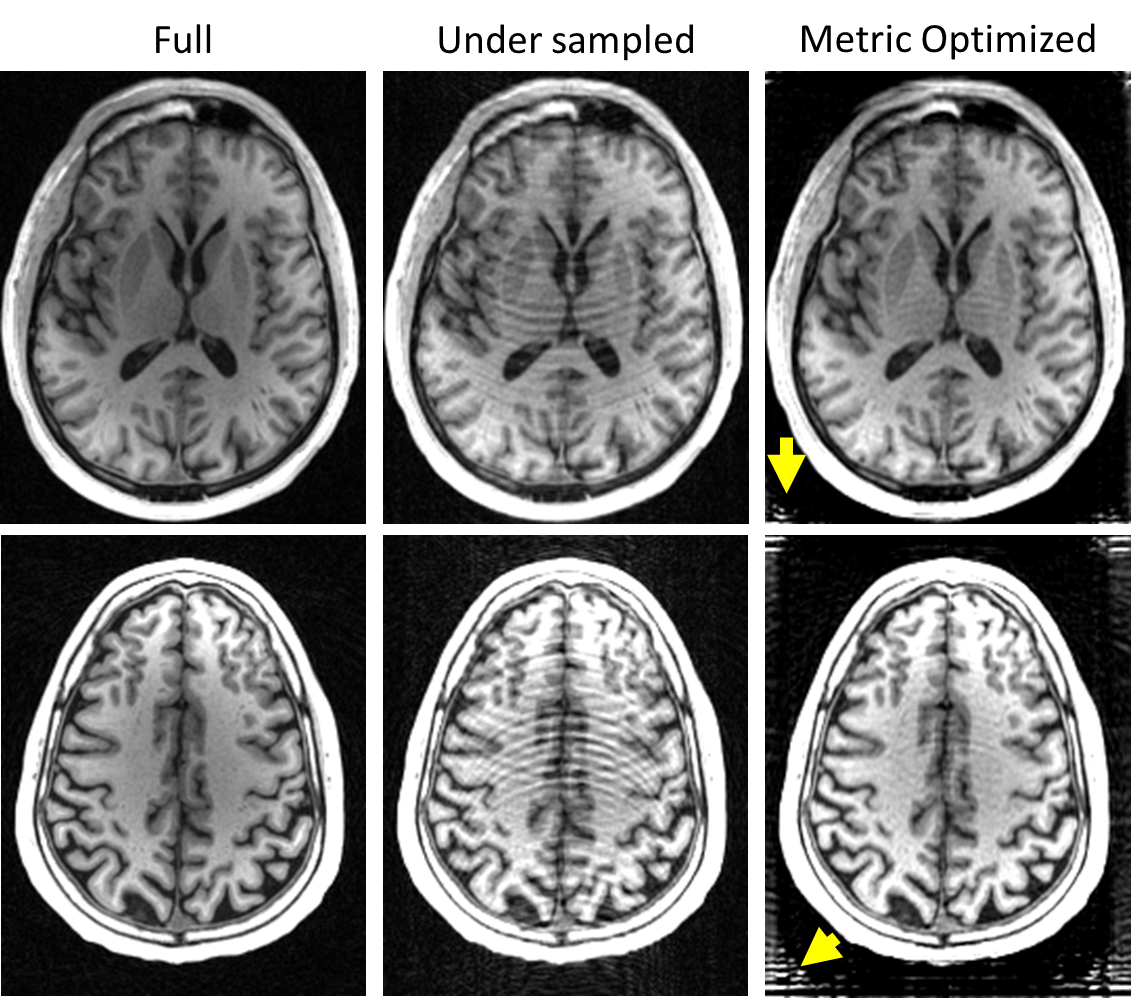
Analysis and use in Reconstruction: To investigate the effect of image corruptions, CNN image quality scores and MSE were computed and compared in a 1,000 images blurred with a Gaussian kernel, randomly undersampled in k-space, and compressed in the wavelet domain. As proof of concept, the CNN image quality was also used in a neural network image reconstruction based on 1D Fourier undersampling, and a network consisting of 2 partially fully connected layers (connected in only 1D) followed by a 3 layer CNN. Images were trained using the CNN metric as the loss function as shown in Figure 2.
