4715
Deep Inception Residual Network (DIRN) for Reconstruction of Undersampled Brain MR Image1Graduate program in Biomedical Engineering The Graduate School, Yonsei University, Seoul, Korea, Republic of, 2Brain Korea 21 PLUS Project for Medical Science, Yonsei University, seoul, Korea, Republic of, 3Yonsei-Cedars-Sinai Integrative Cardiac Imaging Research Center, seoul, Korea, Republic of, 4Division of Cardiology, Severance Cardiovascular Hospital, Yonsei University, College of Medicine, seoul, Korea, Republic of
Synopsis
Acquiring the full-sampling k-space magnetic resonance imaging (MRI) data for detailed anatomical information is ideal. We propose the Deep Inception Residual Network (DIRN) based on a deep convolutional neural network (
INTRODUCTION
Acquiring the full-sampling k-space magnetic resonance imaging (MRI) data for detailed anatomical information is ideal. There is a tradeoff between the long scan time and the amount of the k-space data. Recently the methods based on neural networks have shown remarkable performance in MRI reconstruction from undersampled k-space data. We propose the Deep Inception Residual Network (DIRN) based on a deep convolutional neural network (DCNN) consisting of inception blocks and residual blocks for the reconstruction of the MR image from undersampled k-space data. The experimental results on an ADNI dataset demonstrate that DIRN is appropriate for a reconstruction of brain MR images.
METHODS
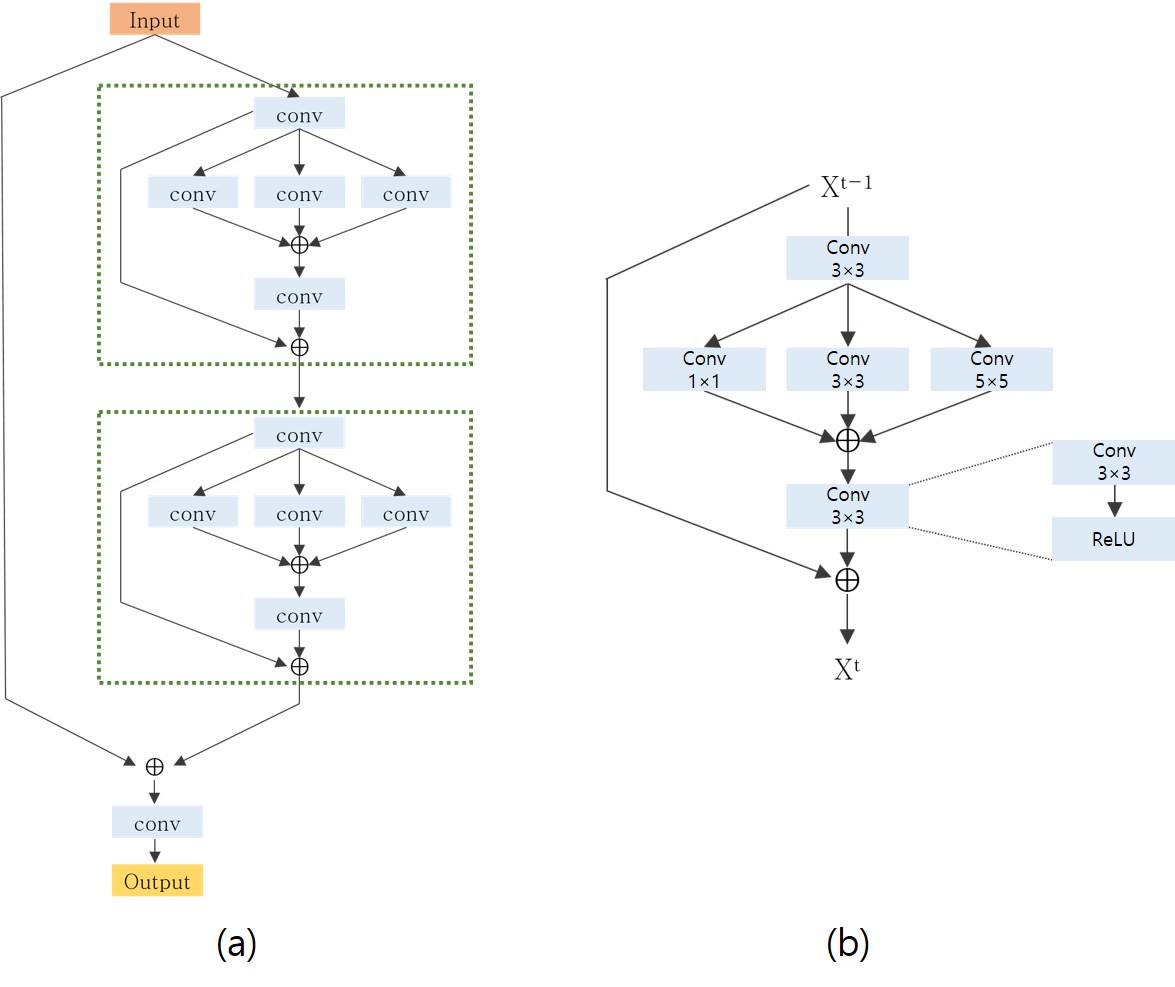
We propose a patch-wise learning based network namely DIRN which incorporates inception blocks and residual blocks to deal with the reconstruction of undersampled k-space data. Fig.1 presents our proposed DIRN architecture. We employ an inception block 1 and a residual block 2. The standard convolution neural network uses 3 $$$\times$$$ 3 convolution kernel which is insufficient for the reconstruction of MR image having a scale-variant anatomical structure. In inception block, the input feature maps are convolved with different size of the kernel (size of 1, 3 and 5) which aggregates the different scale of features. Most of the deep neural network for the reconstruction of MRI representing a high complexity of features leads to a large number of a parameter which is likely to vanish gradient during training. The residual path bypasses the nonlinear layer with an identity mapping allowing our network to learn easier without gradient vanishing problem. We iteratively stack several inception residual blocks which are shown Fig. 1 (a) following the last convolution layer to reconstruct undersampled k-space MR image. The global residual branch is added to the final layer of the network as an identity mapping via the residual path. The DIRN can be formulated as follows: $$y = IR_{d}(IR_{d-1}(...