4723
Segment Unannotated MR Image Dataset using Joint Image Translation and Segmentation Adversarial Network1Radiology, University of Wisconsin-Madison, Madison, WI, United States
Synopsis
The purpose of our study was to develop and evaluate a generalized CNN-based method for fully-automated segmentation of different MR image datasets using a single set of annotated training data. A technique called cycle-consistent generative adversarial network (CycleGAN) is applied as the core of the proposed method to perform image-to-image translation between MR image datasets with different tissue contrasts. A joint segmentation network is incorporated into the adversarial network to obtain additional segmentation functionality. The proposed method was evaluated for segmenting bone and cartilage on two clinical knee MR image datasets acquired at our institution using only a single set of annotated data from a publicly available knee MR image dataset. The new technique may further improve the applicability and efficiency of CNN-based segmentation of medical images while eliminating the need for large amounts of annotated training data.
Introduction
Segmentation of magnetic resonance (MR) images is a fundamental step in many medical imaging based applications. Recent implementation of deep convolutional neural networks (CNNs) in image processing has been shown to have significant impacts on medical image segmentation (1). Network training of segmentation CNNs typically requires images and paired annotation data representing pixel-wise tissue labels referred to as masks. However, the supervised training of highly efficient CNNs with deeper structure and more network parameters requires a large amount of training images and paired tissue masks. Thus, there is great need to develop a generalized CNN-based segmentation method which would be applicable for a wide variety of MR image datasets with different tissue contrasts. The purpose of our study was to develop and evaluate a generalized CNN-based method for fully-automated segmentation of different MR image datasets using a single set of annotated training data.Methods
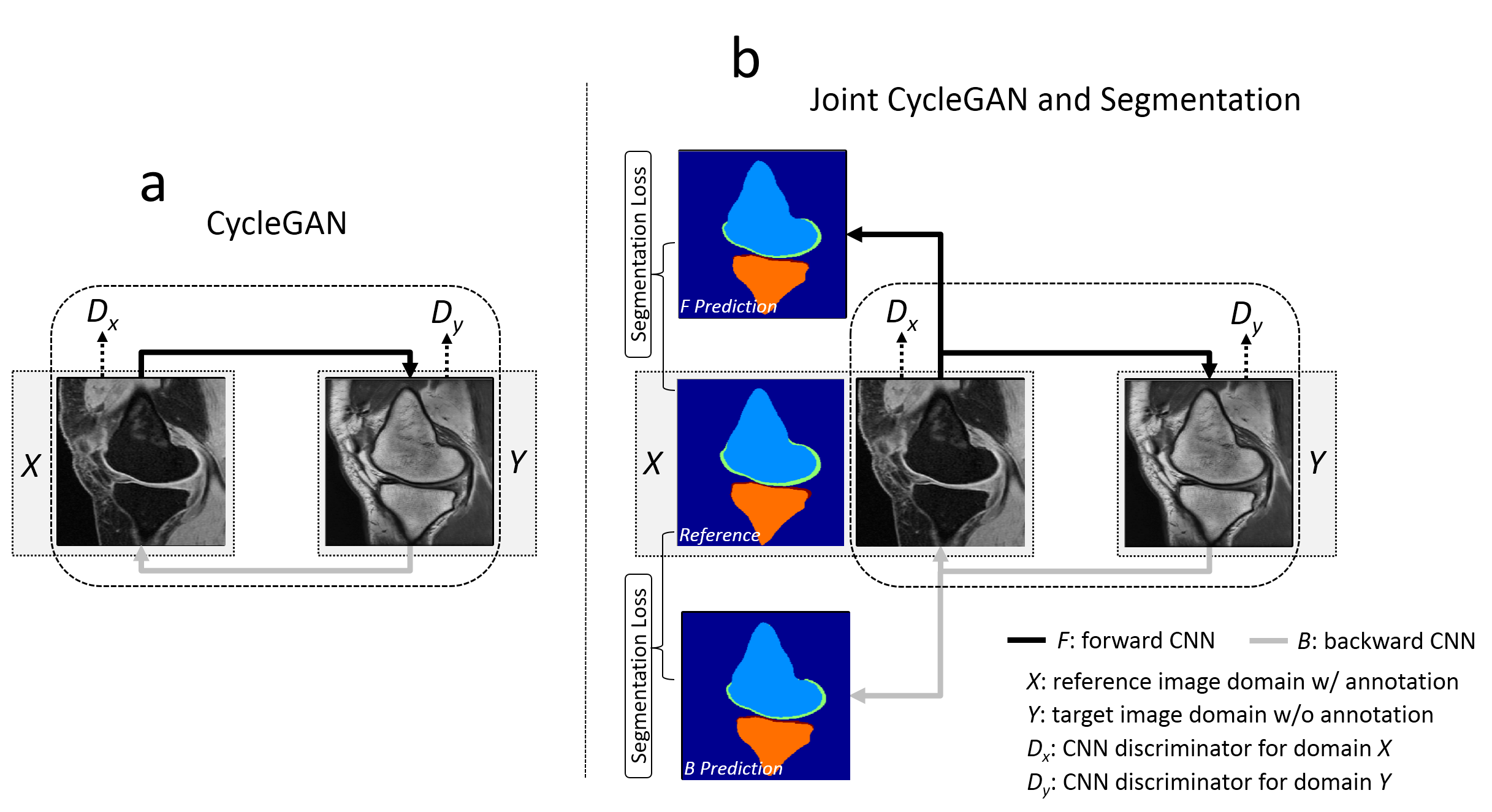
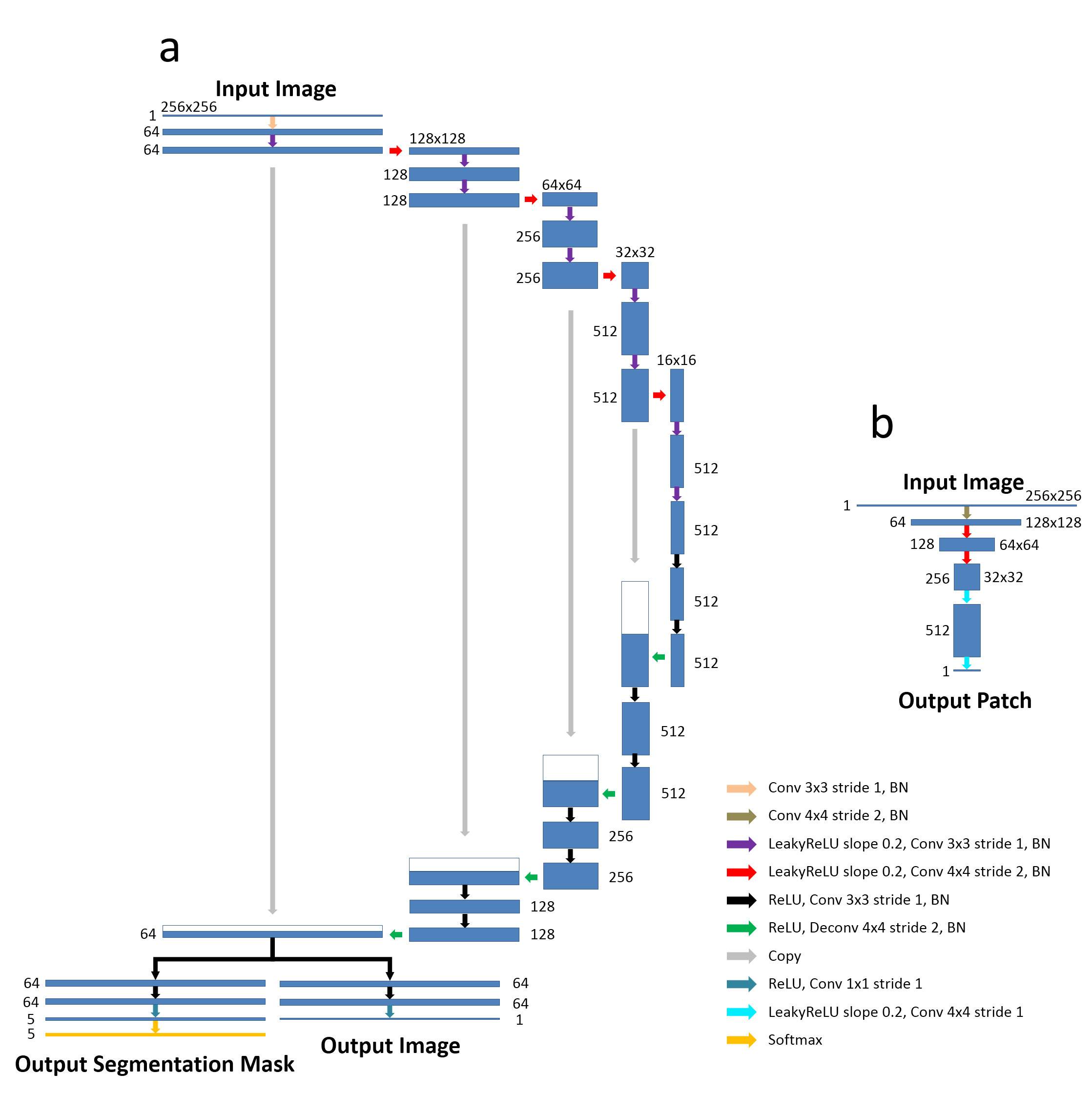
Our work is in line with the method of CycleGAN which was recently proposed for unpaired image-to-image translation for natural images(2). In CycleGAN (Figure 1a), images from two image domains can be translated to exchange image contrasts, features and patterns using Cycle Consistency and Generative Adversarial Newark (GAN). Our hypothesis is that given successful translation from the reference image contrast to the target image contrast, the annotation data used to train the reference images can be applied