4744
Fast dynamic speech MRI at 3 Tesla using variable density spirals and constrained reconstruction1Department of Biomedical Engineering, University of Iowa, Iowa city, IA, United States, 2Department of Communication Sciences and Disorders, University of Iowa, Iowa city, IA, United States, 3Department of Radiology, University of Iowa, Iowa city, IA, United States, 4Janette Ogg Voice Research Center, Shenandoah University, Winchester, VA, United States
Synopsis
We propose an ultra fast dynamic 3 T MRI scheme for imaging the vocal tract dynamics during speech production. Our approach synergistically exploits efficiency of variable density spirals for motion robustness, artifact suppression, and a sparse SENSE based temporal constrained reconstruction scheme. We realize time resolution of upto 6.2 ms/frame and a spatial resolution of 2.4x2.4 mm2. We demonstrate the utility of this scheme in capturing rapidly varying articulators during fast speech stimuli.
Purpose
Dynamic MRI (DMRI) of vocal tract shaping is emerging as a powerful tool to non-invasively characterize the human voice. However, DMRI has been challenged by intrinsic trade-offs amongst spatio-temporal resolutions, signal to noise, and slice coverage. Various accelerated 1.5 T and 3 T DMRI speech protocols have been proposed to improve image quality. These include the use of dedicated upper-airway coils [1], non-Cartesian acquisitions [2-6], and sparsity [3-5], low rank reconstruction constraints [7]. In this work, we