4763
Efficient MR Image Compression using Deep Learning Models for Multi-contrast MRI1Subtle Medical, Menlo Park, CA, United States, 2Electrical Engineering, STANFORD UNIVERSITY, Stanford, CA, United States, 3Computer Science and Mathematics, University of California, San Diego, San Diego, CA, United States
Synopsis
As more and more medical imaging dataset is created, efficient and high-rate data compression is in demand for applications such as data transfer, storage and cloud based MR image analysis. However, conventional compression options do not provide the efficiency and compression performance needed for real-time applications such as image query and computer-aided diagnosis. In this work we demonstrated the applicability of the DL based compression algorithm for MRI to improve the compression performance and efficiency. Trained on natural images and fine-tuned on multi-contrast brain MRI, the proposed method provide significantly (~2x) higher compression rate compared with conventional method. Additionally, the end-to-end deep learning compression/de-compression is also several magnitude's faster than conventional methods. This technique can directly benefit industrial and clinical applications, and can provide new model in applications such as multi-contrast fusion and reconstruction.
Purpose
With increasingly more accessible medical imaging exams, the medical imaging data is exploding. Effective and efficient medical imaging data compression can lead to cheaper storage, faster transfer and more efficient data query. This is also important for increasing adoption of cloud based image analytics and computer-aided diagnosis (CAD) applications. Currently, the speed and performance of general image compression algorithm still limit the adoption of data compression in clinical applications that requires real-time performance. An intelligent algorithm is needed to further improve data compression performance and speed to benefit real applications in hospitals.
Recently, several Deep Learning (DL) based image compression algorithms [1,2,3] are proposed to further push the limit of compression rate and efficiency by exploiting DL based nonlinearity. This work demonstrates the applicability of the DL based compression algorithm for MRI to improve the compression performance and efficiency.
Method
Deep Learning Model
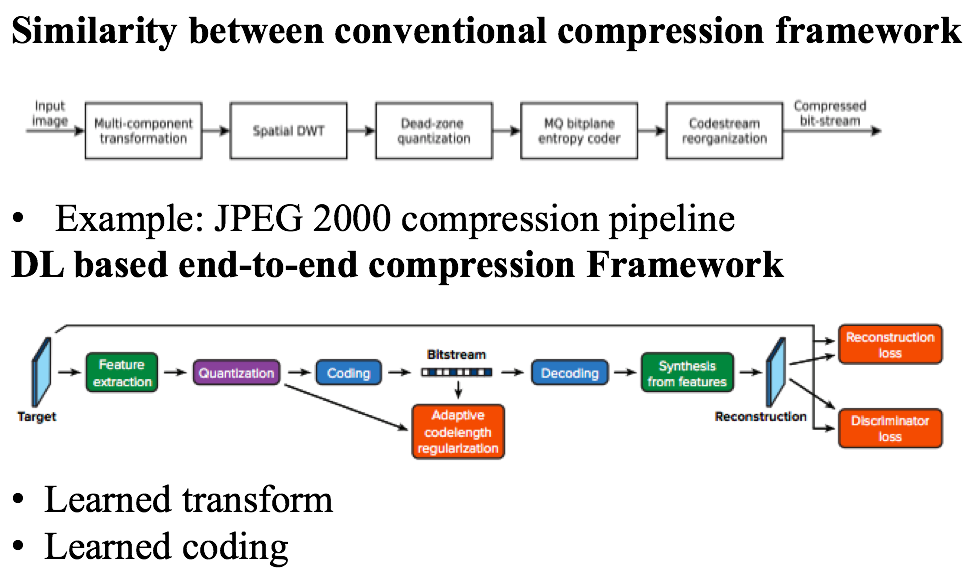
Network architecture for DL based image compression is shown in Figure. 1. A compression and a decompression network are used for end-to-end image compression framework. For each network, 4 ResNet blocks (feature-map numbers increase 1->32->64->128 then reduced 128->64->32->1) with ELU activation function were used. Sigmoid activation layer is added after compress-net to output values from 0 to 1 which is transferred into coding and compressed using GZIP [4] to generate the final compressed file. The decompression step is first to unzip the GZIP file using GZIP-DEFLATE algorithm and then map the coding back to image domain using decompress-net.