to train the target images using supervised learning. To make use of image-to-image translation, the proposed method incorporates additional segmentation networks into the CycleGAN structure for jointly training image translation and segmentation (Figure 1b). Our hypothesis is that the image translation can be augmented by adding supervised segmentation information and that jointly training image translation and segmentation can produce improved results. To formulate the problem, the CNN mapping function is modified to create a dual-output network for both of translated images and segmentation masks. A U-Net (3) (Figure 2a) was adapted from a GAN-based image-to-image translation study for performing the CNN mapping functions. The network architecture developed in PatchGAN (4) (Figure 2b) is used for discriminator networks. Three knee MR image datasets were used to evaluate the proposed method. The reference image dataset consisted of the knee MR images from the online SKI10 (www.ski10.org) consisting of 60 sagittal T1-weighted spoiled gradient-echo (T1-SPGR) knee images, all of which had high quality multi-class tissue masks generated by experts and were used for training. Two clinical knee fast spin echo MR image datasets (PD-FSE and T2-FSE) with 60 subjects (40 training, 20 testing) acquired at our institution were used as target images. Manual bone and cartilage segmentation was performed for the clinical image datasets and was used only for ground truth comparison and not included in the network training for the proposed segmentation method. The segmentation results were compared with the results from a supervised U-Net segmentation and two registration methods (direct registration (5) and multi-atlas registration (6)). Quantitative metrics were used to evaluate the accuracy of the segmentation methods on the different clinical knee MR image datasets.Results
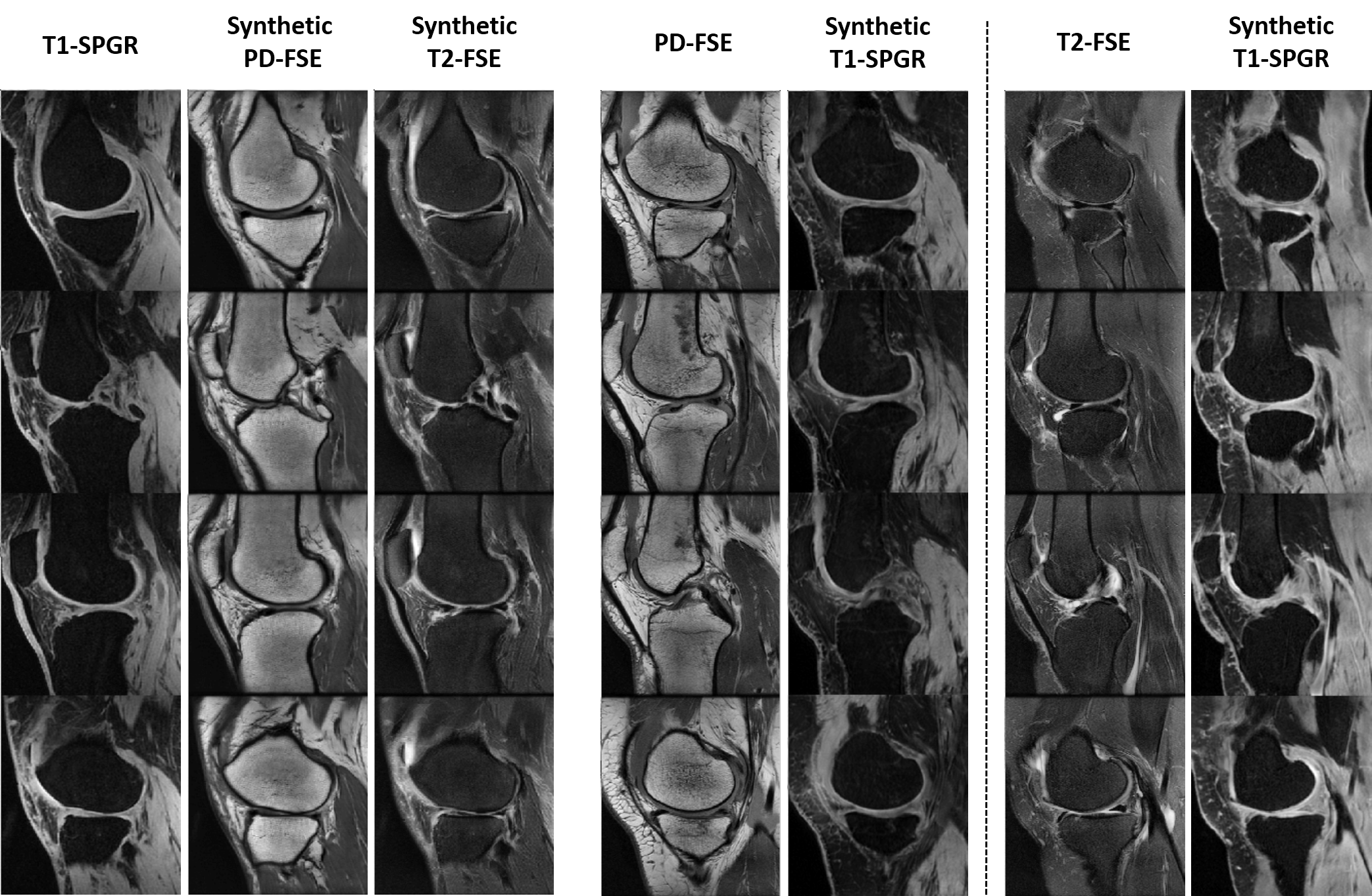
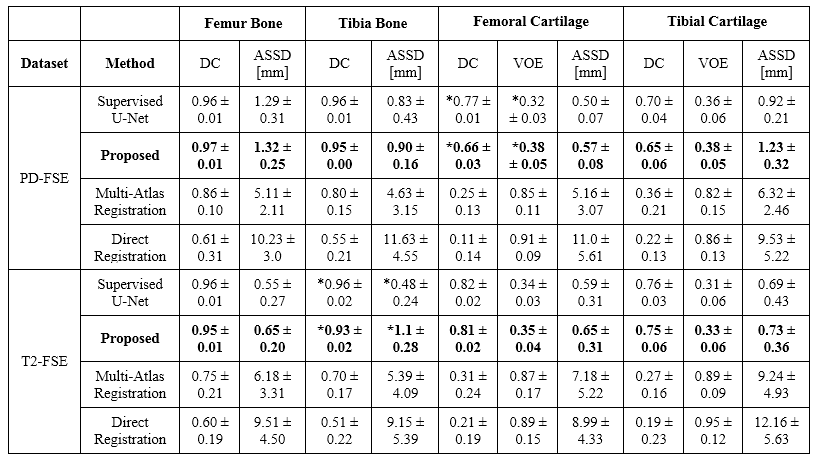
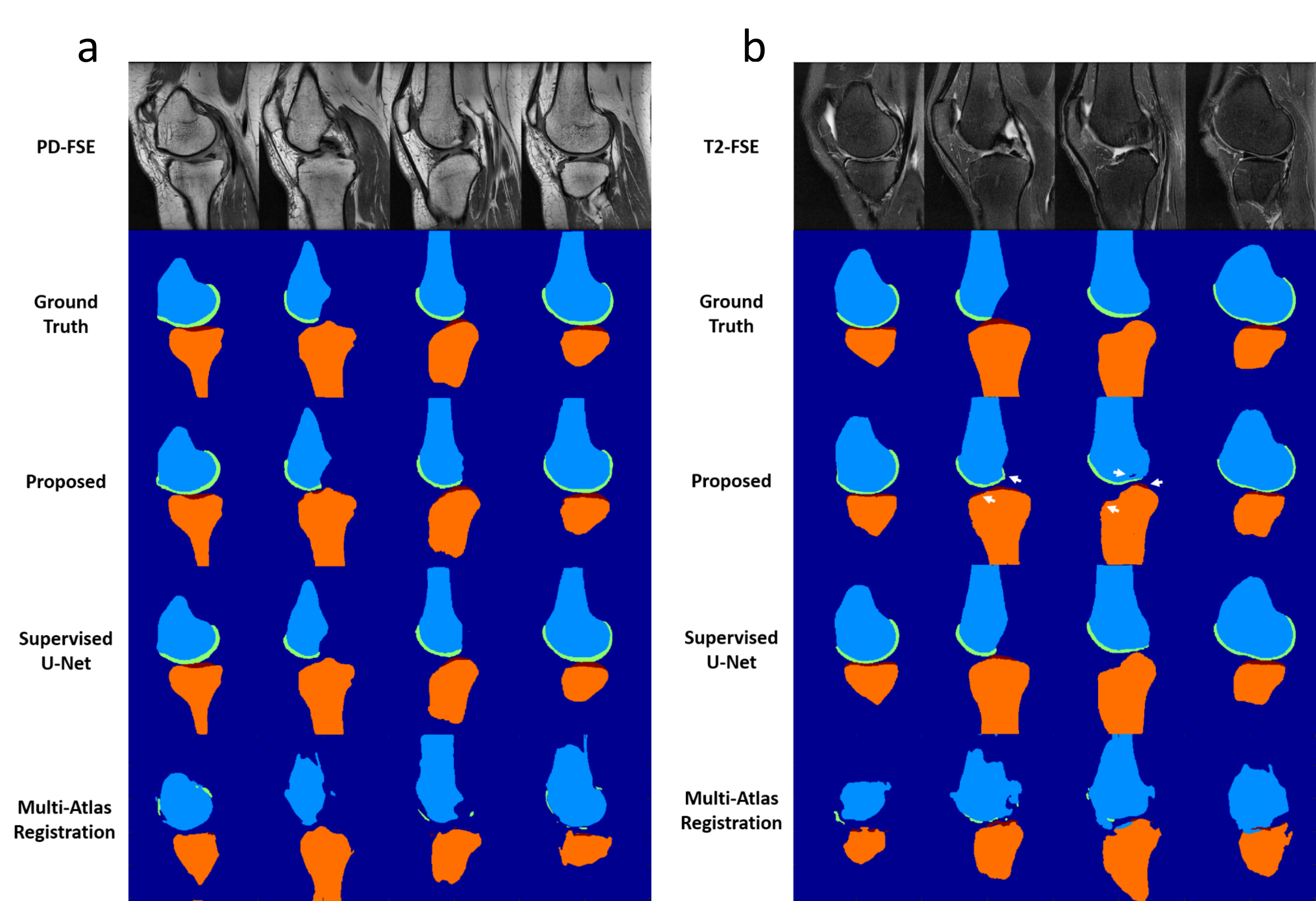
The overall training time was approximate 6.7 hours for each dataset. However, segmentation was rapid with a mean computing time of 0.2 min for all image slices of one subject. Figure 3 show an example of unpaired image-to-image translation for converting SKI10 T1-SPGR image contrast to the PD-FSE and T2-FSE image contrasts (denoted as synthetic PD-FSE and T2-FSE) and vice versa. The averaged values (mean ± standard deviation) of DC, VOE and ASSD are shown in Figure 4 for bone and cartilage segmentation for the 20 hold-out test subjects. The proposed method provided overall comparable segmentation performance to the supervised U-Net method for the PD-FSE and T2-FSE image datasets while requiring no sequence