4698
Conditional generative adversarial network for three-dimensional rigid-body motion correction in MRI1Robarts Research Institute, Western University, London, ON, Canada, 2Department of Medical Biophysics, Western University, London, ON, Canada
Synopsis
In this work we present a deep learning solution for motion correction in brain MRI; specifically we approach motion correction as an image synthesis problem. Motion is simulated in previously acquired brain images; the image pairs (corrupted + original) are used to train a conditional generative adversarial network (cGAN), referred to as MoCo-cGAN, to predict artefact-free images from motion-corrupted data. We also demonstrate transfer learning, where the network is fine-tuned to apply motion correction to images with a different contrast. The trained MoCo-cGAN successfully performed motion correction on brain images with simulated motion. All predicted images were quantitatively improved, and significant artefact suppression was observed.
Introduction
Current tools for addressing head motion in MR imaging are often limited to specific pulse sequences and scanner hardware. A more general tool that does not require pulse-sequence or hardware modifications would be very valuable. Supervised learning with deep convolutional neural networks (DCNNs) is well suited for the problem of motion correction, as it is common for images with motion artefacts to be reacquired – providing a source of training pairs where the input image is motion-corrupted, and the target image is the high-quality re-scan.
Here, we approach motion correction as an image synthesis problem. Motion is simulated in previously acquired brain images; the image pairs (corrupted + original) are used to train a conditional generative adversarial network (cGAN), referred to as MoCo-cGAN, to predict artefact-free images from motion-corrupted data. We also demonstrate transfer learning, where the network is fine-tuned to apply motion correction to images with a different contrast.
Methods
Data preparation: The open source data set used for this study (1) comprises multi-echo FLASH magnitude and phase images (192,160,64) for 53 patients. To simulate rigid motion, k-space lines were rotated and phase