Results
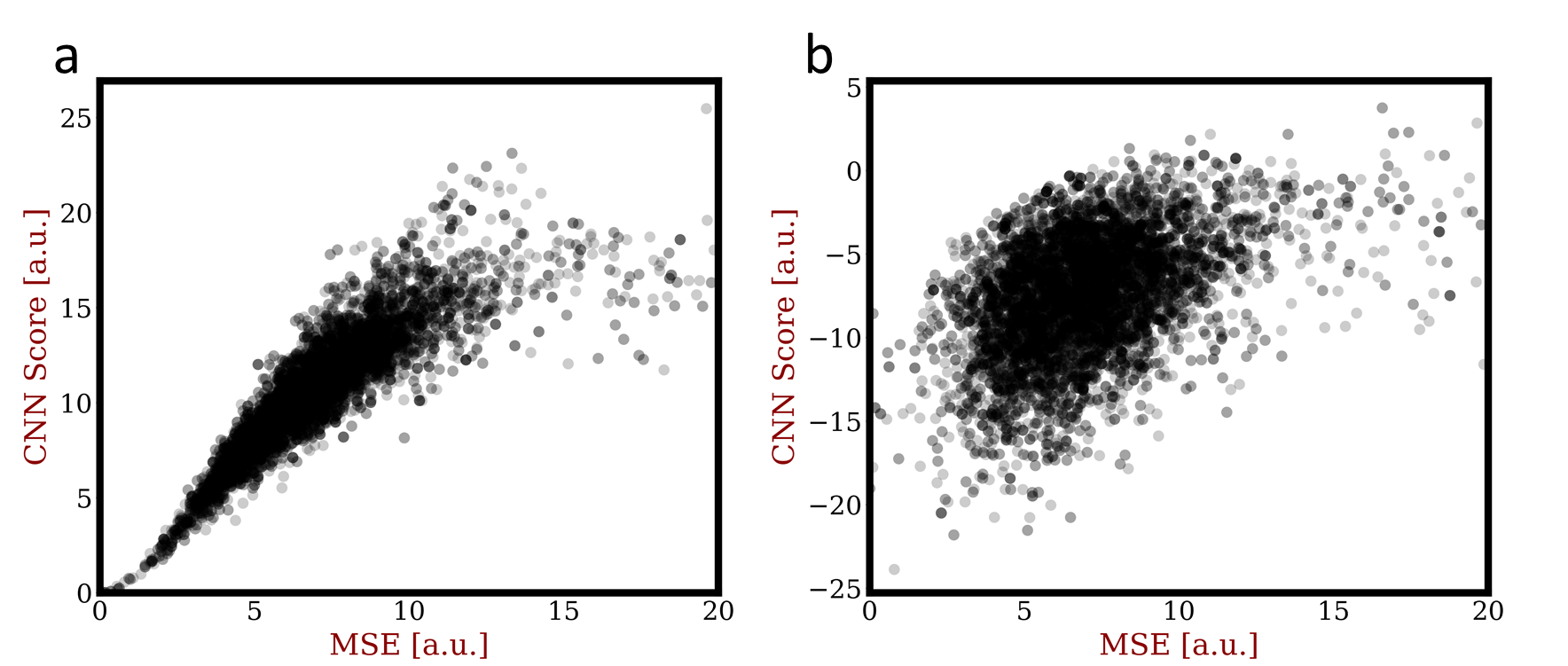
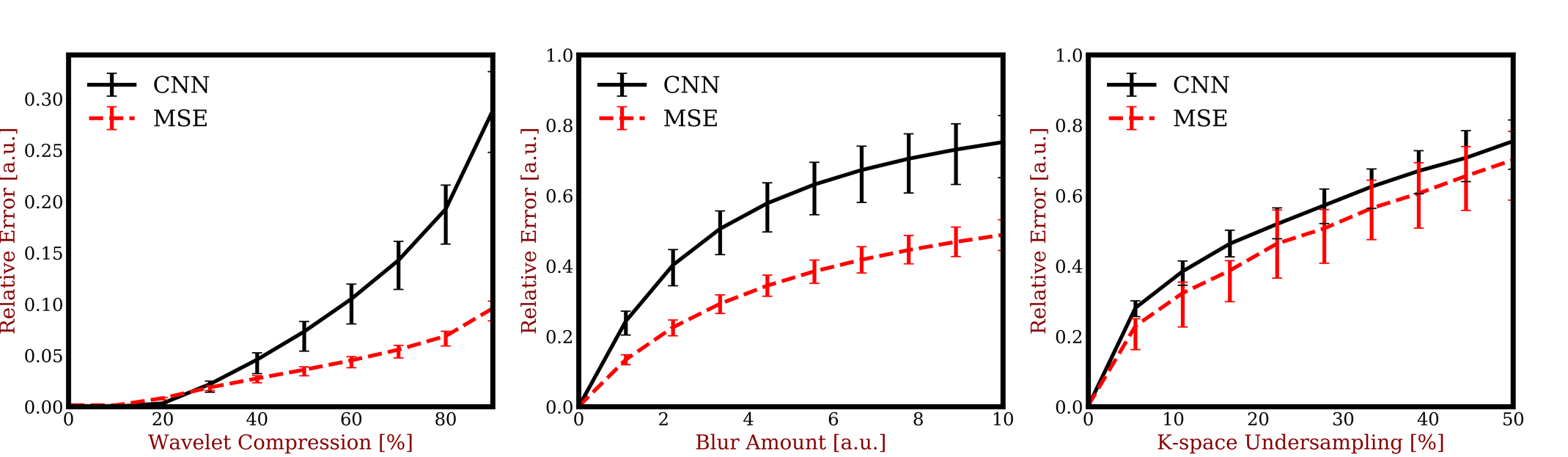
Users provided a total of 4,075 image rankings. Repeated rankings by the same observer occur in 230 images with agreement in 88% of repeated viewings. Over 5-fold cross validation, the trained CNN rank prediction accuracy was 86.4±1.3% with subtraction, 84.2±1.9% with raw images, and 85.3±0.7% using MSE. Figure 3 shows a scatter plot of MSE in the test data set using a CNN trained on images differences and raw images without the ground truth. With subtraction, the agreement is error dependent with minimal differences at low MSE and increasing spread with increasing error. This is consistent with differential preferences for image quality, which as shown in Figure 4 is different. The user derived CNN is relatively more sensitive to blurring and to higher levels of wavelet compression. Figure 5 shows image reconstructions using the CNN showing a high level of detail preservation. Interestingly, image errors are prevalent at the edges of the field of view where the padded images typically had no signal.Discussion & Conclusion:
