4738
Towards Domain-invariant Carotid Artery Lumen-wall Segmentation Using Adversarial Networks1Medical Sciences Graduate Program, Cumming School of Medicine, University of Calgary, Calgary, AB, Canada, 2Seaman Family MR Research Centre, Foothills Medical Centre, Calgary, AB, Canada, 3Radiology and Clinical Neuroscience, Hotchkiss Brain Institute, University of Calgary, Calgary, AB, Canada
Synopsis
Magnetic resonance (MR) imaging is frequently used for carotid artery wall imaging. The capacity for multi-contrast imaging allows MR scanners to resolve the lumen and wall, as well as multiple plaque components. Combined this information can provide evidence of increased stroke risk. Quantitative analysis of carotid artery MR images regularly begins with the manual segmentation of wall and plaque. This process is time-consuming and costly, and suggests the need for automated methods. Developing a robust segmentation tool is challenging because of the domain shift due to different image contrasts and/or scanners. Here, we demonstrate that a deep learning network including an adversarial component is capable of learning domain-invariant features, thus producing a generalizable segmentation model.
Purpose
Magnetic resonance (MR) is used for carotid artery imaging because of its capacity for multiple imaging contrasts, allowing it to resolve several plaque components and thus, evaluate stroke risk.1 Quantitative carotid artery assessment typically begins with manual segmentation, a slow process requiring qualified professionals. Automatic segmentation using deep learning has been proposed as a solution to manual segmentation, but much of the software developed thus far has been limited in application; when applied to new data, many models perform poorly due to differences in the imaging domain.2 We propose that an adversarial segmentation model is capable of learning image contrast- and domain-invariant features, and we demonstrate improved performance when applied to an unseen dataset, acquired using a different imaging protocol.Data
