4712
Edge-enhanced Loss Constraint for Deep Learning Based Dynamic MR Imaging1Paul C. Lauterbur Research Center for Biomedical Imaging, Shenzhen Institutes of Advanced Technology, Shenzhen, China, 2Research center for Medical AI, Shenzhen Institutes of Advanced Technology, Shenzhen, China, 3Department of Biomedical Engineering and Department of Electrical Engineering, The State University of New York, Buffalo, NY, United States
Synopsis
Cardiac magnetic resonance (MR) imaging provides a powerful imaging tool for clinical diagnosis. However, due to the constraints of magnetic resonance (MR) physics and reconstruction algorithms, dynamic MR imaging takes a long time to scan. Recently, deep learning has achieved preliminary success in MR reconstruction. Compared with the classical iterative optimization algorithms, the deep learning based methods can get improved reconstruction results in shorter time. However, most current deep convolutional neural network (CNN) based methods use mean square error (MSE) as the loss function, which might be a reason for image smooth in the reconstruction. In this work, we propose to employ edge-enhanced constraint for loss function and explore different types of total variation on network training. Encouraging performances have been achieved.
Introduction
Cardiac MR imaging is an important research topic since it can obtain both rich anatomical and appealing spatiotemporal information. Nevertheless, the image acquisition is still time-consuming due to the limitations of MR physics and reconstruction algorithms. Recently, deep learning has achieved preliminary success in MR reconstruction[1-2][6-11]. CNN-based methods [1][2] can achieve improved reconstruction results in shorter time compared to classical compressed sensing (CS) or low rank based methods for dynamic MR imaging[3]-[4]. However, there is still a certain degree of smooth in the reconstructed images at high acceleration factors. Part of the reasons may be the loss functions, mean squared error (MSE), used in these works. The MSE loss functions only indicate the mean