(IR_{1}(x))... ))+x$$ where x and y are the input and output of the networks respectively. $$$IR_{d}$$$ denotes the d-th inception residual block. The symbol + denotes the pixel-wise addition in each channel of feature maps. We used the pixel-wise addition instead of stacking the feature channels such that the output dimensions are the same as those of the input dimensions without increasing the number of redundant features. We use the mean square error (MSE) as the loss function to train the DIRN. The weight of the kernel is initialized with Xavier initialization and all parameters are initialized from scratch. We use an adaptive moment optimization for optimization with the weight decay of 0.0005 and learning rate of 1e-3. Our network is implemented on the Tensorflow with Titan XP.
EXPERIMENTS
We have trained and validated our network with a dataset obtained from the Alzheimer's Disease Neuroimaging Initiative (ADNI), publicly available from www.loni.ucla.edu ADNI 3. The total number of 2D image slices are 15,190 MR images with the T2-weighted longitudinal scans of the human brain are used. The training and test datasets are 30 and 15 subjects randomly chosen from 151 subjects. To train our network, fully sampled k-space MR data is used to create the undersampled MR image for an input data. We retrospectively undersampled the k-space data corresponding to the T2-weighted image with 2D random sampling. The input image patch (size of 32 $$$\times$$$ 32) is taken from the input image (size of 256 $$$\times$$$ 256) and fed into the network. The implementation details are as follow: the total number of iteration (d) = 13, the size of batch = 10, the mini-batch size = 30, the number of output channels in convolution layer = 32. It took 17 hours to train our network, and the average time of prediction for one frame is 0.03 seconds using GPU.
RESULT AND DISCUSSION
The performance of DIRN is evaluated based on the peak-to-noise ratio (PSNR) and the structural similarity (SSIM). The PSNR is used to evaluate the quality assessment reconstruction. The SSIM is chosen to quantify the perceptual similarity. The qualitative result of the reconstruction using 2D random sampling at 2.5, 4, 6, 8, 10 and 20 fold undersampling is shown in Fig. 2. The quantitative result of DIRN and zero-filled reconstruction shows that the improvement of DIRN can achieve the highest improvement of 39.4% (23.09 to 32.20) and 87% (0.39 to 0.73) in PSNR and SSIM with the severe undersampling factor of 20 (Fig. 3). This is beneficial to clinical treatment process not only shorten the acquisition time of brain MR image data affected by a patient’s movement but also ensure the image quality crucial for making a clinical decision.