Training data was collected from 26 atherosclerosis patients imaged locally as part of the AIM-HIGH MR substudy,3 and included PD-, T1-, and T2-weighted images (15 slices/image), all without contrast agent. One AIM-HIGH subject was excluded from training to serve as a test subject. Two additional test images, acquired with a DANTE-Cube sequence,4 were obtained from an ongoing local study (CARDIS). Contours for the AIM-HIGH data were provided by the Vascular Imaging Laboratory (Seattle, WA)3 and include the lumen and outer wall of either the left or right carotid artery (common carotid, bifurcation point, internal carotid artery).Model
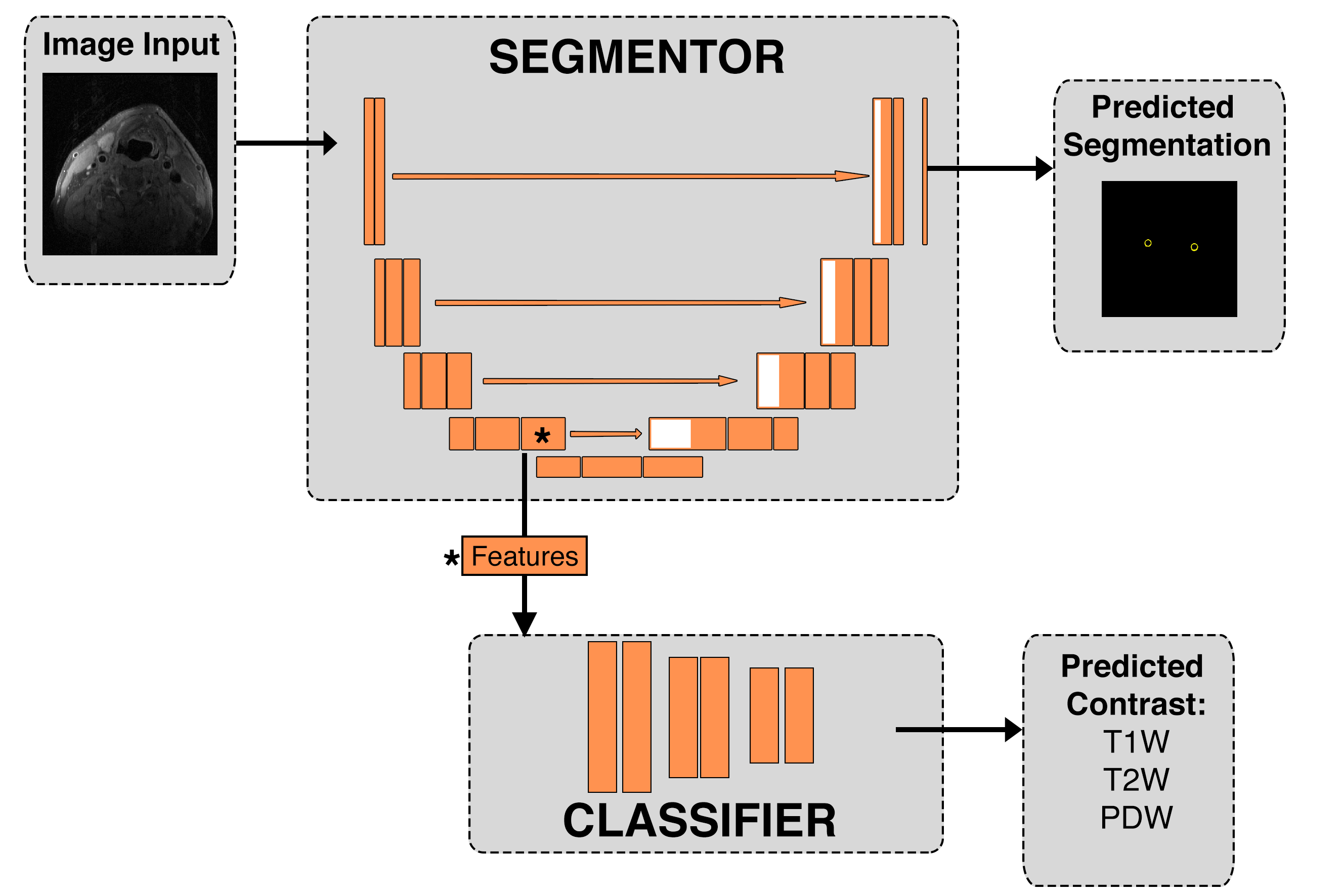
Inspired by generative adversarial networks (GANs),5 our model (Figure 1) consists of two adversarial components: segmentation and classification. Images are fed into the segmentor (U-Net),6 which outputs a carotid wall segmentation. Features generated at the end of the U-Net encoding path, prior to max-pooling, are sent to the classifier (ConvNet) that predicts the contrast of the originally input image based on the extracted features. The model improves when the segmentation component generates features that ‘fool’ the classifier, i.e., it begins to learn features which are not specific to an image contrast. We also trained a simple U-Net, to serve as a control model to illuminate the effect of the adversarial component.
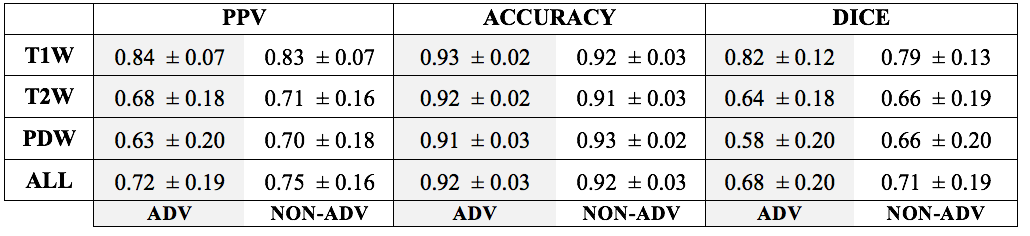
Both models were trained for 100 epochs, using an 80:20 training:validation data split. Each image slice (512 × 512) was divided into five 128 × 128 patches for training and underwent data augmentation. All three image contrasts were trained concurrently, and corresponding slices of different image contrasts were treated as independent images. Categorical cross entropy and the negative of the Dice score were used to calculate the classification loss, $$$\mathcal{L}_{class}$$$, and segmentation loss, $$$\mathcal{L}_{seg}$$$, respectively. The combined loss function for the adversarial model was $$$\mathcal{L}_{adv} = \mathcal{L}_{seg} - \lambda\mathcal{L}_{adv}$$$, where $$$\lambda$$$ is a scaling parameter. For this work, we used $$$\lambda$$$ = 0.2. The negative of the Dice score was used as the loss function for the non-adversarial model. Entire slices were used for evaluation, instead of patches. As one carotid artery was manually segmented for each image, scores were calculated over the left or right half of the image containing the reference segmentation. Dice, positive predictive value and accuracy scores were calculated for each slice, and the mean score for each image contrast was determined.
