4741
Complete Segmentation of Human Thigh and Calf Muscles/Tissues with Convolutional Neural Network and Partially Segmented Training Images1Clinical Imaging Research Center, National University of Singapore, Singapore, Singapore, 2AGENCY FOR SCIENCE, TECHNOLOGY AND RESEARCH (A*STAR), Singapore, Singapore
Synopsis
Quantitative analysis of lower extremity images typically require manual or semi-automated segmentation of regions of interest. This can be extremely time consuming. Here, we utilise DeepLearning and a database of previously segmented thigh and calf t1-weighted images to automatically segment the images into different tissue types and various muscle groups. Dice scores greater than 0.85 were achieved on average across the classes with as few as 40 training images (3D). In addition, we demonstrate a method for training the model with partially labelled images, enabling access to potentially much larger training datasets.
Introduction
Segmentation of human thigh and calf tissues/muscles is often an important pre-processing steps in musculoskeletal studies. While DeepLearning has recently became the default choice in automating medical image segmentation, there has been a lack of works1 allowing full thigh/calf tissues/muscles segmentation. Here, we demonstrate automated segmentation of the thigh/calf into 11/6 muscle and 4 tissue classes using two popular DeepLearning architectures and combinations of (modified) loss functions, achieving dice score greater than 0.85 on average across the classes. To our best knowledge, this is currently the most comprehensive automated segmentation of the human thigh and calf.Method
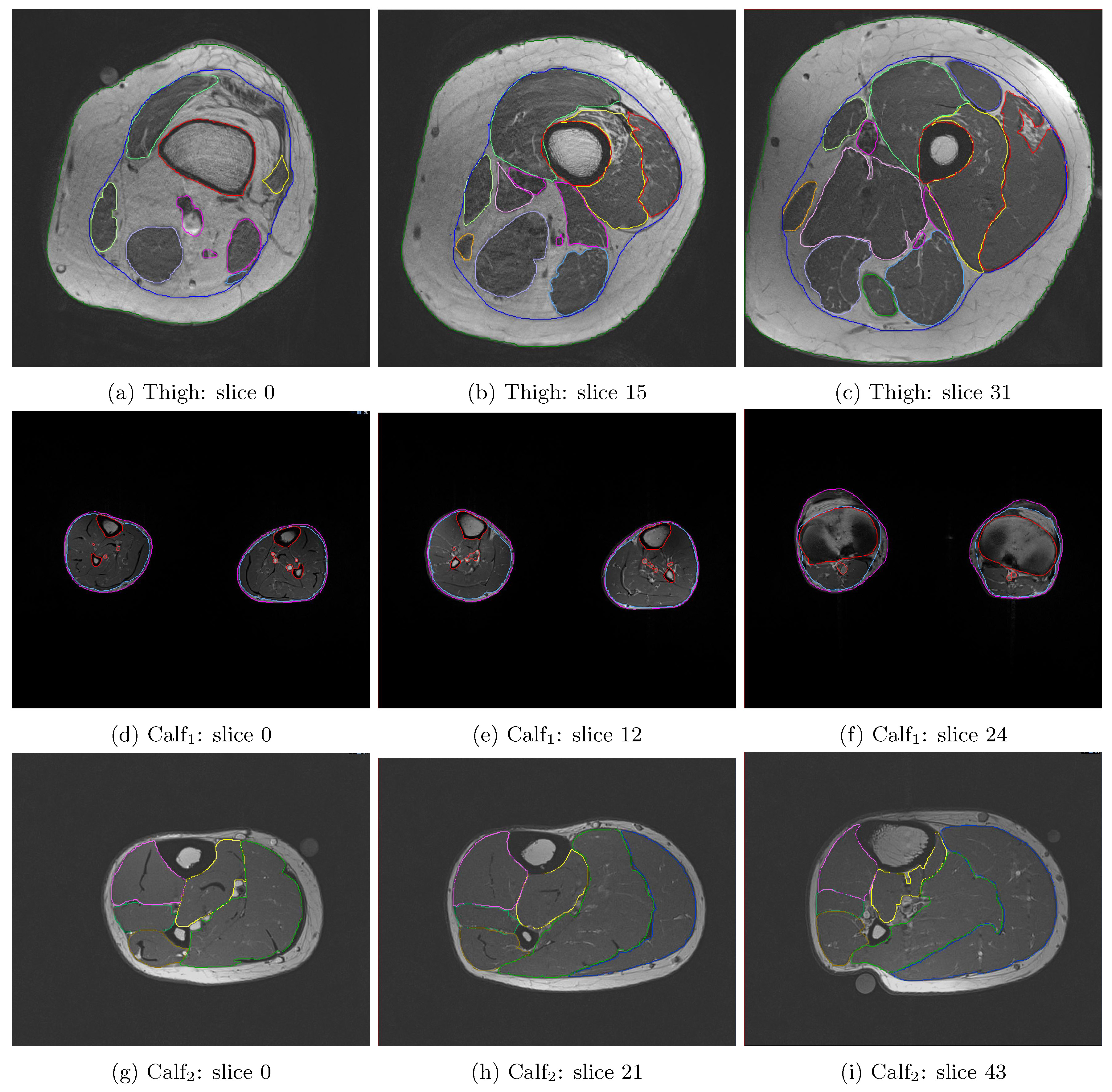
T1-weighted Turbo Spin Echo (TSE) images and the corresponding manually-segmented label masks are leveraged from previous studies to train the neural networks (see Fig.1). All images are acquired using either Siemens 3T Prisma or TrioTim. Images with both limbs in the FOV are cropped into two separate images.