Acknowledgements
No acknowledgement found.References
1. Szegedy, C., Liu, W., Jia, Y., Sermanet, P., Reed, S., Anguelov, D., Erhan, D.,Vanhoucke, V., Rabinovich, A.: Going deeper with convolutions. Cvpr.
2. He, K., Zhang, X., Ren, S., Sun, J.: Deep residual learning for image recognition. In: Proceedings of the IEEE conference on computer vision and pattern recognition.pp. 770-778
3. Jack, C.R., Bernstein, M.A., Fox, N.C., Thompson, P., Alexander, G., Harvey, D.,Borowski, B., Britson, P.J., L Whitwell, J., Ward, C.: The alzheimer's disease neuroimaging initiative (adni): Mri methods. Journal of magnetic resonance imaging27(4), 685{691 (2008)
Figures
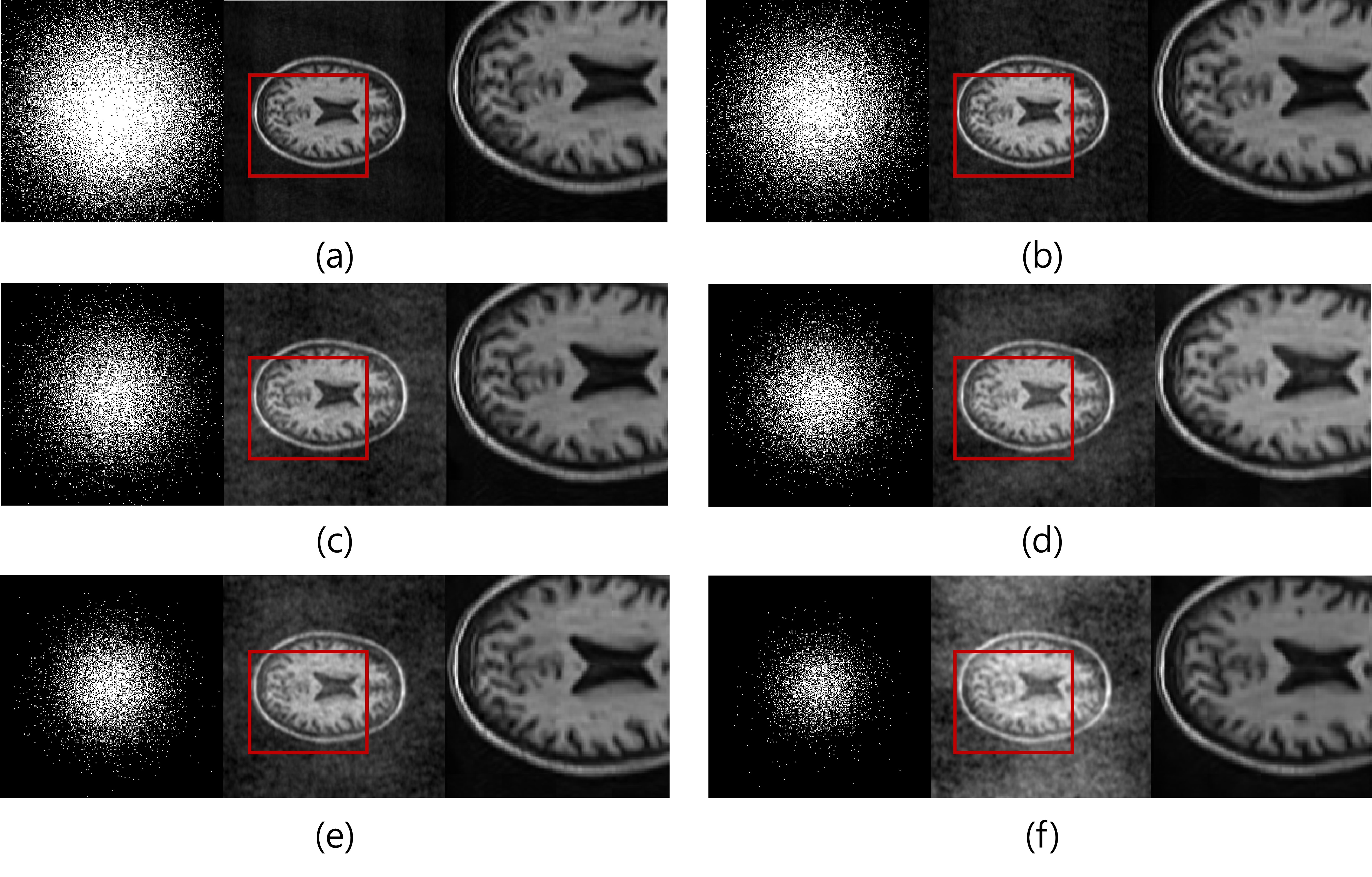
Reconstruction using different undersampling factors of 2.5, 4, 6, 8, 10 and 20 is shown in Fig. 2 (a)~(f). The left image is the 2D random sampling mask. The middle image is the undersampled image for an input of our network. The right image is the result of the reconstruction using DIRN.