shifted according to randomly generated motion profiles, which were parameterized by the time, magnitude and direction of motion, but constrained to realistic motion. Five different motion profiles were applied to each volume (echo 2) to generate 265 motion-corrupted volumes; of these 215 were used for training, 25 for validation, and 25 for testing. The training images were flipped left to right to double the number of training examples. Each volume was broken up into 8 patches (192x160x8).
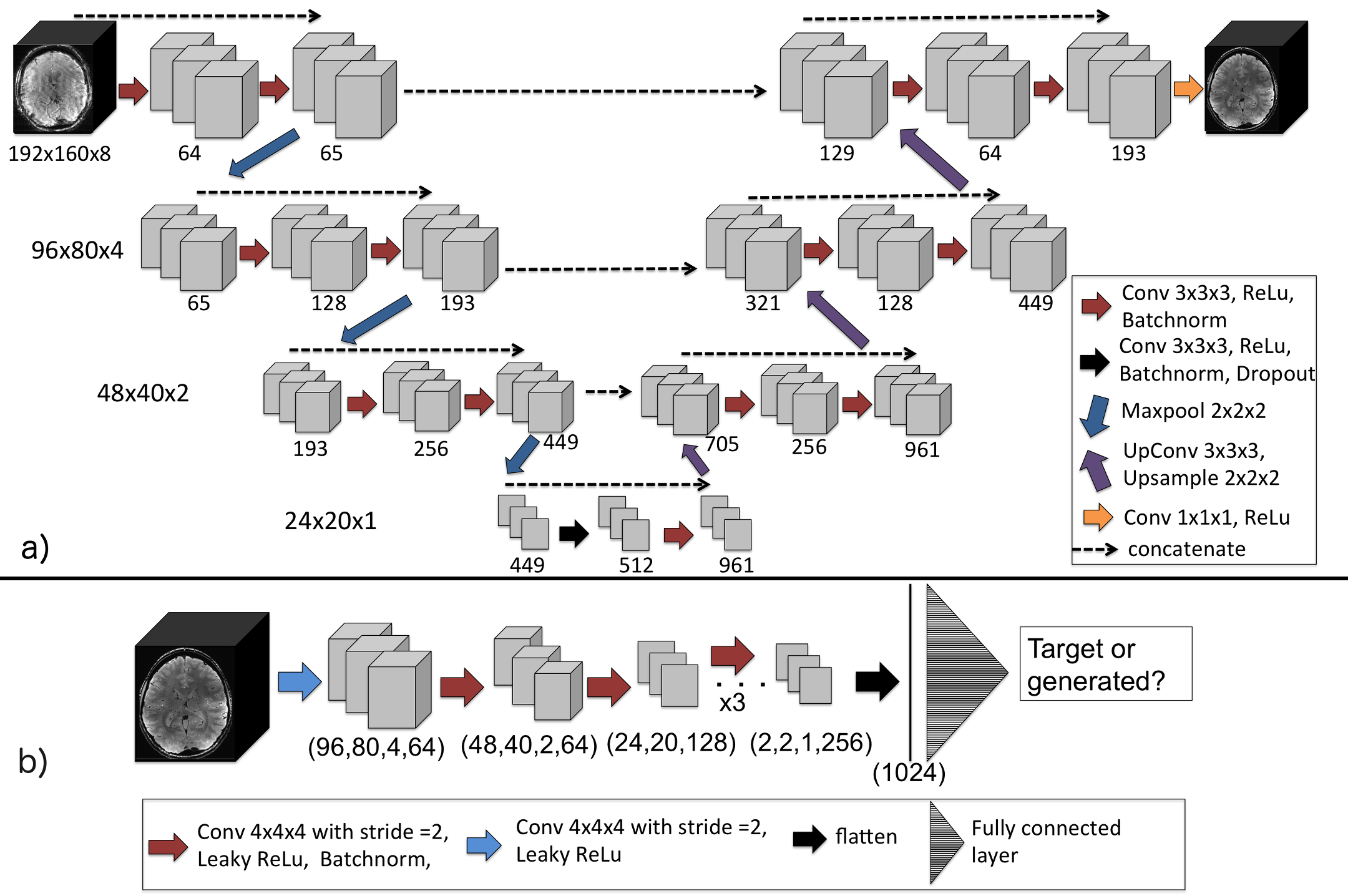
Network architecture and training: The 3D MoCo-cGAN network architecture (Figure 1), includes a generator (3D encoder-decoder) and a discriminator (DCNN classifier). The generator and discriminator were trained simultaneously; mean absolute error (MAE) and binary cross-entropy loss functions were used as described by Isola et al. (7). The Adam optimizer was used with a batch size of 8. The network was trained for 40 epochs (approximately 18hrs).
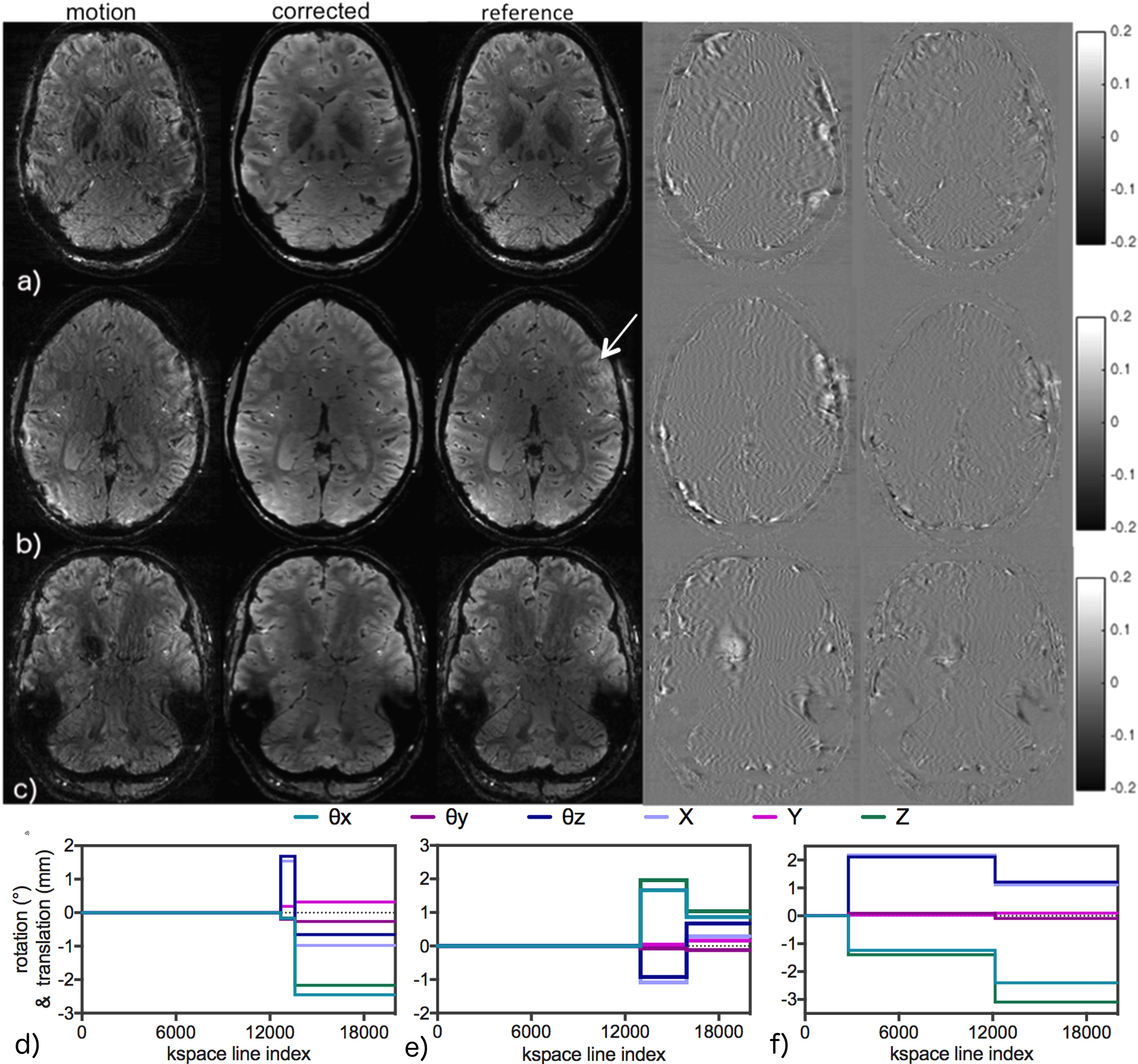
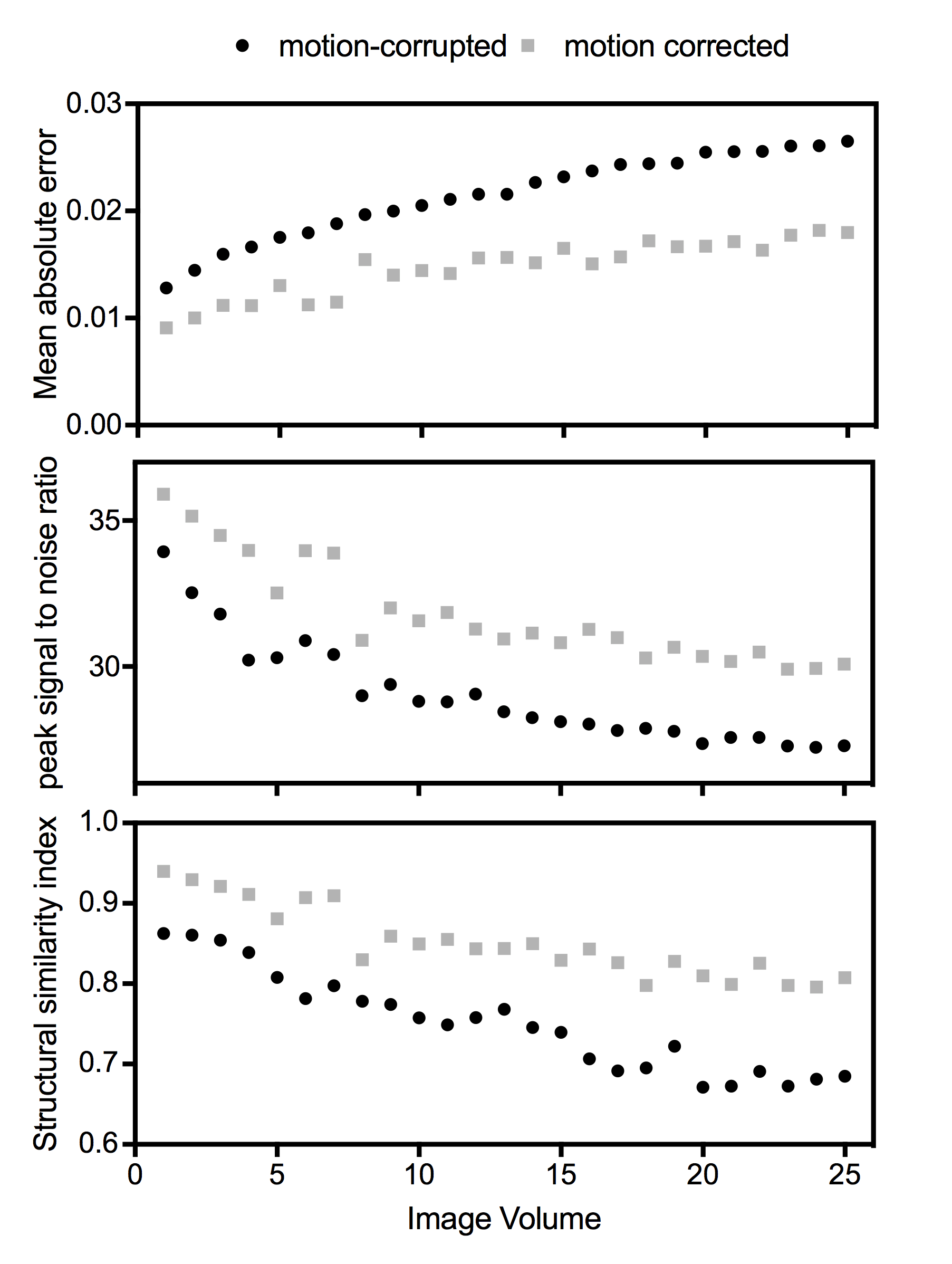