square information between the reconstructed image and the ground truth and cannot perceive the image structure information. In this work, we explore the impacts of different edge-enhanced prior constraints on network training, including isotropic total variation (TV), anisotropic TV and higher degree total variation (HDTV) [6]. The experimental results show that the reconstruction can be improved by adding TV constraints and the anisotropic TV works best.Theory and method
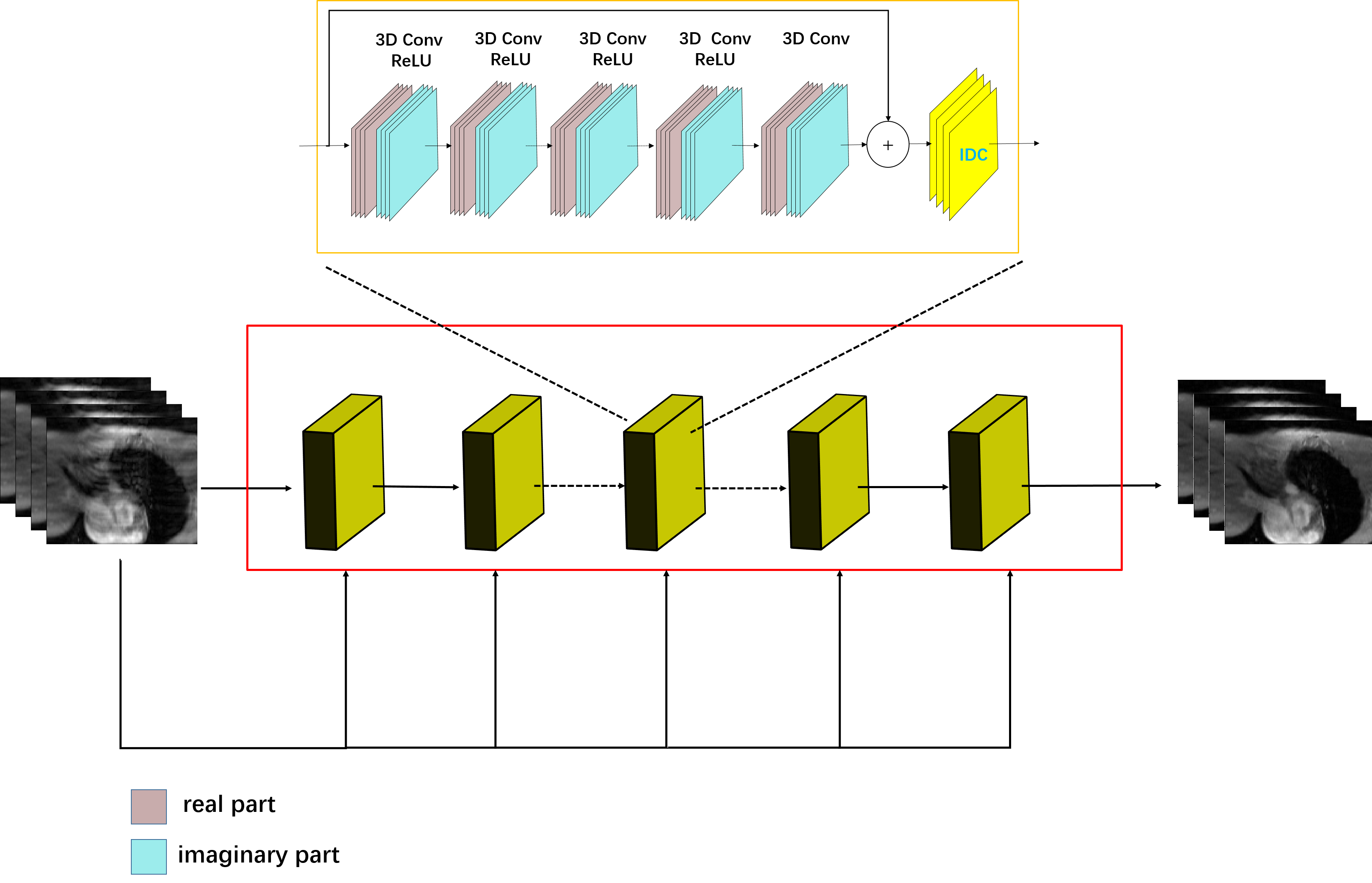
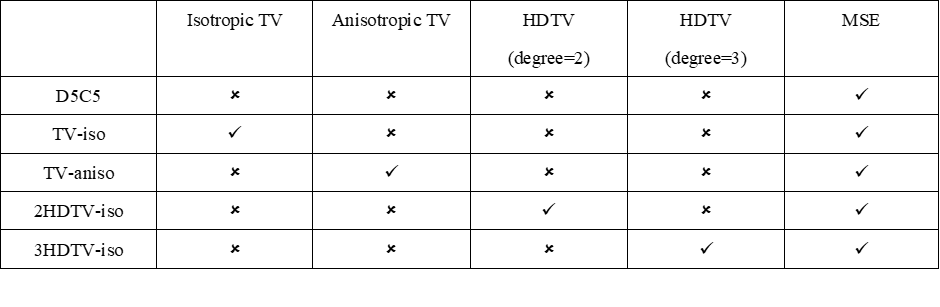
The DC-CNN [1] model is selected as our network framework as shown in Figure 1. To explore the effects of TV constraints on dynamic MR reconstruction, we configure five CNN models as shown in Table 1. Specifically, the Model 0 is the original DC-CNN model, whose loss function is MSE.The isotropic TV constraint is introduced into the loss function of the Model 1, where the isotropic TV constraint is defined in Eq. (1). The Model 2 introduces anisotropic TV constraint (as shown in Eq. (2)). And the Model 3 and Model 4 respectively introduce the HDTV (degree=2 and degree=3), whose definitions are shown in Eq. (3) and (4). The derivation and symbols of the formula can be referred in [6].
$${\rm TV}_{iso}(f)=\int_{\Omega} \sqrt{(\frac{\partial f(r)}{\partial x})^2+(\frac{\partial f(r)}{\partial y})^2}dr\ \ \ \ \ (1)$$
$${\rm TV}_{aniso}(f)=\int_{\Omega} |\frac{\partial f(r)}{\partial x}|+|\frac{\partial f(r)}{\partial y}|dr\ \ \ \ \ (2)$$
$${\rm HDTV}_{2}(f)=\int_{\Omega}\sqrt{(3|f_{xx}|^2+3|f_{yy}|^2+4|f_{xy}|^2+2\mathcal{R}(f_{xx}f_{yy}))/8}dr\ \ \ \ \ (3)$$
$${\rm HDTV}_{3}(f)=\int_{\Omega}\sqrt{5(|f_{xxx}|^2+|f_{yyy}|^2)+6\mathcal{R}(f_{xxx}f_{xyy}+f_{yyy}f_{xxy})+9(|f_{xxy}|^2+|f_{xyy}|^2)}dr/4\sqrt(2)\ \ \ \ \ (4)$$
The loss functions can be defined as the following paradigm:
$${\rm loss\ \ function}={\rm MSE}(f, \hat{f})+\lambda{\rm TV}(f)\ \ \ \ (5)$$
where $$$f$$$ is the reconstructed image and $$$\hat{f}$$$ is the ground truth. $$$\lambda$$$ is a hyper-parameter and we set $$$\lambda=10^{-8}$$$ here.