Deep-learning algorithms are developed with Tensorflow(v1.4) in Python. Two popular network architecutures for semantic segmentation (UNet4 and FCN2) are implemented and compared. Since UNet and FCN both works with 2D images, the TSE and mask images are fed into the neural network as batches of 10 axial slices. VNet3, the 3D extension of UNet, is currently being tested.
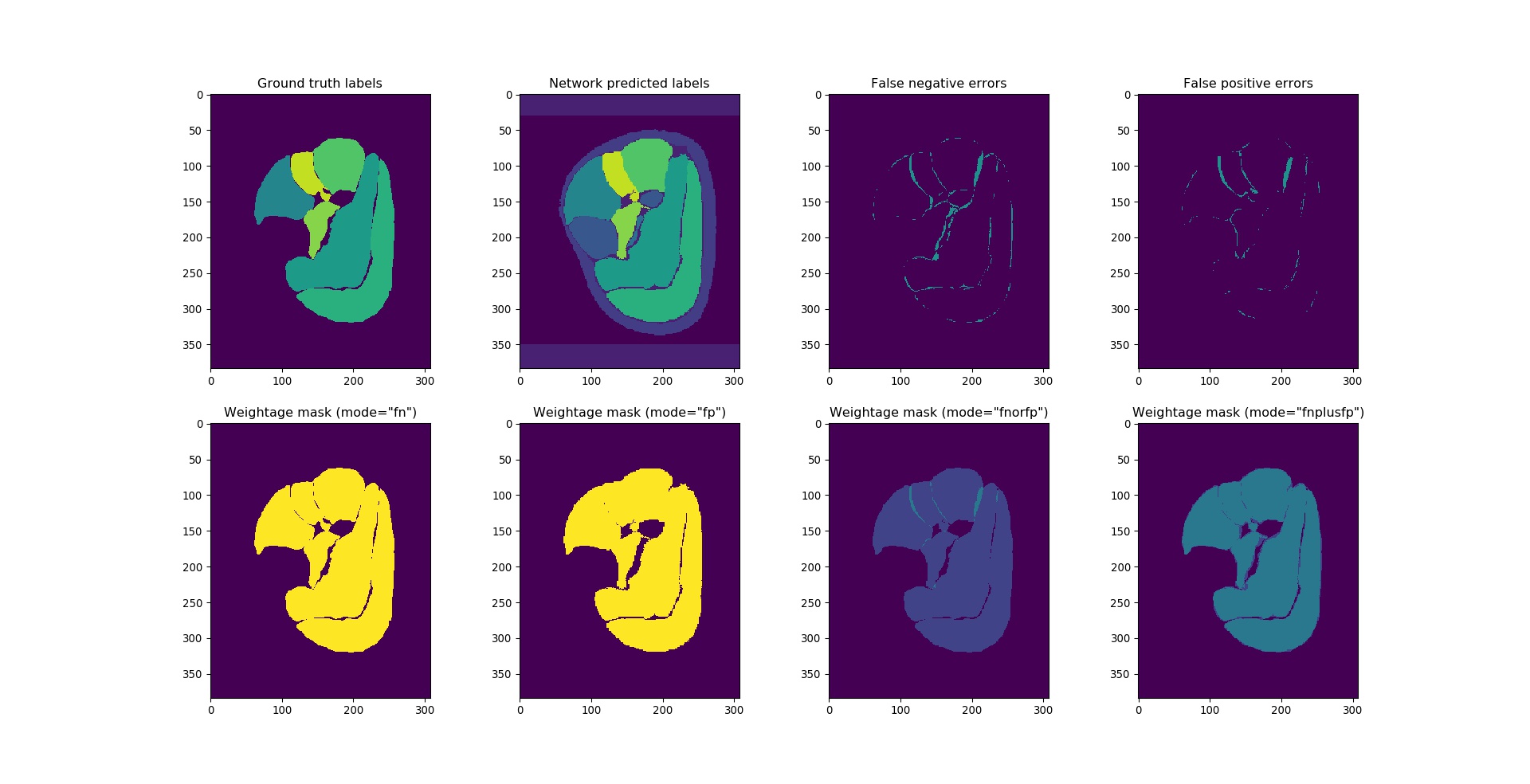
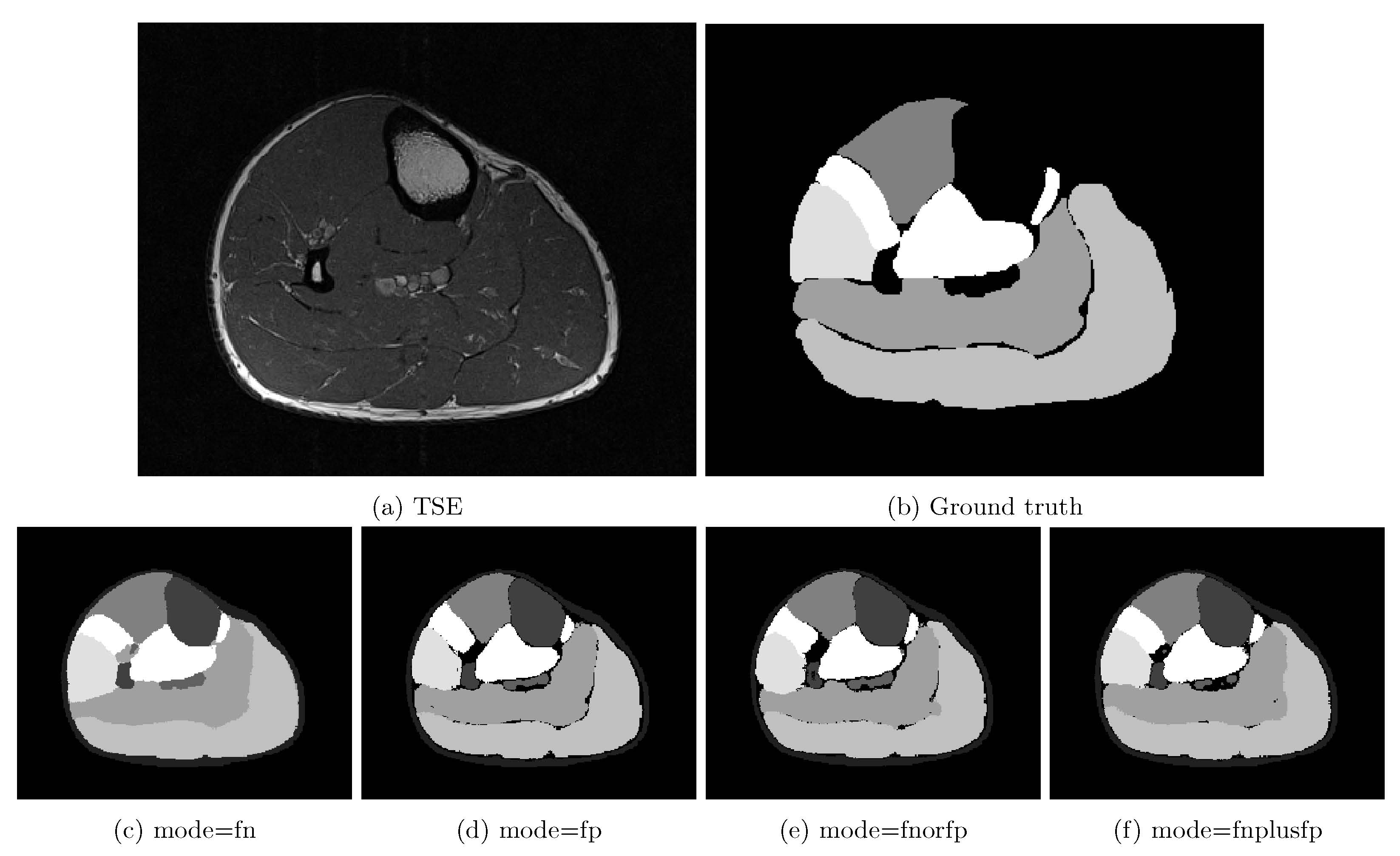
Choice of loss function can be crucial to any deep-learning algorithm's performance. Since image segmentation is essentially a voxelwise classification problem, it's intuitive to use (weighted) categorical crossentropy loss $$$loss_{xent}$$$ as the optimization target while training the networks:$$\label{eq:xent}loss_{xent}=\sum_{i,j(,k)=0}^{\substack{i,j(,k)\in\\image}}w_{c}\cdot\sum_{c=0}^{n_{class}}-y_{i,j(,k)}^{c}\cdot\log(p_{i,j(,k)}^{c})$$with ground truth label $$$y_{i,j(,k)}^{c}$$$:$$y_{i,j(,k)}^{c}=\begin{cases}1&\text{if}\;voxel_{i,j(,k)}\in\;class_{c}\\0&\text{if}\;voxel_{i,j(,k)}\notin\;class_{c}\end{cases}$$Usually, $$$w_{c}$$$ in $$$loss_{xent}$$$ is enforced by applying a weightage mask $$$w_{i,j(,k)}$$$ to the class-summed crossentropy $$$\sum_{c=0}^{n_{class}}-y_{i,j(,k)}^{c}\cdot\log(p_{i,j(,k)}^{c})$$$:$$w_{c}\longrightarrow\;w_{i,j(,k)}=\sum_{c=0}^{n_{class}}w_{c}\cdot\;y_{i,j(,k)}^{c}\\loss_{xent}\;=\;\sum_{i,j(,k)=0}^{i,j(,k)\in\\image}w_{i,j(,k)}\cdot\sum_{c=0}^{n_{class}}-y_{i,j(,k)}^{c}\cdot\log(p_{i,j(,k)}^{c})$$This is amended to improve the network's performance on partially labelled calf images (Fig.2):$$w_{i,j(,k)}=\begin{cases}\sum_{c=0}^{n_{class}} w_{c}\cdot\;y_{i,j(,k)}^{c}&\text{if}\;mode=fn\\\sum_{c=0}^{n_{class}}w_{c}\cdot\;pred_{i,j(,k)}^{c}&\text{if}\;mode=fp\\\sum_{c=0}^{n_{class}}w_{c}\cdot(y_{i,j(,k)}^{c}\lor\;pred_{i,j(,k)}^{c})&\text{if}\;mode=fn\_or\_fp\\\sum_{c=0}^{n_{class}}w_{c}\cdot(y_{i,j(,k)}^{c}+pred_{i,j(,k)}^{c})&\text{if}\;mode=fn\_plus\_fp\\0&\text{else}\end{cases}$$with $$$mode$$$ being another hyperparameter to be chosen.