In this study, we devised an experimental setup to probe human preferences of image corruption using preferential ranking and used that data to train a CNN based quality metric. Image quality ranking is significantly more sensitive than subjective scoring and is also less taxing on observers. Using RankNet based learning allows conversion of ranks to a quantitative score which enables comparison of images never directly ranked or seen by the observer. This is particularly important for use in image acquisition and reconstruction learning tasks which all require a high number of quality ranks. Further work is needed to explore the task and observer dependency of the scoring and the resulting CNNs.Acknowledgements
We gratefully acknowledge research support from GE Healthcare and Nvidia, and funding support from NIH grants R01NS066982 and R01HL136965.References
1. Zhu B, Liu JZ, Cauley SF, et al . Image reconstruction by domain-transform manifold learning. Nature. 2018;555(7697):487-92.
2. Hammernik K, Klatzer T, Kobler E, et al. Learning a variational network for reconstruction of accelerated MRI data. Magn Reson Med. 2018;79(6):3055-71.
3. Yang G, Yu S, Dong H, et al. DAGAN: Deep De-Aliasing Generative Adversarial Networks for Fast Compressed Sensing MRI Reconstruction. IEEE Trans Med Imaging. 2018;37(6):1310-21.
4. Burges CJC, Shaked T, Renshaw E, et al. Learning to Rank using Gradient Descent. Proceedings of the Twenty Second International Conference on Machine Learning; 2005.
Figures