4716
g-factor attention model for deep neural network powered parallel imaging: gANN1Seoul National University, Seoul, Korea, Republic of, 2AIRS medical, Seoul, Korea, Republic of, 3Department of Radiology, Seoul St. Mary’s Hospital, Seoul, Korea, Republic of, 4College of Medicine, The Catholic University of Korea, Seoul, Korea, Republic of
Synopsis
In this study, we proposed a new concept of an attention model for deep neural network based parallel imaging. We utilized g-factor maps to inform the neural network about the location containing high possibility of aliasing artifact. Also the proposed network used sensitivity maps and acquired k-space data to ensure the data consistency. Since the g-factor attention deep neural network considered both multi-channel information and spatially variant aliasing condition, our proposed network successfully removed aliasing artifacts up to factor 6 in uniform under-sampling and showed high performance when compared to conventional parallel imaging methods.
Purpose
Recently, the combined approaches of neural networks and physics-based models have shown a remarkable improvement in parallel imaging reconstruction1,2. Still, the challenge remains to demonstrate that these approaches do not generate unexpected artifacts (e.g. hallucinations) in highly aliased areas. In this study, we suggested a conditional parallel imaging reconstruction method using g-factor maps as an attention for the neural network (gANN). This g-factor attention incorporates the spatially different aliasing information and assists the network to improve reconstruction on highly aliased regions (i.e. high g-factor region).Methods
[Residual network] For the fundamental network structure, we utilized a modified U-net that follows wavelet transform architecture complementing the information loss in the conventional pooling process3. A deep residual learning concept was applied4.
[g-factor attention] Based on a recently proposed attention model5, we multiplied features of g-factor maps to the decoder part. Weighting the features in the decoder may help the network pay attention to the most relevant information . The features of the g-factor maps were generated by the convolutional neural network that matches the matrix size in each decoder layer. As shown in Fig. 1, the output of the network was subtracted with the input for the residual processing. [Data-consistency gradient] In order to ensure the acquired data consistency, we utilized the coil sensitivity maps and acquired k-space data. The data consistency gradient term was subtracted from the input which was calculated as the derivative of the l2 norm of the difference within the intermediate output and the acquired k-space data. All the process was iterated for four times before generating the output. [MRI scan] We applied the proposed gANN in FLAIR images of the brain using 32 channel coils at the acceleration factor of 4 and 6. 13 subjects were scanned (training: 10, validation: 1, test: 2). Data were fully-sampled and the scan parameters were as follows: TR = 9000 ms, TI = 2500 ms, TE = 87 ms, turbo factor = 16, FOV = 230x173 mm2, in-plane resolution = 0.72x0.72 mm2, and slice thickness = 5 mm. [Training and test] The input was coil-combined images from the under-sampled k-space data by a factor of 4 and 6 in the phase encoding direction (number of ACS line = 32). Coil sensitivity maps were calculated using ESPIRiT6, and the label was images from the full-sampled k-space data. Training was performed in patched data that were cut only in the readout direction not to disturb the artifact coherency. L1 loss and Adam optimizer were used for the training. After training, the whole brain (not patched) was used as input. The result images were compared with conventional parallel imaging methods (GRAPPA and CG-SENSE). Additionally, we evaluated the effect of g-factor attention by comparing gANN results with those from deep learning without the attention model.
