4699
Volumetric real-time imaging with deep-learning reconstruction1Radiology, University of California, Los Angeles, Los Angeles, CA, United States, 2Electrical and Computer Engineering, University of California, Los Angeles, Los Angeles, CA, United States
Synopsis
We propose a deep-learning reconstruction pipeline for 3D real-time imaging. We use a 3D golden-angle GRE sequence, and a deep-learning network based reconstruction. Gadgetron framework is used for real-time pipelining. Using 320 images in total, our network is trained with decaying data fidelity update, and deployed without it. Dilated convolution and skip concatenation improve the image quality. We achieved a Matrix size of 192x192x8 pixels, a temporal resolution of 889ms, a reconstruction time of 300-350ms, and our image quality is comparable to iGRASP.
Introduction
Real-time MRI provides unprecedented advantages for many MRI-guided applications, like intervention1, therapy2, and biopsy3. Previous solutions, including Siemens product real-time Cartesian protocol, and Gadgetron golden-angle real-time protocol4, are limited to single-slice 2D images. In this abstract, we propose a 3D real-time pipeline, that achieves volumetric coverage of 8 slices, with high image quality, high frame rate, and fast reconstruction. The pipeline is built upon and modified from Gadgetron framework4, with a 3D golden-angle stack-of-radial GRE sequence. To achieve fast and high-quality reconstruction, we propose a convolutional neural network (CNN) based reconstruction. The CNN network is written in PyTorch5, and it uses dilated convolution with skip concatenation. The network is trained with explicit data fidelity component, where it decays during the training and is removed during the deployment of the reconstruction, to ensure fast reconstruction time without compromising data fidelity.Methods
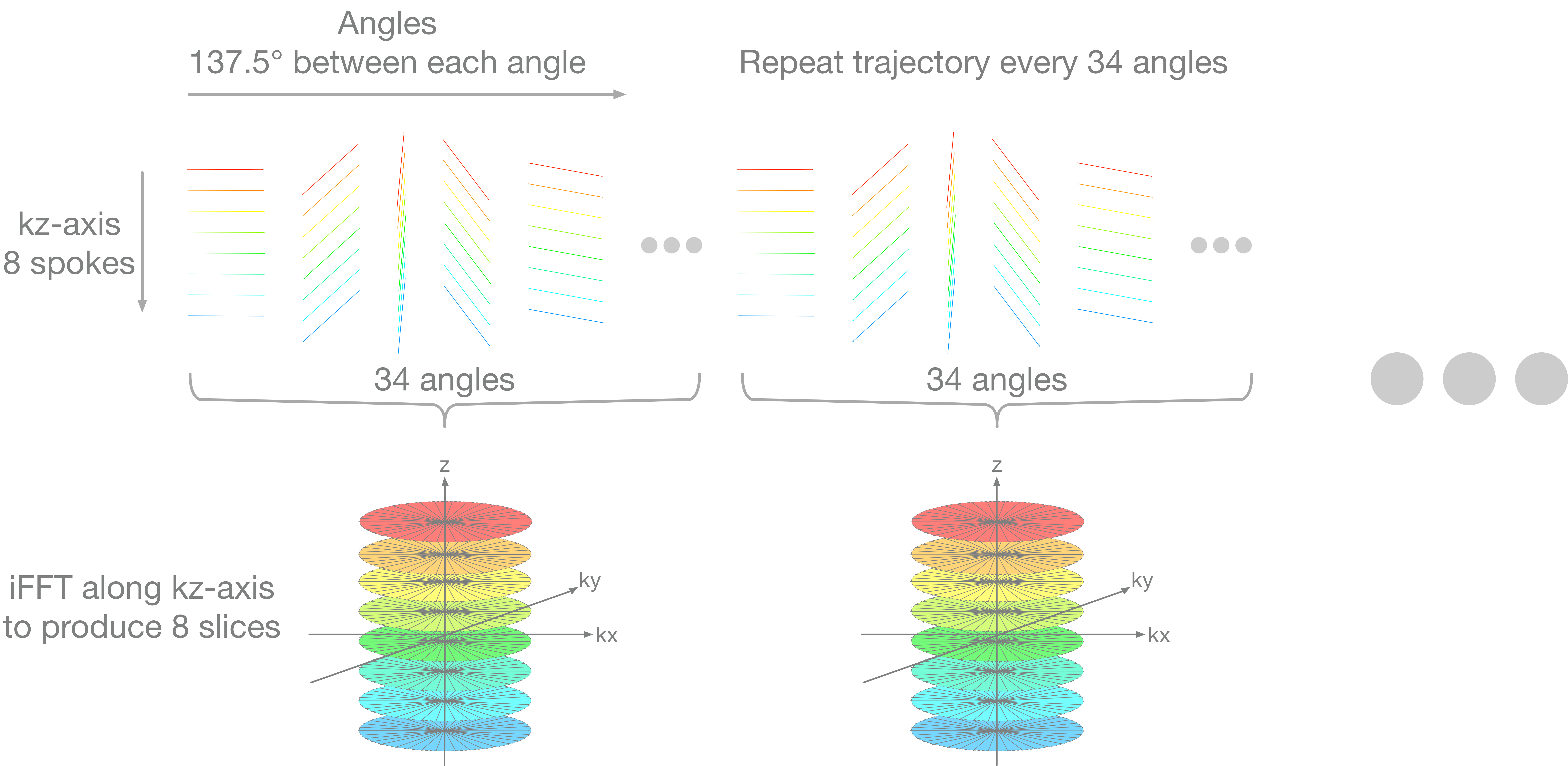
The 3D stack-of-radial golden-angle sequence with gradient calibration6 is used. Its trajectory pattern is shown in Figure 1. Each spoke is a readout line in k-space with 384 data points, including 2x oversampling. TR is 3.27ms and the temporal footprint is 889ms for 34 angles. This pattern is repeated for every frame of 34 angles, so the streaking artifacts are consistent between frames7.
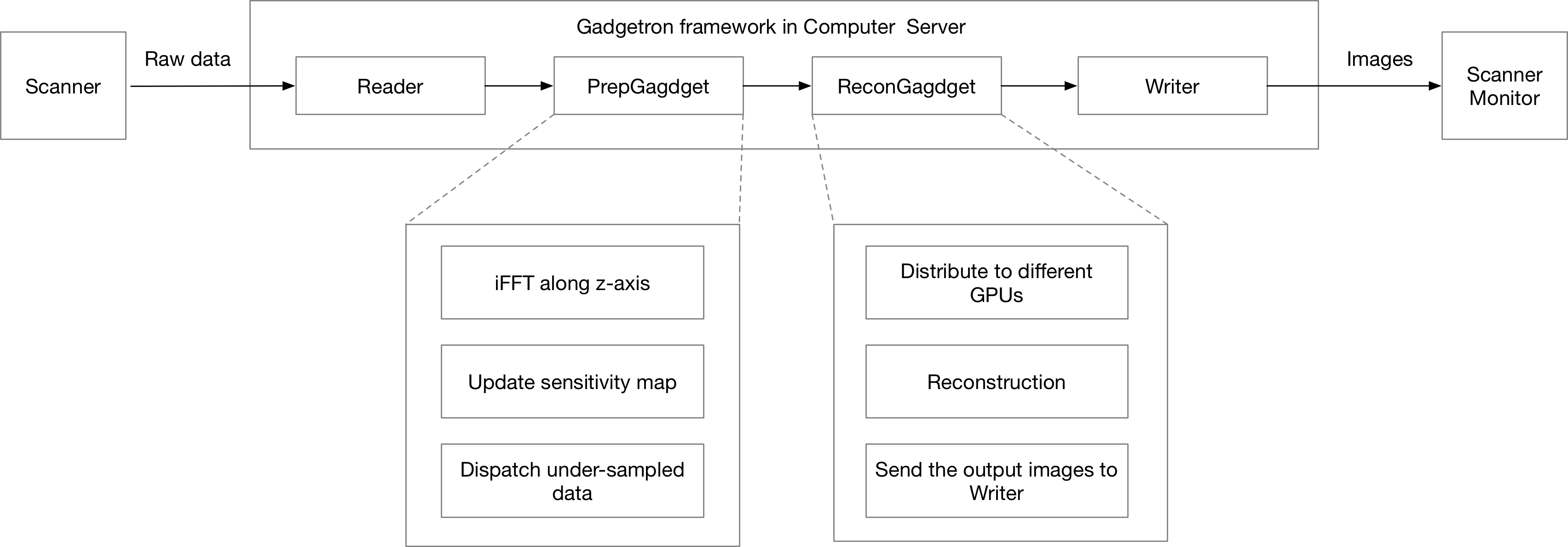
The data from the sequence are streamed to the Gadgetron client in our computer server via TCP/IP. A simplified schematic is as shown in Figure 2. Once the reconstruction is finished for each image, the image is passed back to the scanner computer.