Meanwhile, it's also common to see dice-derived loss functions being used as minimization target, such as taking the (weighted) average inverse-log-sum of per-class dice scores:$$dice_{c}=\sum_{i,j(,k)=0}^{\substack{i,j(,k)\in\\image}}\frac{2\cdot(y_{i,j(,k)}^{c}\land\;pred_{i,j(,k)}^{c})}{y_{i,j(,k)}^{c}+pred_{i,j(,k)}^{c}}\\%\text{dice}\;\text{loss}=\frac{1}{c}\sum_{c}^{n_{class}}\sum_{i,j(,k)=0}^{i,j(,k)\in\;image}\log(0.5\cdot(y_{i,j(,k)}^{c}+pred_{i,j(,k)}^{c}))-\log(y_{i,j(,k)}^{c}\;and\;pred_{i,j(,k)}^{c})loss_{dice}=\frac{1}{c}\sum_{c}^{n_{class}}-w_{c}\cdot\log(dice_{c})%\Bigg[\sum_{i,j(,k)=0}^{i,j(,k)\in\;image}\frac{0.5\cdot(y_{i,j(,k)}^{c}+pred_{i,j(,k)}^{c})}{y_{i,j(,k)}^{c}\;and\;pred_{i,j(,k)}^{c}}\Bigg]$$with network-predicted label $$$pred_{i,j(,k)}^{c}$$$ obtained by determining which class has the highest probability from the network output $$$p_{i,j(,k)}^{c}$$$:$$pred_{i,j(,k)}^{c}=\begin{cases}1&\text{if}\;\arg\!\max\limits_{c\prime}p_{i,j(,k)}^{c\prime}=c\\0&else\end{cases}$$
For training the networks, original images are downsampled to slices of 256x256 voxels to reduce system memory requirements. They're then split into training (80%) and evaluation (20%) set. Neural networks for thigh segmentation are trained with two subsets of the training images: one with the full 32 axial slices, while another with the 16 slices from proximal half of the full image. Meanwhile, those for calf segmentation are trained with full set of slices. All network configurations are trained on a GPU-cluster equipped with Intel E5-2690v3 and NVIDIA Tesla K40 for 15,000 steps, after which a plateau in the training loss