Results
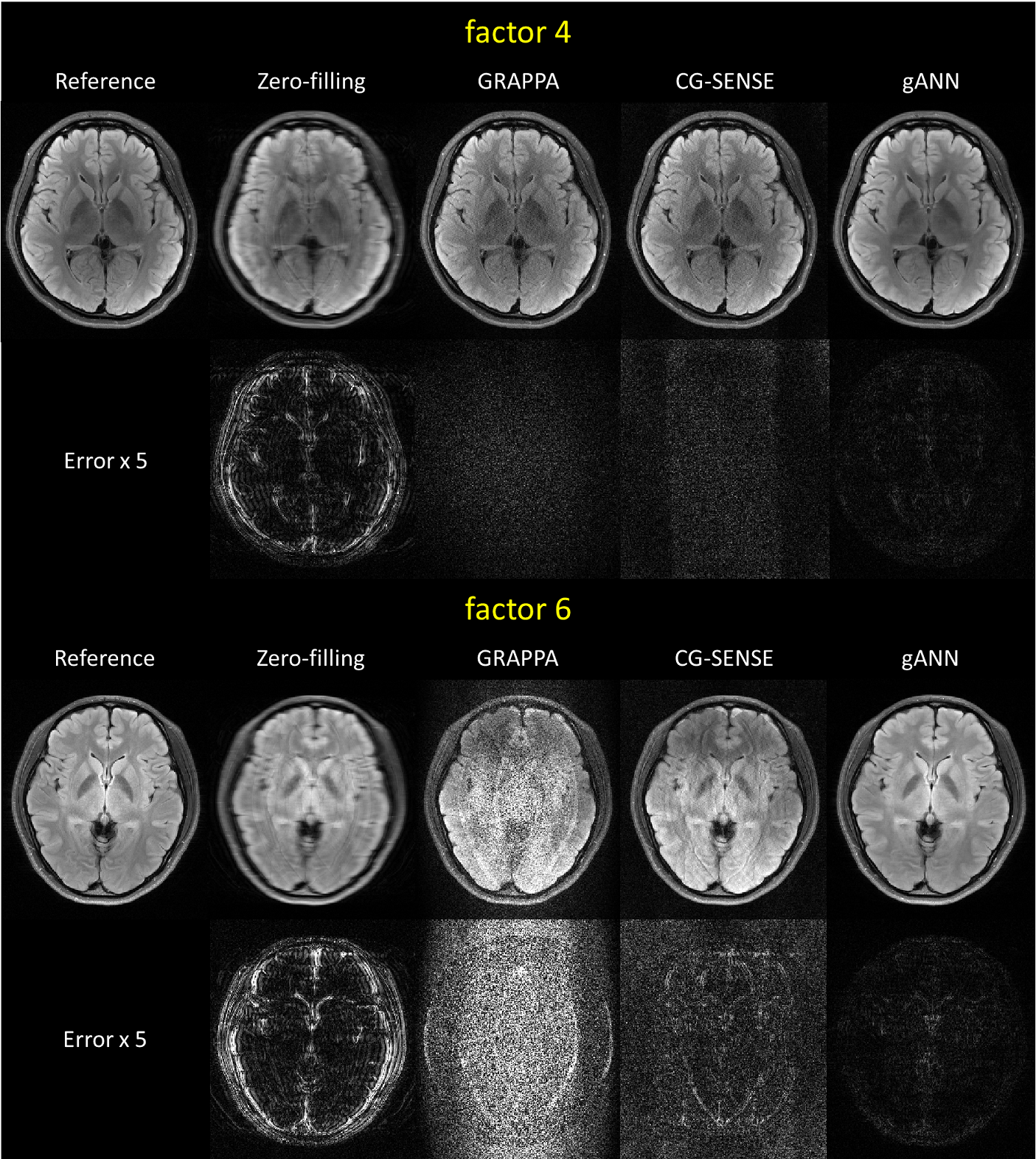
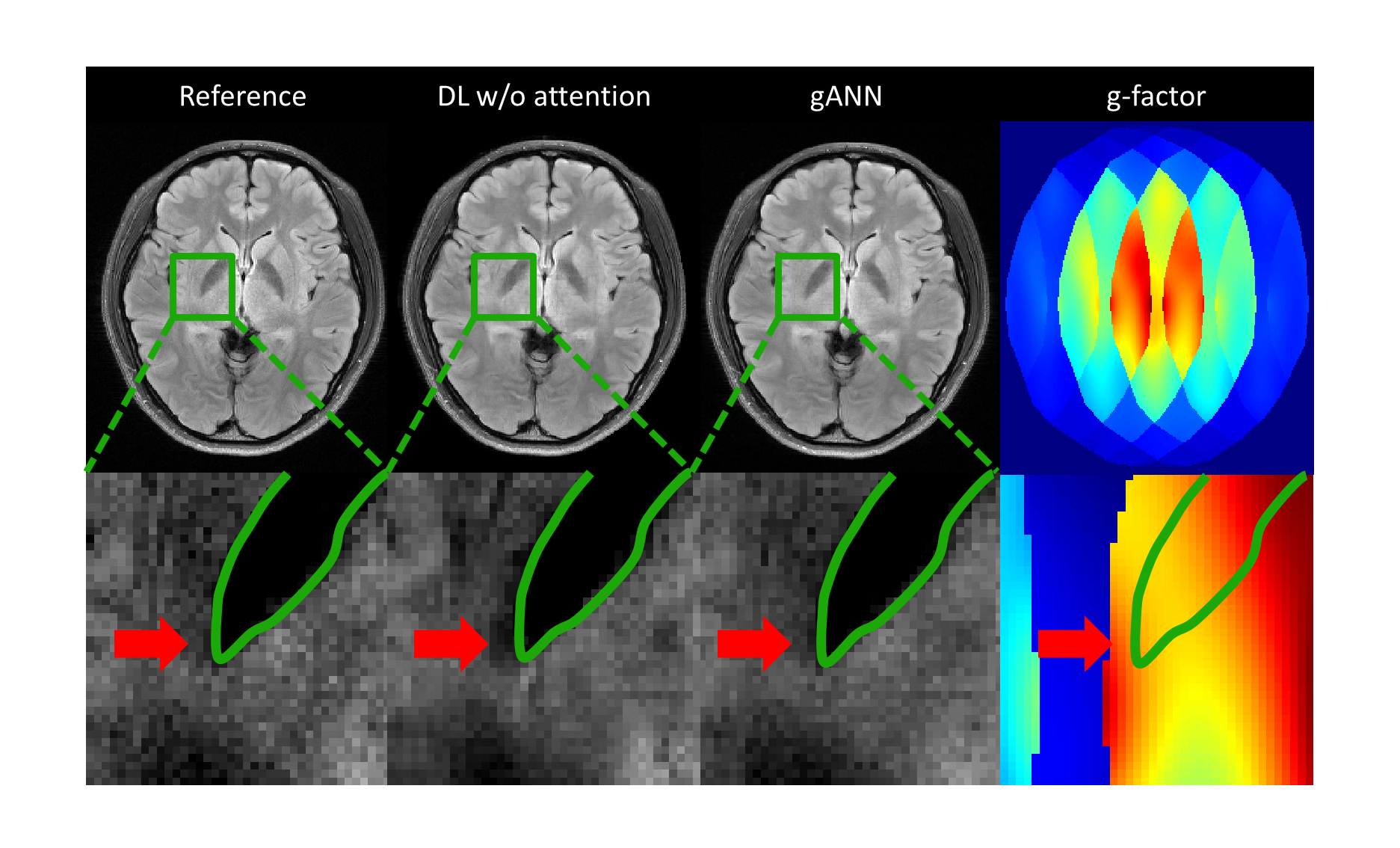
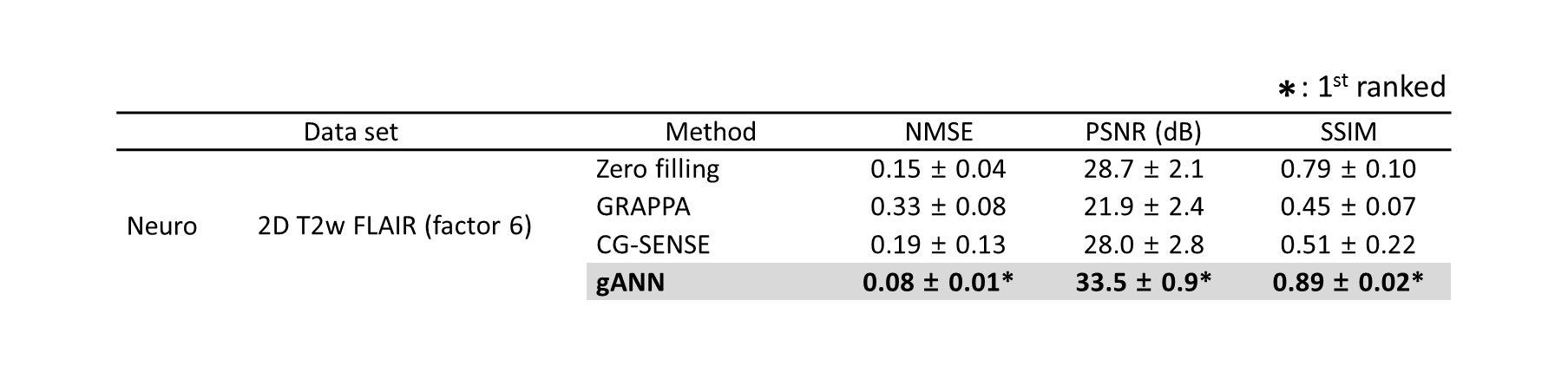
The parallel imaging reconstruction results (GRAPPA, CG-SENSE, and gANN) from under-sampled data by a factor of 4 and 6 are displayed in Figure 2. Additionally, the reconstructed images using zero-filled data and fully-sampled reference data are also shown in the figure. The gANN result successfully removed aliasing artifacts in both factors, showing no clear structure in the difference maps. In Fig. 3, the effect of gANN concept was visualized. The green border in the zoom-in figure indicates the boundary of the globus pallidus structure. gANN successfully reconstructed the boundary whereas deep learning approach with no attention model fails to generate the structure. The red arrow in the zoom-in image shows hallucination that may be the outcome of the conventional neural network. On the other hand, gANN successfully avoided the hallucination and preserved