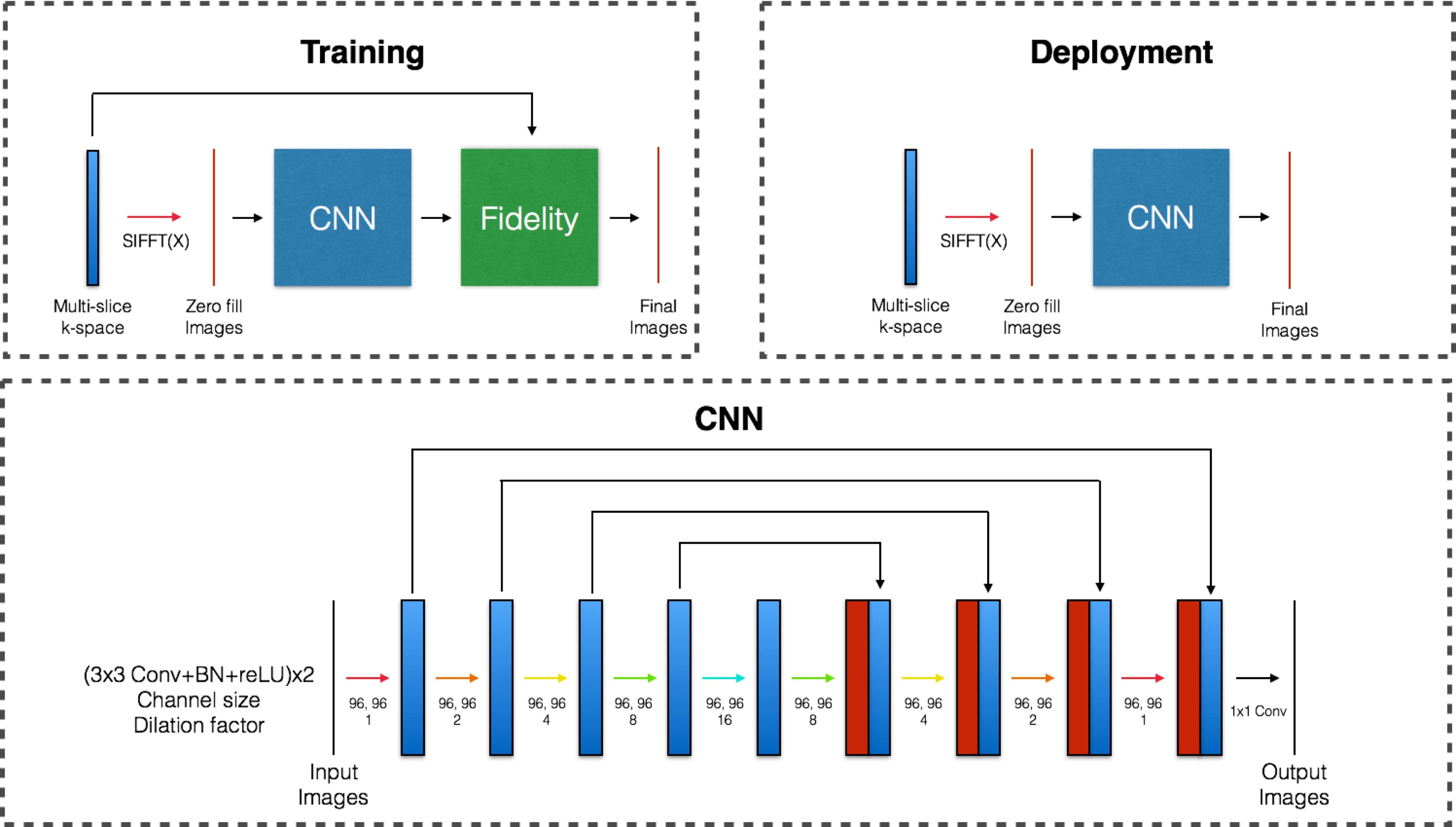
For reconstruction, the network is as shown in Figure 3. Input to the network is radial k-space, trajectory, sensitivity map, and density-weighted function. The training and deployment use different network. The CNN network is a 19-layer network with skip concatenations and dilation factor of up to 16. The skip concatenations implicitly enforces data fidelity8. The dilated convolution increases receptive field9. For training, an explicit fidelity is applied, and MSE loss is used. The loss function becomes:
$$Loss = MSE(ref, X)$$
$$X = X_0+ \lambda \times Fidelity$$
$$ Fidelity = ( \mathcal{S'F’FS}X_0– \mathcal{S'F’}Y)$$
$$$X$$$ is the final image output, and $$$X_0$$$ is the image output of CNN. $$$Y$$$ is the under-sampled radial k-space, $$$\mathcal{F}$$$ is the non-uniform FFT, and $$$\mathcal{S}$$$ is the sensitivity map. The learning rate decays from $$$1 \times 10^{-3}$$$ to $$$1 \times 10^{-6}$$$. $$$\lambda$$$ is a decaying weight, which equals 1 initially, and decays at the same rate as the learning rate. For deployment, $$$\lambda$$$ becomes 0, and the explicit data fidelity component is dropped. NuFFT used in this reconstruction is Gadgetron standalone nuFFT application. To save reconstruction time, a C++ python module is written to pass the CUDA pointer in GPU to PyTorch directly, so that it does not need to transfer back and forth between GPU memory and CPU memory. The total reconstruction time is 300-350ms.