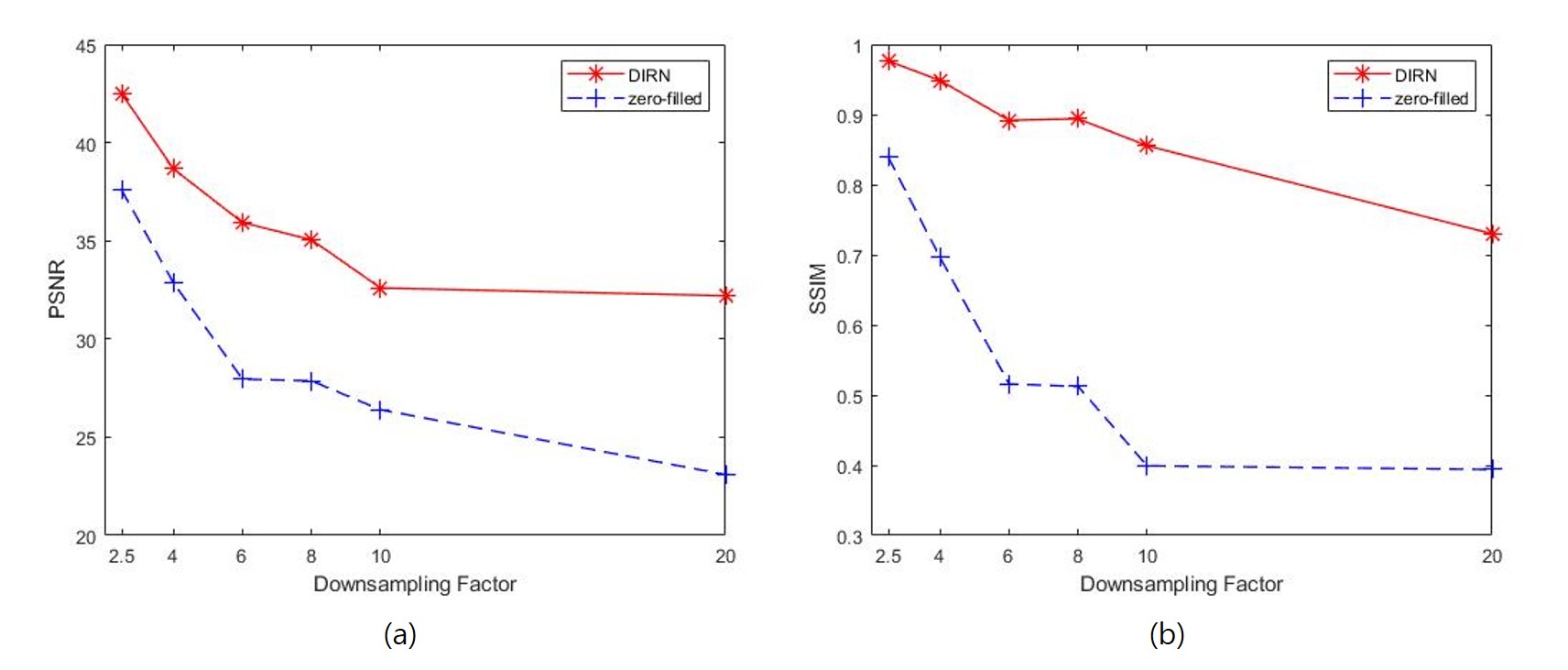
(a) PSNR versus undersampling factor for DIRN and zero-filled reconstruction. (b) SSIM versus undersampling factor for DIRN and zero-filled reconstruction. Denote that the higher the PSNR and SSIM, the better the quality of the reconstructed image.