Evaluation of network performance: The network was evaluated on 5 subjects reserved for the test set. Difference images were calculated by subtracting the motion-corrupted and corrected images from the corresponding target image. Motion-corrupted and corrected volumes were compared to the target image using MAE, peak SNR (PSNR), and structural similarity index (SSIM).
Evaluation of transfer learning: In order to demonstrate the transfer learning potential of MoCo-cGAN to images with different contrast and SNR, the network was fine-tuned with 8 first echo motion-corrupted images from the training patient data. The network was trained for 10 epochs (approximately 20mins) and evaluated on echo 1 images from the same 5 subjects as the previous experiment. Again, difference images and image quality metrics were calculated to evaluate the performance of the network.
Results
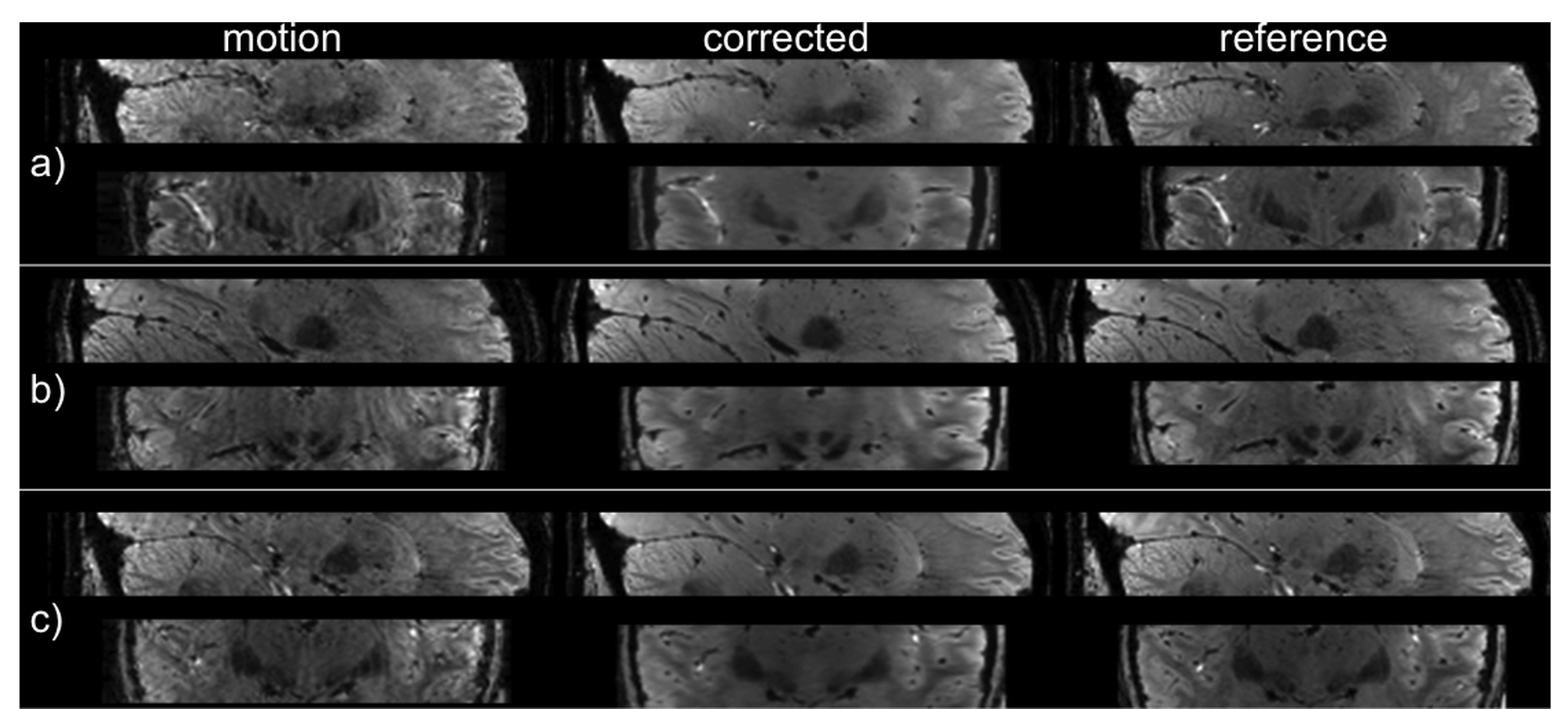
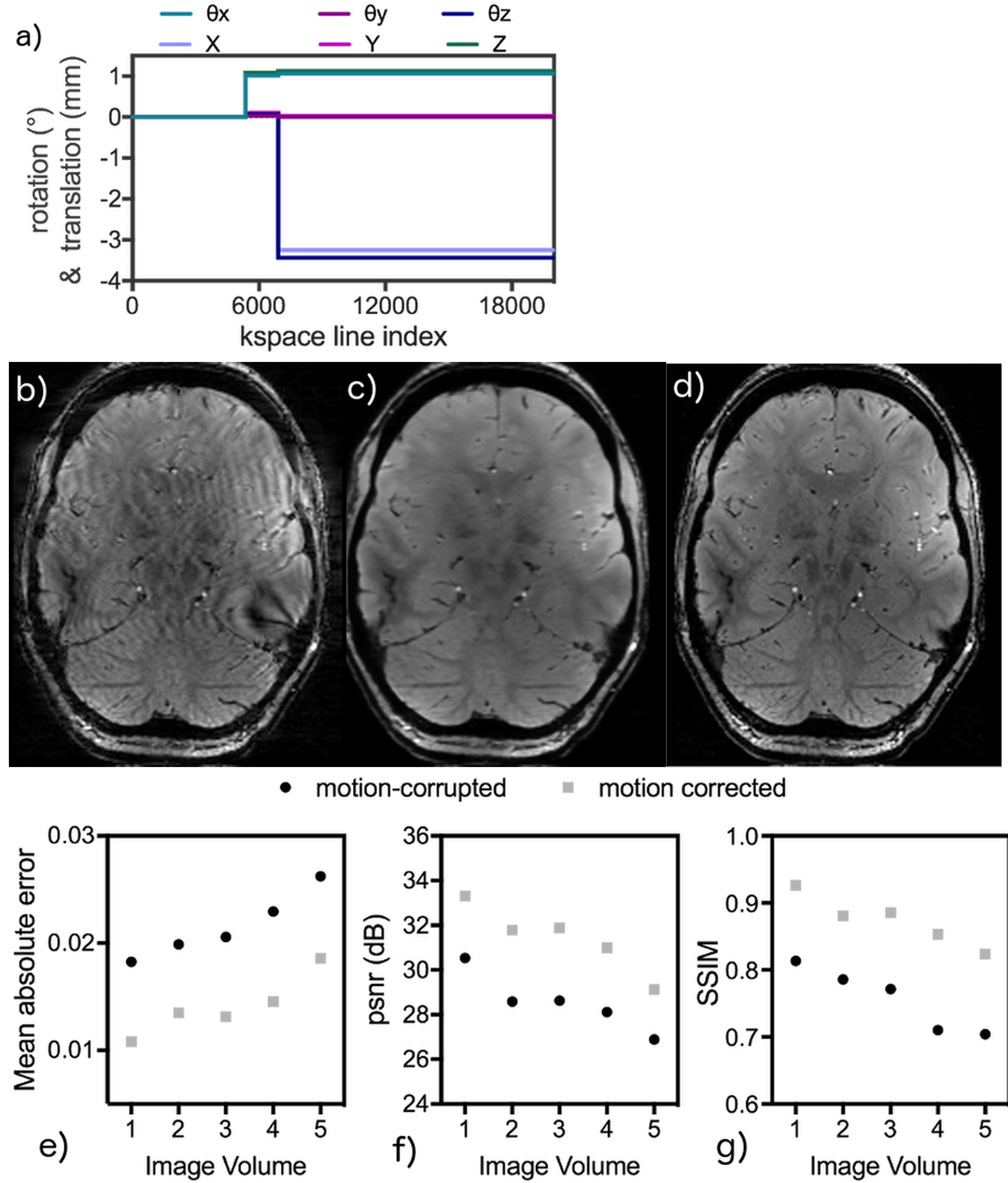
The trained MoCO-cGAN successfully improved image quality for all of the motion-corrupted test-set volumes. Representative correction results for three subjects, along with the corresponding motion profiles, are shown