The data used for training and testing are breath-hold liver images, from a 2D multi-slice golden-angle GRE sequence. 13 volunteer data are used for training, and 3 are for testing. 5-fold rotating cross-validation are performed. Each volunteer data contains 20 slices, 302 angles and 384 readout points. Sensitivity maps are calculated from reference images.
Results
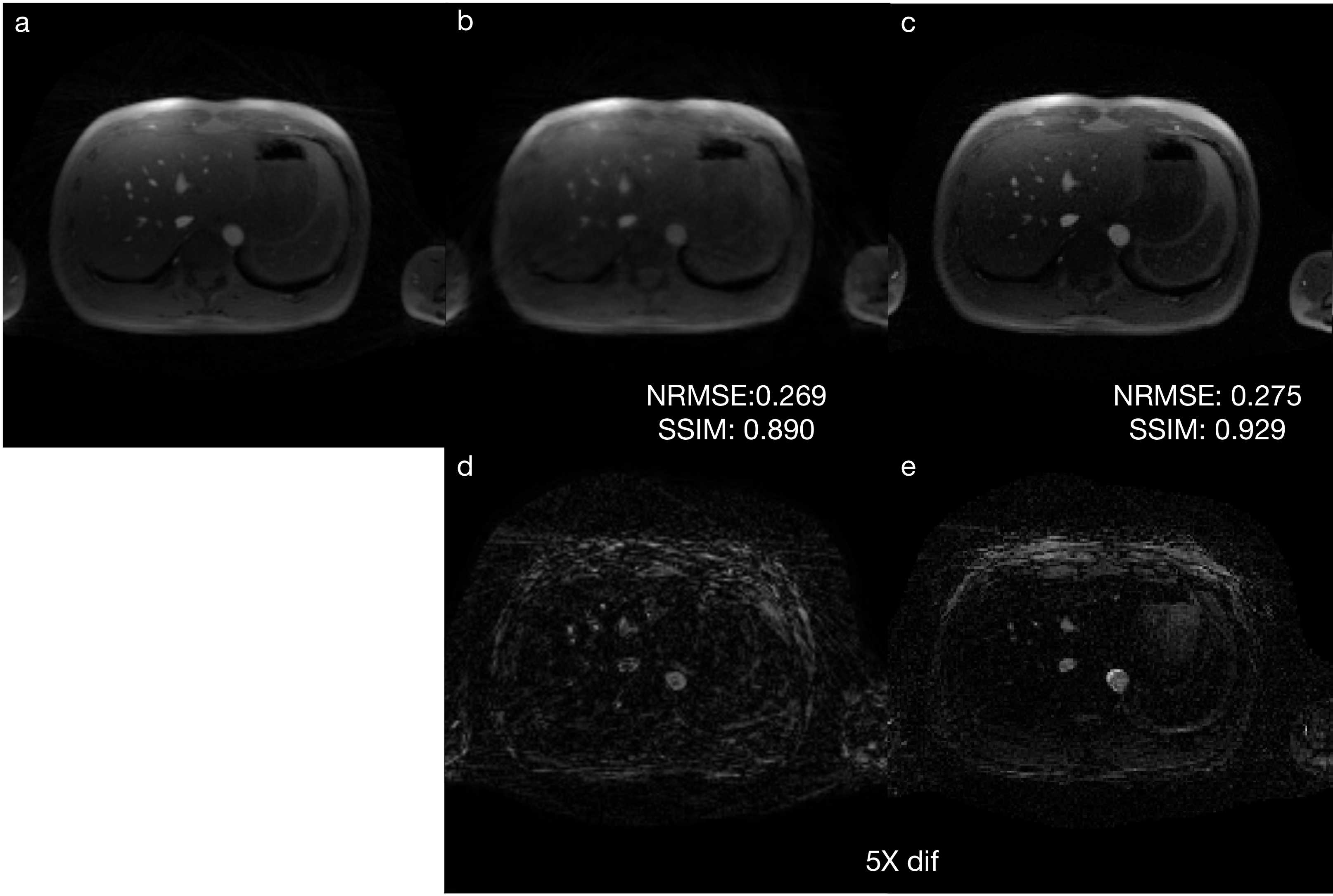
Our results are as shown in Figure 4, the NRMSE and SSIM are the average numbers among all the slices in the testing data in 5-fold cross-validation. The results are compared with iGRASP10, which an iterative-sense with temporal Total Variation constraint. It is configured in its default setting, with 3 repetitions of 4 objective gradient descent iterations, and at most 6 line-search iterations. The NRMSE and SSIM are averages of all slices in all 16 datasets.The specification of sequence we used are compared to Siemens BEAT_IRTTT real-time Cartesian GRE sequence.