develop a 3 T protocol based on a head and neck coil, variable density spirals, and temporal constrained reconstruction. We show that in comparison to uniform density spirals (UDS), variable density spirals (VDS) can effectively suppress artifacts from coil elements that are sensitive to spatial regions distant from vocal tract region of interest (eg. the head). We combine VDS with a sparse SENSE reconstruction scheme that exploits temporal finite difference sparsity. We demonstrate feasibility of DMRI of fluent speech at up to 6.2 ms/frame at a spatial resolution of 2.4 mm2.Methods
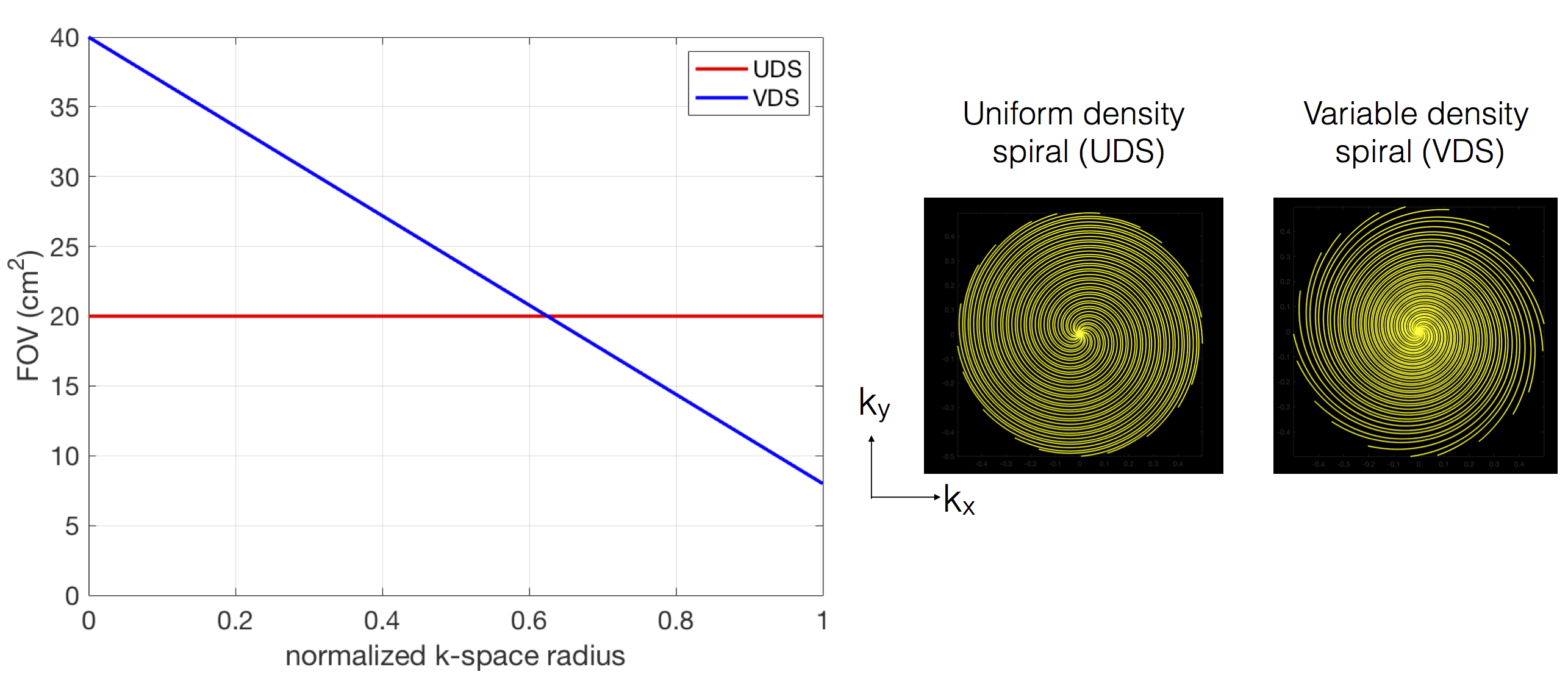
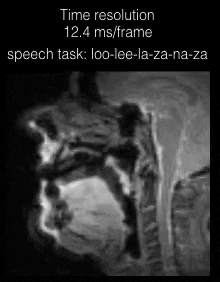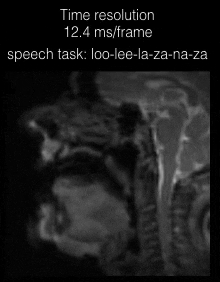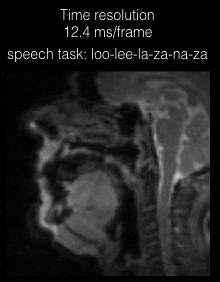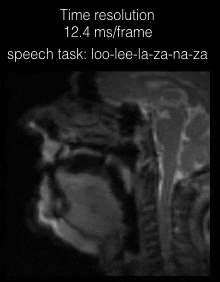
Experiments were performed on a GE-3 T 750 W MRI scanner with a 16 channel head and neck coil. Of the 16 channels, 6 channel elements which were most sensitive to important speech articulators (eg. the lips, tongue, velum, glottis) were used. These elements were also sensitive to other regions distant from the vocal tract such as the head. A free induction decay (FID) based spiral pulse sequence (spatial resolution = 2.4x2.4 mm2, TR = 6.2 ms; TE = 1.5 ms; slice thickness=6 mm; flip angle =150) with golden angle ordering was implemented. VDS and UDS trajectories were designed with gradient specifications of 33 mT/m amplitude and 120 mT/m/ms slew rate. To limit sensitivity to off-resonance, multi-shot short