Results
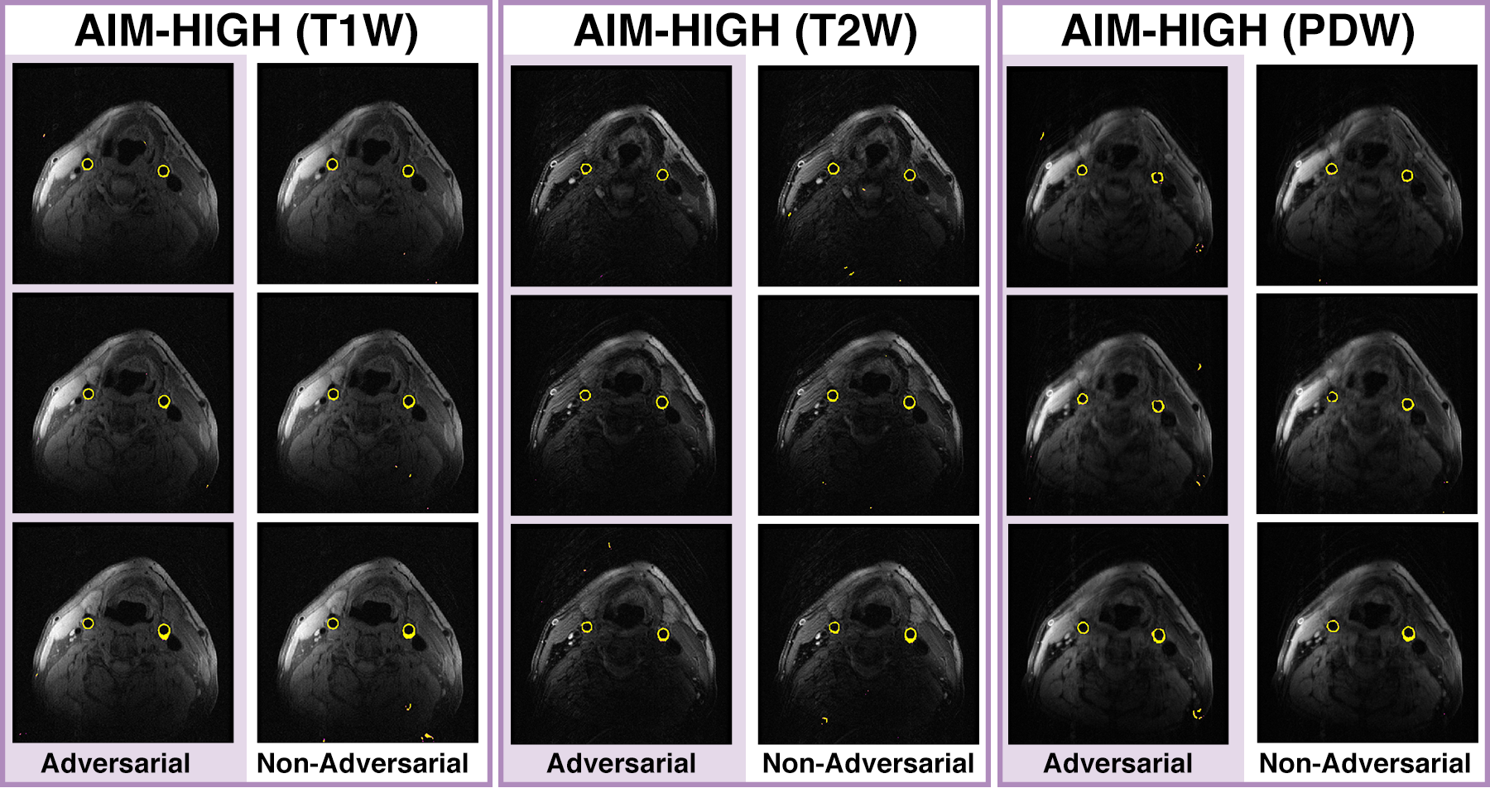
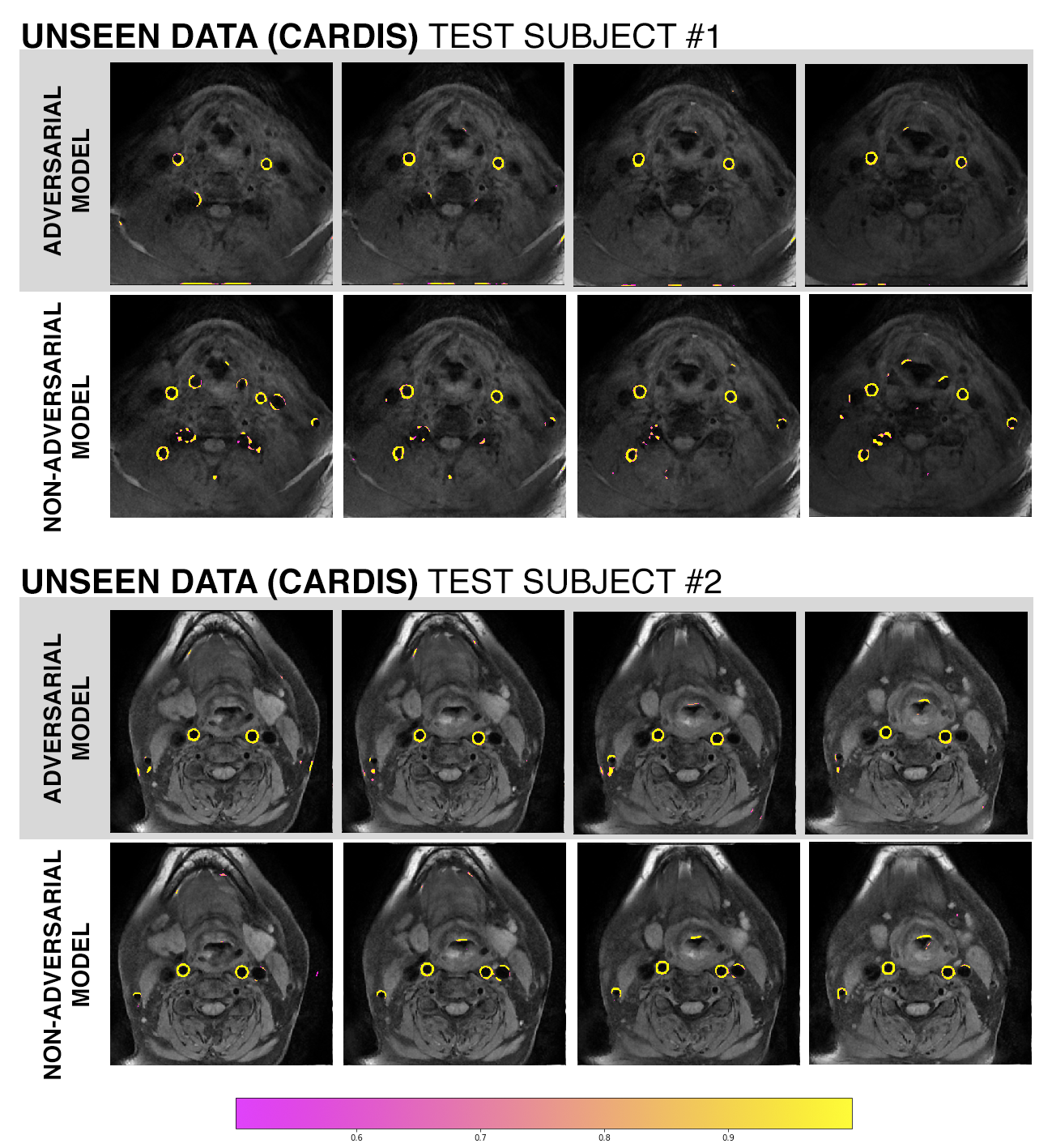
Both models performed similarly on the AIM-HIGH test subjects (Figure 2, Table 1). Without ground-truth segmentations, performance on CARDIS images could only be qualitatively assessed. The adversarial network appeared to produce fewer erroneous segmentations (false positives) relative to the non-adversarial model on the CARDIS images (Figure 3).Discussion
Although both models performed similarly on the AIM-HIGH images, the adversarial network achieved superior results on the CARDIS test images. This finding suggests that both models were learning different sets of features due to the absence/addition of the adversarial component. When assessing the performance scores, it is important to consider that 100 epochs is a low number of repetitions for training an adversarial model, which are inherently more difficult to train.6Conclusion