As shown in Table 1, our method has a volumetric coverage of 8 slices, whereas Siemens Cartesian sequence has only a single-slice output.
Discussion
The results from our testing images are comparable to that acquired by iGRASP in terms of NRMSE, and is slightly worse in terms of SSIM. This is because the loss function for the training of our method is MSE loss, so it performs relatively better in NRMSE. iGRASP uses many iterations of explicit data fidelity, so the images look much sharper, but the contrast is off from the ground truth. The 5-fold cross-validation indicates that our method is robust, even with the small number of training datasets from 13 volunteers.
Conclusion
We develop a 3D real-time imaging scheme that can cover an acquisition matrix size of 192x192x8 and temporal resolution of 700ms, without compromising image quality, with 300-350ms reconstruction runtime. Our proposed CNN reconstruction network included dilated convolution and skip concatenation, and decaying data fidelity for training.Acknowledgements
No acknowledgement found.References
1.Oborn, B. M., Dowdell, S. , Metcalfe, P. E., Crozier, S. , Mohan, R. and Keall, P. J. (2017), Future of medical physics: Real‐time MRI‐guided proton therapy. Med. Phys., 44: e77-e90. doi:10.1002/mp.12371
2. Hushek, S. G., Martin, A. J., Steckner, M. , Bosak, E. , Debbins, J. and Kucharzyk, W. (2008), MR systems for MRI‐guided interventions. J. Magn. Reson. Imaging, 27: 253-266. doi:10.1002/jmri.21269
3. Kaplan, I., Oldenburg, N. E., Meskell, P., Blake, M., Church, P., & Holupka, E. J. (2002). Real time MRI-ultrasound image guided stereotactic prostate biopsy. Magnetic resonance imaging, 20(3), 295-299.
4. Hansen, M. S. and Sørensen, T. S. (2013), Gadgetron: An open source framework for medical image reconstruction. Magn Reson Med, 69: 1768-1776. doi:10.1002/mrm.24389
5. Paszke, A., Chanan, G., Lin, Z., Gross, S., Yang, E., Antiga, L., & Devito, Z. (2017). Automatic differentiation in PyTorch, (Nips), 1–4.
6. Armstrong, T., Dregely, I., Stemmer, A., Han, F., Natsuaki, Y., Sung, K., & Wu, H. H. (2018). Free-breathing liver fat quantification using a multiecho 3D stack-of-radial technique. Magnetic Resonance in Medicine, 79(1), 370–382. https://doi.org/10.1002/mrm.26693
7. Hauptmann A., Arridge S., Lucka F.,2, Muthurangu V., Steeden JA. (2018). Real-time cardiovascular MR with spatio-temporal artifact suppression using deep learning-proof of concept in congenital heart disease. Magn Reson Med, doi:10.1002/mrm.27480
8. Dongwook Lee, Jaejun Yoo and Jong Chul Ye. (2017) Deep artifact learning for compressed sensing and parallel MRI
9. Fisher Yu, Vladlen Koltun Multi-Scale Context Aggregation by Dilated Convolutions
10. Feng L., Grimm R., Block KT, Chandarana H., Kim S., Xu J., Axel L., Sodickson DK, Otazo R. (2014), Golden-angle radial sparse parallel MRI: combination of compressed sensing, parallel imaging, and golden-angle radial sampling for fast and flexible dynamic volumetric MRI. Magn Reson Med 72:707-717
Figures