readout lengths were used (Tread=1.9ms; number of interleaves = 21). For UDS, FOV was uniform at 20x20 cm2, while for VDS, FOV was linearly varied from 40x40 cm2 to 8x8 cm2 along the k-space radius (figure 1). We employ a sparse SENSE temporal finite difference constrained reconstruction; the coil maps were estimated by an eigen decomposition method, and the regularization parameter was selected heuristically [4]. Data was acquired from two volunteers (50, 25 year old adult speakers). The speech stimuli consisted of a.) repeating the phrase: “loo-lee-laa-za-na-za”, and b.) counting numbers “one-two-three-four-five” as fast as the speaker could. The rapid number counting task was designed to test the temporal fidelity in capturing vey fast articulatory shaping patterns. Reconstruction was performed at retrospectively chosen time resolutions of 1 TR, 2 TR, and 3 TR per frame. Image quality was qualitatively assessed in terms of preserving the spatio-temporal dynamics.Results
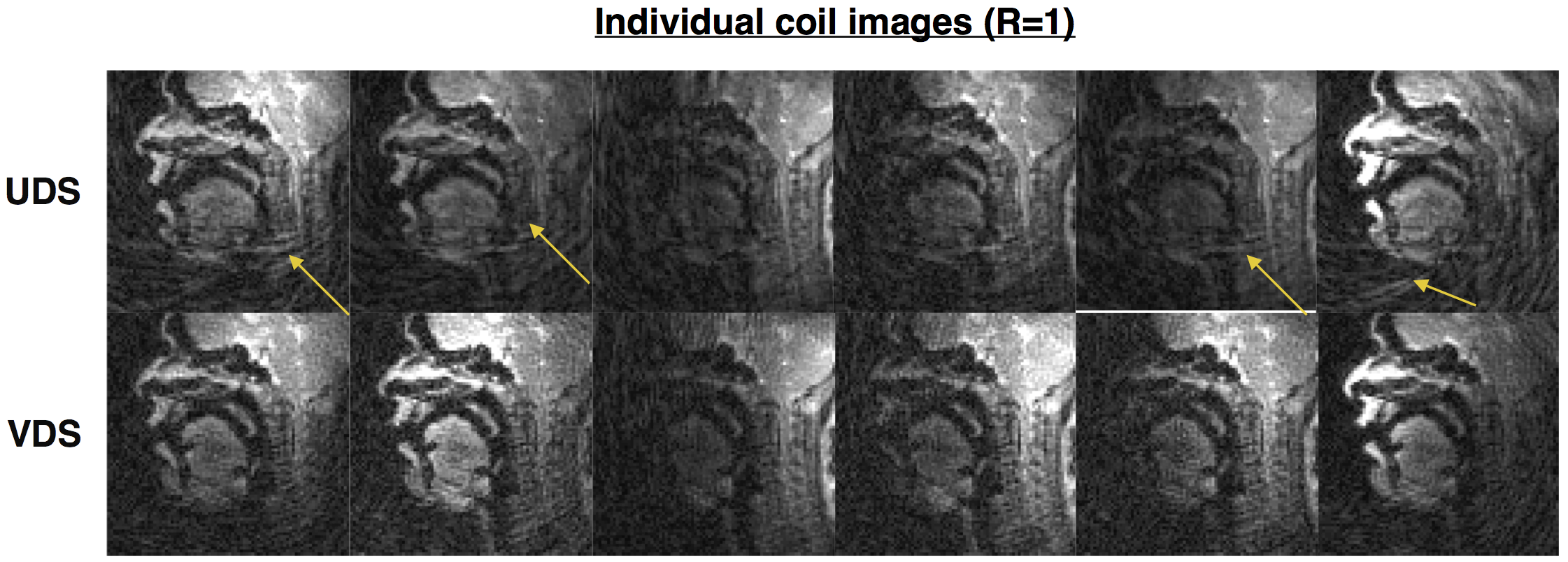
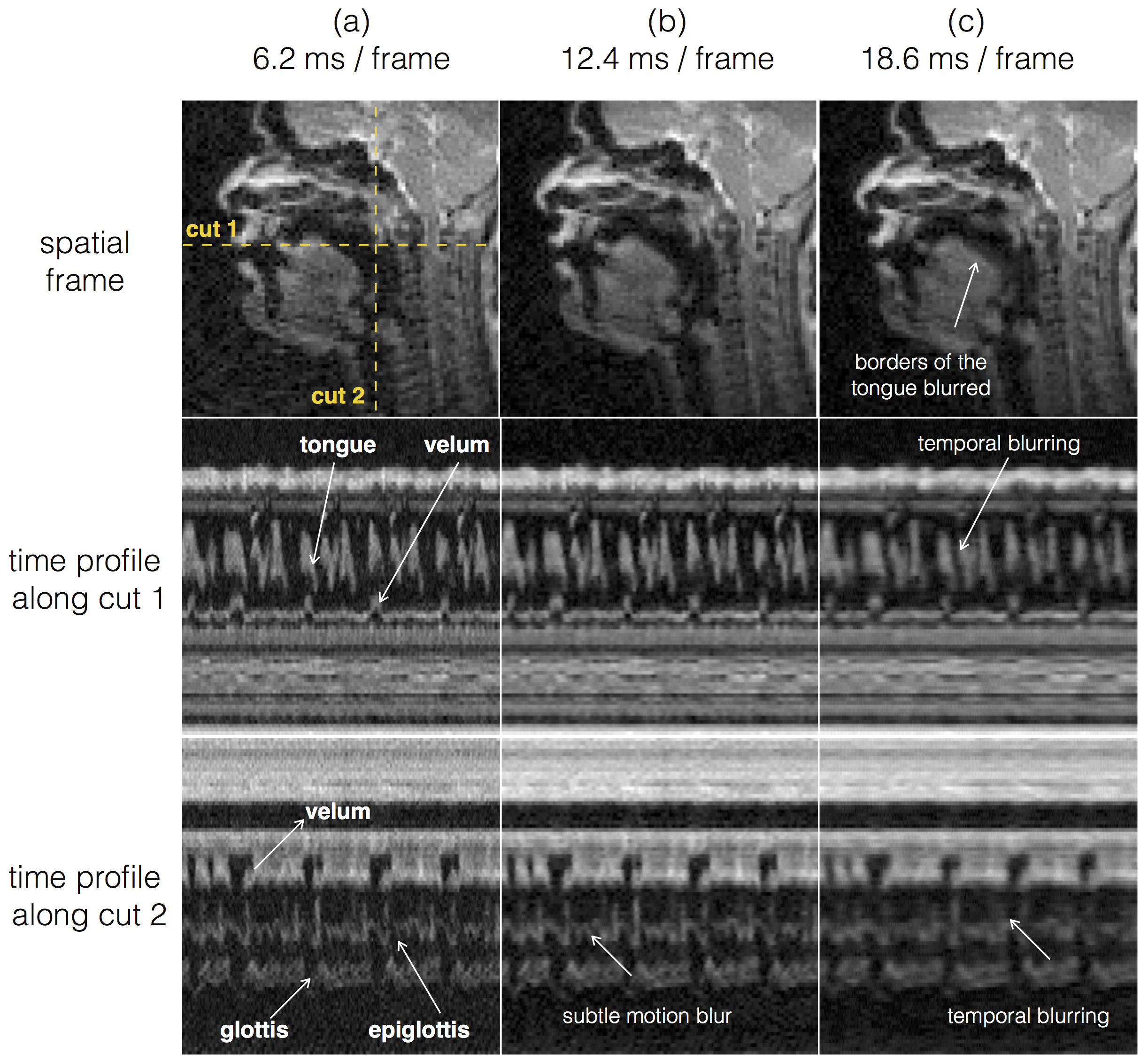
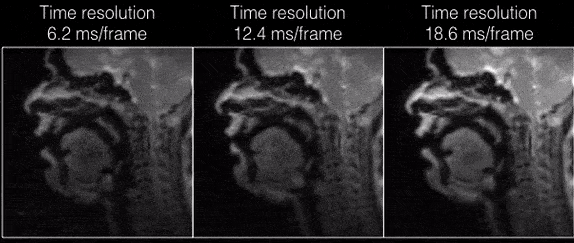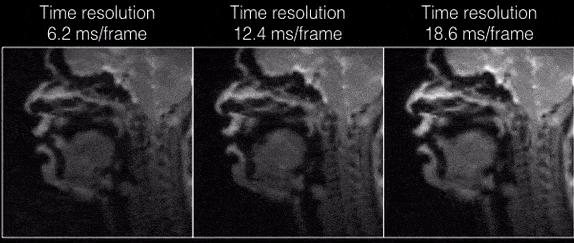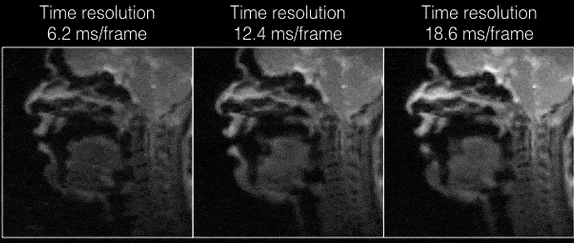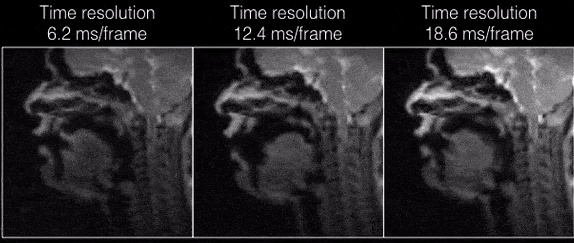
Figure 2 shows the individual coil images with the UDS and VDS schemes from 21 interleaves (R=1) reconstructed via gridding. Due to higher sampling density in the central k-space regions, the VDS scheme efficiently mitigates artifacts from coil elements sensitive to the regions