the structure which may be explained by the high g-factor guiding in the gANN network. As shown in the g-factor maps, the hallucination occurred at the region that has high g-factor and large variation (red arrow in Fig. 3). The quantitative measures of gANN results (Table 1) reveal the better results than those of the other methods.Discussion and Conclusion
In this work, we constructed a g-factor attention model to embed the spatial aliasing information in the parallel imaging reconstruction. The proposed method demonstrated better performance in removing the aliasing artifacts. Additionally, the attention by g-factor maps may show advantages of guiding the location of likely-to-be-hallucinated. For further investigation, an optimization of g-factor attention model is expected.Acknowledgements
This work was supported by Creative-Pioneering Researchers Program through SNU and Brain Korea 21 Plus Project in 2018References
[1] Aggarwal, K.A., Mani, M.P., Jacob, M., 2018. MoDL: Model Based Deep Learning Architecture for Inverse Problems. IEEE Trans Medical Imaging.
[2] Hammernik, K., Klatzer, T., Kobler, E., Recht, M.P., Sodickson, D.K., Pock, T., Knoll, F., 2018. Learning a Variational Network for Reconstruction of Accelerated MRI Data. Magn Reson Med; 79:3055-3071.
[3] Ye, J.C., Han, Y., Cha, E., 2018. Deep Convolutional Framelets: A General Deep Learning Framework for Inverse Problems. Society for Industrial and Applied Mathematics J. Imaging Sciences Vol.11, No.2, pp. 991-1048
[4] Lee, D., Yoo, J., Ye, J.C., 2017. Deep residual learning for compressed sensing MRI. IEEE. p 15-18.
[5] Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones, L., Gomez, A.N., Kaiser, L., Polosukhin, I., 2017. Attention Is All You Need. arXiv: 1706.03762v5
[6] Uecker, M., Lai, P., Murphy, M.J., Virtue, P., Elad, M., Pauly, J.M., Vasanawala, S.S., Lustig, M., 2014. ESPIRiT—an eigenvalue approach to autocalibrating parallel MRI: where SENSE meets GRAPPA. Magn Reson Med ;71(3):990-1001.
Figures