Experiment
We collected 101 fully sampled cardiac MR data using a 3T scanner (SIMENS MAGNETOM Trio) with T1-weighted FLASH sequence. Multi-coil data were combined to a single channel and then retrospectively undersampled using 1D random Cartesian masks [3]. After normalization and extraction, we got 17502 cardiac data, where 15000, 2000, and 502 were used for training, validating, and testing, respectively. The models were implemented on an Ubuntu 16.04 LTS (64-bit) operating system equipped with an Intel Xeon E5-2640 Central Processing Unit (CPU) and a Tesla TITAN Xp Graphics Processing Unit (GPU, 12GB memory). The open framework Tensorflow was used.Results and discussion
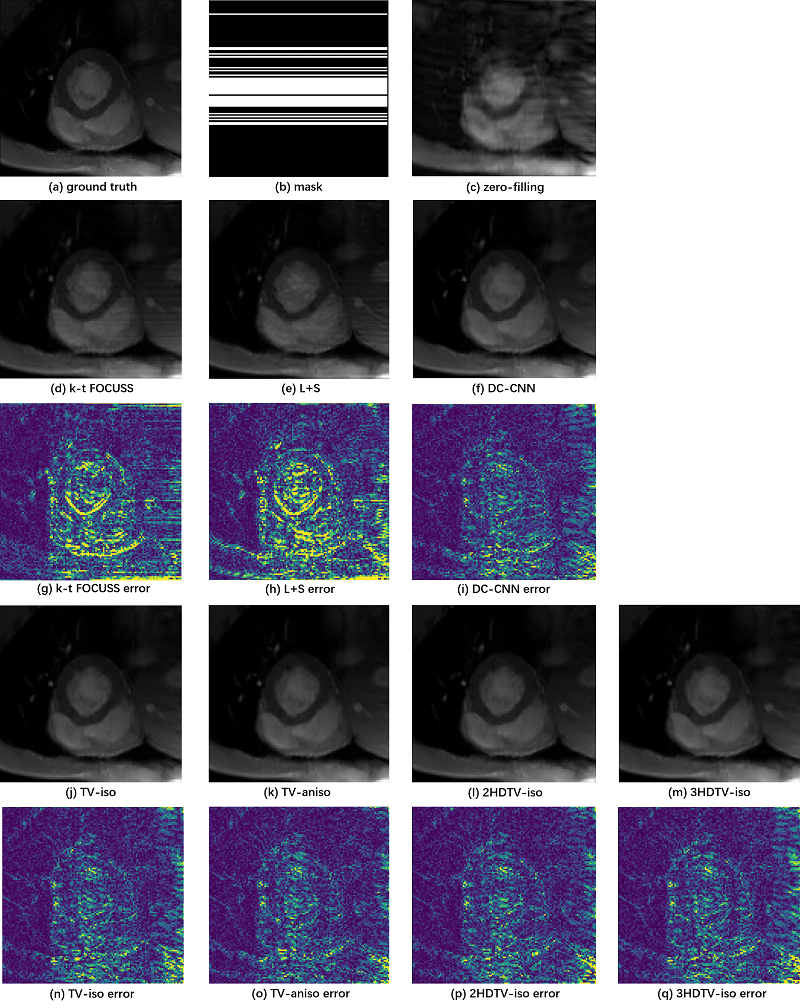
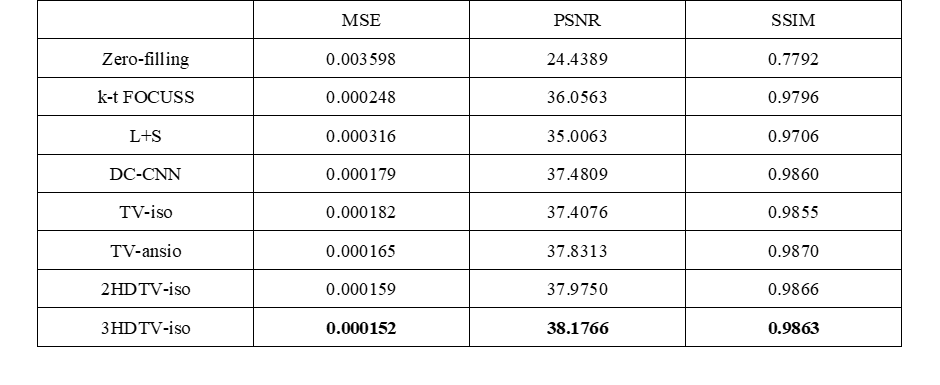
To demonstrate the efficacy of different TV constraints, we compare them with k-t FOCUSS, L+S, and the state-of-the-art method DC-CNN. We adjust the parameters of the CS-MRI methods to their best performance. The reconstructions of these methods are shown in Figure 3. The two CS-based reconstruction contain less structural details than the reconstruction of CNN-based methods. Compared to the DC-CNN model, all the TV-based methods can not only retain the details, but also remove the artifacts better. Especially, the anisotropic TV gets the best reconstruction results. The evaluation metrics are presented in Table 2, where the TV-based methods achieve improved quantitative indicators with lower MSE, higher PSNR and higher SSIM.Conclusion
This paper explores the effects of different TV constraints on cardiac MR reconstruction. The experimental results show that the reconstruction can be improved by adding TV constraints, of which the anisotropic TV works best and the HDTV obtains the best performance indicators. More exploration of the HDTV will take place in the future work.Acknowledgements
Grant support: China NSFC 61471350, 61601450, the Natural Science Foundation of Guangdong 2015A020214019, 2015A030310314, the Basic Research Program of Shenzhen JCYJ20140610152828678, JCYJ20160531183834938, JCYJ20140610151856736 and US NIH R21EB020861 for Ying.References