is observed. Predicted labels from the network $$$pred_{i,j(,k)}^{c}$$$ are first concatenated into the original 3D stack if required (i.e. UNet and FCN), followed by upsampling with nearest-neighbour interpolation to match original input image's size of 512x512 voxels.
Result
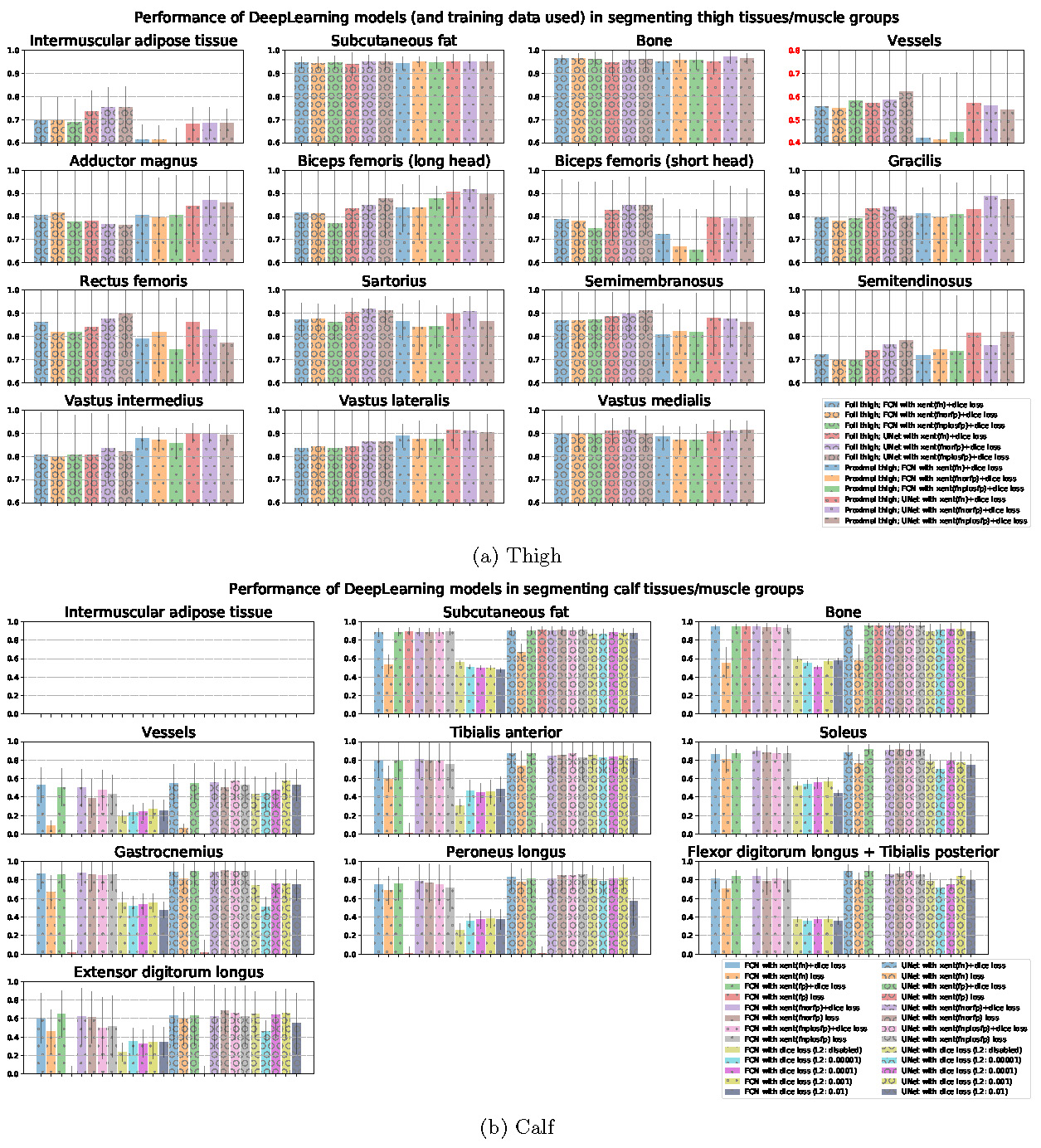
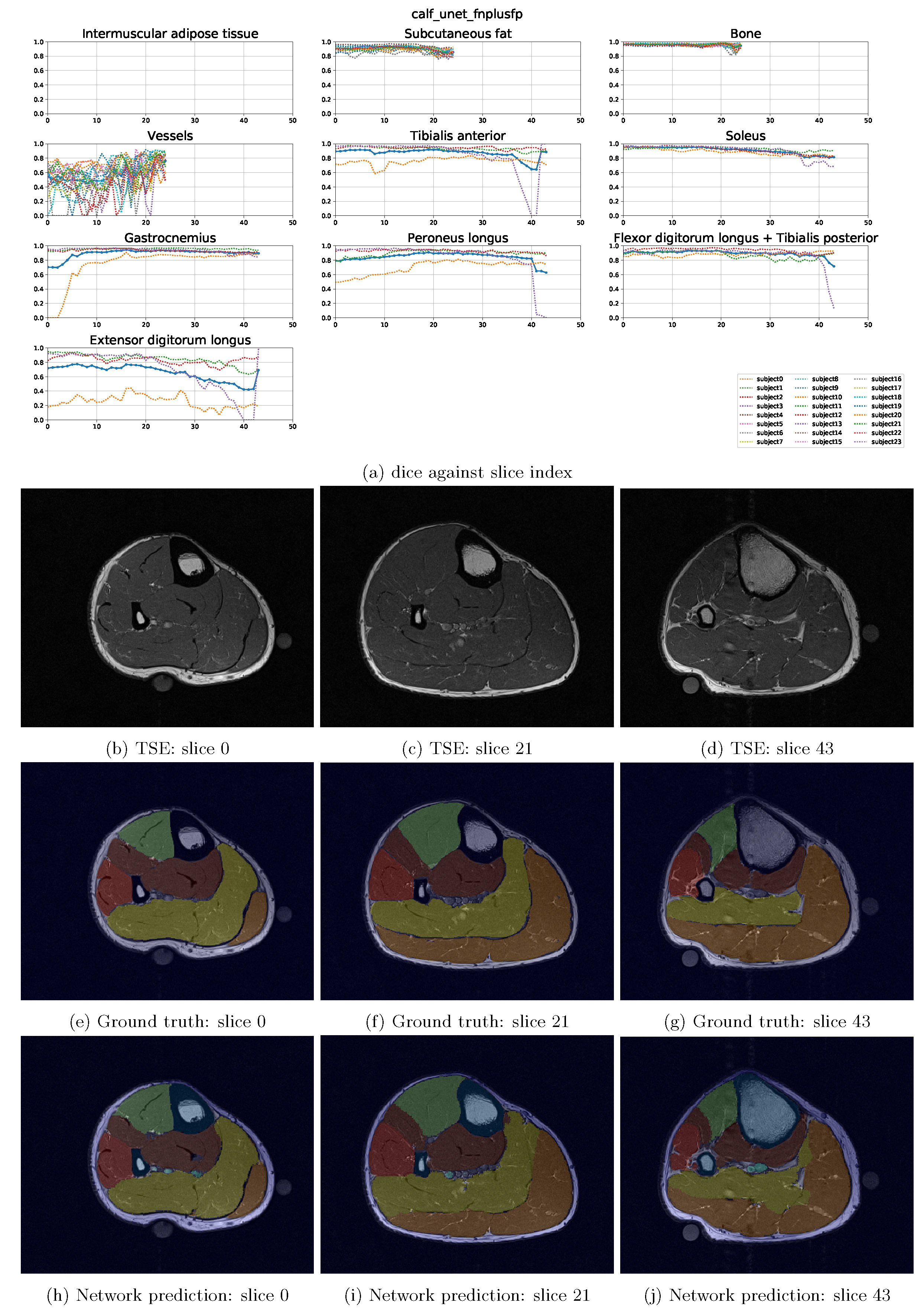
Predictions $$$pred_{i,j,(,k)}$$$ from each DeepLearning model configurations are post-processed and compared to the manually labelled ground-truth masks. Dice score iscomputed for each classes, subjects, and slices individually and stored as a matrix of size $$$n_{models} \times n_{subjects} \times n_{slices} \times n_{class}$$$. Performances (dice) of each model against each class are then bar-charted and tabulated (Fig.3). Dice performance across the slices is also shown in Fig.4 using the model configuration "UNet with xent(fnplusfp)+dice loss" as an example.Discussion
Fig.3 shows that UNet is performing slightly better than FCN in general. In comparison between the loss functions,$$$loss_{xent}+loss_{dice}$$$perform decently in segmenting the thigh. However, when dealing with partially segmented calf training images, necessity of using the amended weightage mask $$$w_{i,j(,k)}$$$ can be seen (Fig.5). Common application of weightage mask in $$$loss_{xent}$$$ is equivalent to the $$$fn$$$ mode, which optimizes only the true positive and false negative errors. This works well in cases where each voxels in the image is classified into a known class, since voxels contributing to false positive error in one class is also causing false negative error in another class (see Fig.2). In cases of partially labelled image (such as the calves in this study) and existence of unknown class, false positive errors will be ignored under the same scheme. The modified weightage masks resolves this problem by taking both errors into account. While dice loss automatically optimizes both errors, crossentropy loss has a simpler gradient and hence may lead to higher stability during training. Resulting slice-wise loss results (Fig.4) indicate poorer classification at near-edge slices of the image. This is likely due to slices with muscles with small in-slice volume and a paucity of training data.
Conclusion
Here, we have demonstrated automated segmentation of human thigh and calf tissues/muscles using DeepLearning models. Methods to handle partially labelled segmentation data was described, which is potentially useful for alternative applications.Acknowledgements
No acknowledgement found.References
- Ezak Ahmad, Manu Goyal, Jamie S. McPhee, Hans Degens, and Moi Hoon Yap. Semantic segmentation of human thigh quadriceps muscle in magnetic resonance images. CoRR , abs/1801.00415, 2018.
- Jonathan Long, Evan Shelhamer, and Trevor Darrell. Fully convolutional networks for semantic segmentation. In The IEEE Conference on Computer Vision and Pattern Recognition (CVPR) , June 2015.
- Fausto Milletari, Nassir Navab, and Seyed-Ahmad Ahmadi. V-net: Fully convolutional neural networks for volumetric medical image segmentation. CoRR , abs/1606.04797, 2016.
- Olaf Ronneberger, Philipp Fischer, and Thomas Brox. U-net: Convolutional networks for biomedical image segmentation. CoRR , abs/1505.04597, 2015.
Figures