Despite advances in medical imaging analysis brought by machine learning, widespread application has been limited due to the inability of models to generalize to different machines and imaging protocols. For models to be used outside of research contexts, attention must be given to developing models that are robust to domain shift. There are limitations to domain adaptation, some features are only resolved with specific MR contrasts. Domain adaptation may still be beneficial in these contexts if other steps in the protocol can be made more efficient via domain adaptation. We demonstrated that a segmentation model can be encouraged to learn domain-invariant features through adversarial training. We intend develop this model further and investigate whether a segmentation tool developed solely with AIM-HIGH images could circumvent of manual segmentation on CARDIS images.Acknowledgements
This study was funded by the Canadian Institute for Health Research (CIHR) and a Queen Elizabeth II fellowship to AD.References
- Saba, L. et al. Carotid Artery Wall Imaging: Perspective and Guidelines from the ASNR Vessel Wall Imaging Study Group and Expert Consensus Recommendations of the American Society of Neuroradiology. Am J Neuroradiol. 2018; 39: E9-E31
- Kamnitsas, K. et al. Unsupervised Domain Adaptation in Brain Lesion Segmentation with Adversarial Networks. Information Processing in Medical Imaging 2017; 597-609.
- Zhao, X.Q., et al. Clinical Factors associated with High-Risk Carotid Plaque Features as Assessed by Magnetic Resonance Imaging in Patients with Established Vascular Disease (from the AIM-HIGH Study). Am J Cardiol 2014; 114: 1412-9
- Xie, Y. et al. Improved Black-Blood Imaging using DANTE-SPACE for Simultaneous Carotid and Intracranial Vessel Wall Evaluation. Magn Reson Med. 2016; 75: 2286-94
- Goodfellow, IJ. Generative Adversarial Nets. Advances in Neural Information Processing Systems. 2014; 2672-2680
- Ronneberger et al. U-Net: Convolution Networks for Biomedical Image Segmentation. Medical Image Computing and Computer-Assisted Intervention. 2015; 234-241.
- Goodfellow, IJ., NIPS 2016 Tutorial: Generative Adversarial Networks. CoRR 2017 arXiv:1701.00160
Figures