distant from the vocal tract. Figure 3 shows DMRI images from the speech task of rapidly counting numbers. The reconstructions were performed at various time resolutions of (1 TR/frame, 2 TR/frame, and 3 TR/frame). In this rapid vocal tract shaping speech task, the 3 TR/frame reconstruction showed considerable temporal blur, the 2TR/frame depicted mild temporal blur in some frames. The improved time resolution in the 1 TR/frame reconstructions depicted excellent temporal fidelity at the various articulator levels. As expected, the level of noise was increased by reducing the number of interleaves per frame. Figure 4 (animation) shows the corresponding dynamic video time series. Figure 5 (animation) demonstrates a speaker uttering the phrase loo-lee-la-za-na-za. This task involves production of consonants and vowels at the subjects natural pace, and the reconstruction at a time resolution of 2TR/frame showed good spatio-temporal fidelity. Note that in this subject, there was a subtle signal loss/blurring along the tongue boundary due to off-resonance differences between air and tissue interfaces.Conclusions
We have shown that in comparison to UDS, VDS sampling design can efficiently suppress artifacts from coil elements that are distant to the vocal tract. At 3 T, we have demonstrated rapid DMRI of vocal tract shaping of up to 6.2 ms/frame by exploiting jointly efficient artifact distribution of VDS along with a sparse temporal constrained reconstruction scheme. With the improved