in Figure 2. Using the trained MoCO-cGAN resulted in significant artefact suppression and reduced blurring, which is further demonstrated in sagittal and coronal images of the same subjects, shown in Figure 3. Quantitatively, all motion-corrected images are improved compared to the original motion-corrupted images. For all 25 image volumes in the test set, MoCO-cGAN correction resulted in a decreased MAE and an increased SSIM and PSNR (Figure 4). The MoCo-cGAN network, fine-tuned for echo 1 images, also achieved qualitative and quantitative image improvement of the motion-corrupted volumes. Representative correction results for one of the five volumes, along with the corresponding motion profile and the full set of quantitative results are shown in Figure 5.Discussion/Conclusions
The trained MoCo-cGAN successfully performed motion correction on brain images with simulated motion. All predicted images are quantitatively improved, with an over 30% decrease in MAE. Transfer learning was also successful; after fine-tuning the network with only 8 images, MoCo-cGAN was able to correct images with different contrast and SNR than the images with which it was originally trained. This suggests that MoCo-cGAN could be a practical and versatile tool, requiring only a small number of training pairs to be fine-tuned for different protocols. MoCo-cGAN also demonstrates impressive artefact suppression, however, the predicted images still appear over-smoothed. Investigating strategies to enforce sharpness, for example an activity regularizer and/or different cost function options, is the focus of ongoing work. Insights gained from the development of this network are expected to be transferable to datasets with real motion. The trained MoCo-cGAN could potentially serve as a pre-trained network needing only fine-tuning to correct for real motion.Acknowledgements
This research was funded by NSERC and enabled by support and computing resources provided by WestGrid (www.westgrid.ca) and Compute Canada Calcul Canada (www.computecanada.ca).
References
(1) Forstmann BU, Keuken MC, Schafer A, Bazin P-L, Alkemade A, Turner R. Multi-modal ultra-high resolution structural 7-Tesla MRI data repository. Scientific Data 2014;1:140050.Figures