4668
Deep MRI Reconstruction without Ground Truth for Training1Biomedical Engineering, State University of New York at Buffalo, Buffalo, NY, United States, 2Electrical Engineering, State University of New York at Buffalo, Buffalo, NY, United States, 3Program of Advanced Musculoskeletal Imaging (PAMI), Cleveland Clinic, Cleveland, OH, United States
Synopsis
Deep learning has recently been applied to image reconstruction from undersampled k-space data with success. Most existing works require both undersampled data and ground truth image as the training pair. It is not practical to obtain a large number of ground truth images for training in some MR applications. Here a novel deep learning network is studied for image reconstruction using only undersampled data for training. Experiment results demonstrate the feasibility of training without the ground truth images for image reconstruction.
Introduction
Deep learning has recently demonstrated tremendous success in computer vision [1-2]. Inspired by that success, several studies have applied deep learning to MRI reconstruction from undersampled k-space data [3-10]. These studies use different neural networks to learn the relationship between the undersampled data and the ground truth image using a large amount of training data. However, in some applications, it is very difficult to obtain a large number of ground truth images for training, such as in dynamic imaging and diffusion imaging. In this study, we investigate a novel deep learning network [9] for MRI reconstruction from undersampled data. The training of such a network does not require the ground truth images but only the aliased images from undersampled data. The method is evaluated using the data from the Osteoarthritis Initiative [11].Methods
In the existing deep learning reconstruction methods [3-10], the objective is to learn the relationship between the aliased image from undersampled k-space data (input) $$$\widehat{x}_{i}$$$ and the ground truth image from fully sampled data (output) $$$y_{i}$$$ using a large number of training pairs $$$\left(\widehat{x}_{i},y_{i}\right)$$$ by minimizing the mean squared error (L2): $$$arg\min_{\theta}\frac{1}{n}\sum_\left(i=1\right)^n\parallel f\left(\hat{x}_{i},\theta\right)-y_{i}\parallel^{2}$$$ (1), where $$$f\left(\hat{x}_{i},\theta\right)$$$ is the mapping function with parameter $$$\theta$$$. In this study, we replace the ground truth image of the training pair by another aliased image from undersampled data but with a different random sampling mask (say mask $$$O_{i}$$$). According to the property of L2 minimization, when there are infinite number of training samples, the estimated $$$\theta$$$ will remain unchanged as long as the expectation of the other random sampling process for mask $$$O_{i}$$$ is equal to the fully sampled spectrum [12]. The new training process is advantageous in the applications (e.g., cardiac cine imaging) where the fully sampled data is difficult to acquire, but undersampled data of the same object can be acquired repeatedly with different undersampling masks. Mathematically, the new training process becomes $$$arg\min_{\theta}\frac{1}{n}\sum_\left(i=1\right)^n\parallel f\left(\hat{x}_{i},\theta\right)-\hat{y}_{i}\parallel^{2}$$$ (2), where $$$\hat{y}_{i}$$$ represents the other aliased image of $$$y_{i}$$$ but with the sampling mask different from that of $$$\hat{x}_{i}$$$. According to [12], to meet the requirement that the expectation of the random sampling process will cover the entire k-space, a “Russian roulette” process is employed. Specifically, each individual k-space location is sampled with a Bernoulli process with a probability of $$$p\left(k\right)=e^{-\gamma\mid k\mid}$$$, where k represents the k-space location and $$$\gamma$$$ controls the reduction factor. Such variable density sampling agrees with the conventional undersampling pattern for compressed sensing with denser sampling in the high SNR region of center k-space. In addition, the sampled k-space values are further weighted by the inverse of the probability for density compensation. Such additional procedure can ensure the expectation is the entire spectrum without favoring the central k-space locations. With the loss function in Eq. (2), the training and testing of network can be implemented on U-Net or ResNet network.
To evaluate the performance of the new method, some training data was selected from the Osteoarthritis Initiative (OAI) baseline visit (SAG IW TSE with fat suppression, TR/TE=3200/30ms, resolution 0.5mm * 0.36mm * 3mm, mixture of radiographic KL grades). Among these datasets, 2000 left knee images were used for training. An acceleration factor of 5 with “Russian roulette” undersampling was used to generate both the input and output for training and testing. The hardware specification was CPU i7-6700K (4 cores 8 threads @4.0GHz); Memory 48GB; GPU 1x NVIDIA GTX 1080Ti. The training process takes 6 hours and reconstruction process takes less than 1 second.