imaging speed, the proposed protocol can be applied to a wide variety of speech tasks. Future work include integration with off-resonance artifact reduction strategies, joint use of outer volume suppression pulses, and extensions of VDS to 3D DMRI.Acknowledgements
No acknowledgement found.References
[1] Lingala SG, Zhu Y, Kim Y, Toutios A, Narayanan S, Nayak KS. A fast and flexible MRI system for the study of dynamic vocal tract shaping. Magn. Reson. Med. [Internet] 2016;00:n/a–n/a. doi: 10.1002/mrm.26090.
[2] Narayanan, S., Nayak, K., Lee, S., Sethy, A., & Byrd, D., An approach to real-time magnetic resonance imaging for speech production. Journal of the acoustical society of America, 115(4), 1771-1776, 2004.
[3] Niebergall A, Zhang S, Kunay E, Keydana G, Job M, Uecker M, Frahm J. Real-time MRI of speaking at a resolution of 33 ms: Undersampled radial FLASH with nonlinear inverse reconstruction. Magn. Reson. Med. 2013;69:477–485.
[4] Lingala SG, Sutton BP, Miquel ME, Nayak KS. Recommendations for real-time speech MRI. J. Magn. Reson. Imaging 2016;43:28–44. doi: 10.1002/jmri.24997.
[5] Iltis PW, Schoonderwaldt E, Zhang S, Frahm J, Altenmüller E. Real-time MRI comparisons of brass players: a methodological pilot study. Hum Move Sci. 2015;42:132–145
[6] Freitas AC, Wylezinska M, Birch MJ, Petersen S, Miquel ME. Comparison of Cartesian and non‐Cartesian real‐time MRI sequences at 1.5T to assess velar motion and velopharyngeal closure during speech. PLoS One 2016;11:e0153322.
Figures