Dataset and preprocessing
Two set of datasets were used in training the network. Firstly, the network was trained using Cifar-10 natural image dataset which contains 60,000 natual images (32x32) for object classification tasks. The images were converted into grayscale before training. Secondly, the network was fine-tuned using 2D-FSE multi-contrast brain MRI dataset, which includes 9996 MR images (512x512) from 6 contrasts (T1w, T2w, PDw, T1FLAIR, T2FLAIR, STIR). The acquisitions were performed at 3T scanners (GE Healthcare Systems, Waukesha, WI) with 8-channel GE head coils. All the images are normalized based on max value to scale to 0~1.
Enforce sparse coding
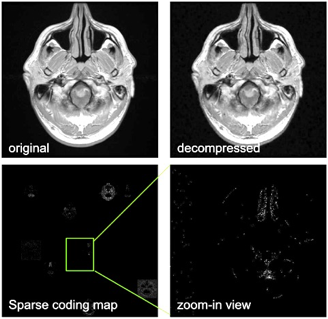
To ensure the network generate sparse code that is easier to quantize, random Gaussian noises are added. This noise component push the trained compress-network to output values that have large absolute values, such that they are robust to noises. As a result, the coding after the Sigmoid layer becomes very close to 0 or 1 which can be easily binarized as sparse codes. Figure 2 shows an example of sparse coding results. The noise scale is setup with standard deviation of 6.0.
Training procedure and loss function
To regularize accurate decompression, a L1 content loss is used. In addition, we use adversarial loss [5] to enforce the visual quality and details. To enforce high compression rate, sparsity loss is used to enforce mean absolute loss of the binary code map. The overall loss function defines as $$$L_{mix}=L_{L1}+\lambda_{adv} L_{Adverserial}+\lambda_{sparsity} L_{Sparsity}$$$, in which the weights are empirically set up as 0.1 and 0.1. Adam operator with learning rate of 0.001 was used.
Results
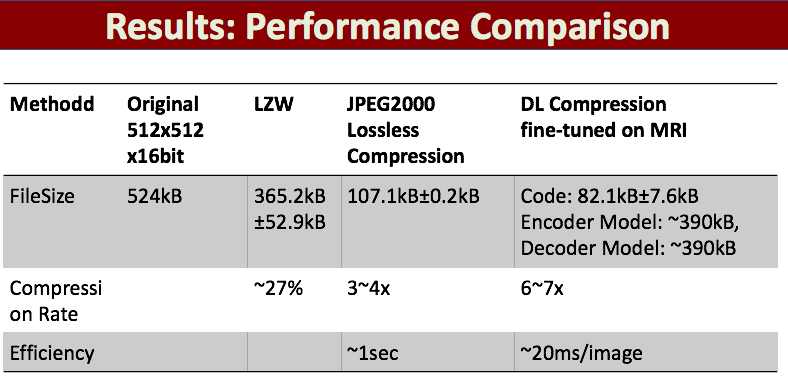
Experiments demonstrate the end-to-end compression algorithm works. As shown in Figure 2, it accurate reconstructs the images and generates sparse binary coding map. Comparing with existing compression algorithm, shown in Table 1/Figure 3, deep learning based results in accurate and more efficient (~20ms/image) compression with higher compression rate (6~7x). The model trained on natural images and then fine-tuned on MR images provides the best performance.Discussion and Conclusion
In this work, we implemented the deep learning based nonlinear image compression algorithm for MR image compression and further improved it by fine-tuning on MRI datasets. Experiments on multi-contrast brain datasets demonstrate the superior image compression capability and speed. The proposed algorithm shows great potentials for MRI applications, e.g. telemedicine and computer-aided diagnosis.Acknowledgements
No acknowledgement found.References
[1] Liu H, et.al. 2018
[2] Li M, et.al. 2017
[3] Toderici G, et.al. 2017
[4] Deutsch P, et.al. 1996
[5] Mardani M, et.al. 2018
Figures