[1]. J. Schlemper, J. Caballero, J.V. Hajnal, A. Price, D. Rueckert, “A Deep Cascade of Convolutional Neural Networks for Dynamic MR Image Reconstruction”, IEEE TMI, DOI: 10. 1109/TMI.2017.2760978 (2017)
[2]. Qin, Chen, Joseph V. Hajnal, Daniel Rueckert, Jo Schlemper, Jose Caballero, and Anthony N. Price. "Convolutional recurrent neural networks for dynamic MR image reconstruction." IEEE transactions on medical imaging (2018).
[3]. Jung, Hong, Jong Chul Ye, and Eung Yeop Kim. "Improved k–t BLAST and k–t SENSE using FOCUSS." Physics in Medicine & Biology 52, no. 11 (2007): 3201.
[4]. Lingala, Sajan Goud, Yue Hu, Edward DiBella, and Mathews Jacob. "Accelerated dynamic MRI exploiting sparsity and low-rank structure: kt SLR." IEEE transactions on medical imaging30, no. 5 (2011): 1042-1054.
[5]. Otazo, Ricardo, Emmanuel Candès, and Daniel K. Sodickson. "Low‐rank plus sparse matrix decomposition for accelerated dynamic MRI with separation of background and dynamic components." Magnetic Resonance in Medicine 73, no. 3 (2015): 1125-1136.
[6]. Han, Yoseob, Jaejun Yoo, Hak Hee Kim, Hee Jung Shin, Kyunghyun Sung, and Jong Chul Ye. "Deep learning with domain adaptation for accelerated projection‐reconstruction MR." Magnetic resonance in medicine 80, no. 3 (2018): 1189-1205.
[7] H.K. Aggarwal, M.P Mani, and Mathews Jacob, MoDL: Model Based Deep Learning Architecture for Inverse Problems, IEEE Transactions on Medical Imaging, 2018
[8]. Qin, Chen, Joseph V. Hajnal, Daniel Rueckert, Jo Schlemper, Jose Caballero, and Anthony N. Price. "Convolutional recurrent neural networks for dynamic MR image reconstruction." IEEE transactions on medical imaging (2018).
[9]. Zhu, Bo, Jeremiah Z. Liu, Stephen F. Cauley, Bruce R. Rosen, and Matthew S. Rosen. "Image reconstruction by domain-transform manifold learning." Nature 555, no. 7697 (2018): 487.
[10]. Eo, Taejoon, Yohan Jun, Taeseong Kim, Jinseong Jang, Ho‐Joon Lee, and Dosik Hwang. "KIKI‐net: cross‐domain convolutional neural networks for reconstructing undersampled magnetic resonance images." Magnetic resonance in medicine (2018).
[11]. K. Hammernik, T. Klatzer, E. Kobler, M. P. Recht, D. K.Sodickson, T. Pock, and F. Knoll, “Learning a variationalnetwork for reconstruction of accelerated MRI data,”Magnetic Resonance in Medicine, vol. 79, no. 6, pp.3055–3071, 2018.14.
Figures