specific annotated training data. The multi-atlas registration method and the direct registration method performed significantly worse (for all bone and cartilage) than deep learning methods. Figure 5a shows examples of bone and cartilage segmentation performed on sagittal PD-FSE images of the knee. Figure 5b shows examples of segmentation performed on sagittal T2-FSE images of the knee.Discussion and Conclusion
Our study described a novel adversarial CNN-based segmentation method that provided rapid and accurate segmentation for multiple MR image datasets using only a single set of annotated training data. This technique eliminates the need to retrain the segmentation CNNs using new annotation data specific to each MR sequence. The approach integrates the basic functions of the CycleGAN technique for image-to-image translation and utilizes an additional semantic segmentation network for joint image translation and segmentation. The new technique may further improve the applicability and efficiency of CNN-based segmentation of medical images while eliminating the need for large amounts of annotated training data.Acknowledgements
No acknowledgement found.References
1. Litjens G, Kooi T, Bejnordi BE, Setio AAA, Ciompi F, Ghafoorian M, van der Laak JAWM, van Ginneken B, Sánchez CI. A survey on deep learning in medical image analysis. Med. Image Anal. 2017;42:60–88. doi: 10.1016/j.media.2017.07.005.
2. Zhu J-Y, Park T, Isola P, Efros AA. Unpaired Image-to-Image Translation Using Cycle-Consistent Adversarial Networks. In: 2017 IEEE International Conference on Computer Vision (ICCV). Vol. 2017–Octob. IEEE; 2017. pp. 2242–2251. doi: 10.1109/ICCV.2017.244.
3. Ronneberger O, Fischer P, Brox T. U-Net: Convolutional Networks for Biomedical Image Segmentation. In: Navab N, Hornegger J, Wells WM, Frangi AF, editors. Medical Image Computing and Computer-Assisted Intervention -- MICCAI 2015: 18th International Conference, Munich, Germany, October 5-9, 2015, Proceedings, Part III. Cham: Springer International Publishing; 2015. pp. 234–241. doi: 10.1007/978-3-319-24574-4_28.
4. Isola P, Zhu J-Y, Zhou T, Efros AA. Image-to-Image Translation with Conditional Adversarial Networks. ArXiv e-prints [Internet] 2016.
5. Bron EE, van Tiel J, Smit H, Poot DHJ, Niessen WJ, Krestin GP, Weinans H, Oei EHG, Kotek G, Klein S. Image registration improves human knee cartilage T1 mapping with delayed gadolinium-enhanced MRI of cartilage (dGEMRIC). Eur. Radiol. [Internet] 2013;23:246–52. doi: 10.1007/s00330-012-2590-3.
6. Shan L, Zach C, Charles C, Niethammer M. Automatic atlas-based three-label cartilage segmentation from MR knee images. Med. Image Anal. [Internet] 2014;18:1233–1246. doi: 10.1016/j.media.2014.05.008.
Figures