Results
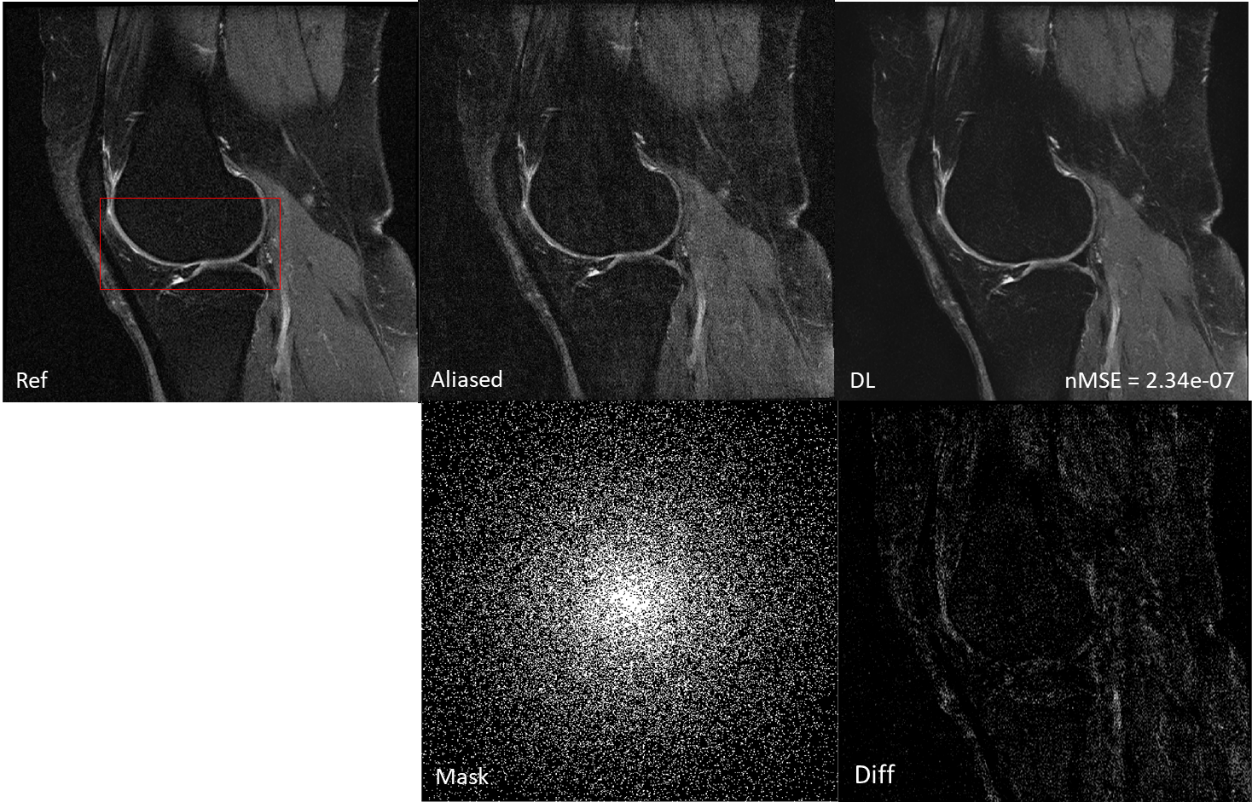
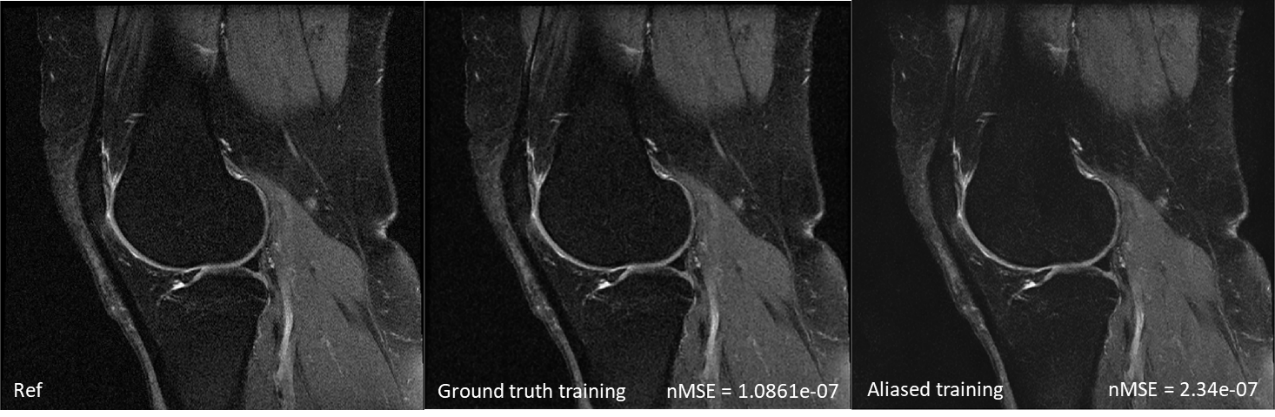
Figure 1 shows the reconstruction using only the aliased images for training and compares the reconstruction with the ground truth (labeled ROI) and the aliased image from undersampled data. The undersampling mask has a reduction factor of 5. The normalized mean squared error is shown on the bottom left corner of the reconstruction. Figure 2 shows the region of interest. The results demonstrate that it is sufficient to use only the undersampled k-space data for training the network and performing the reconstruction. The perceptual quality and the edge sharpness are very close to the fully sampled reference. Figure 3 also compares with the reconstruction using the ground truth images for training. Although the NMSE is slightly poorer, the image quality is seen to be identical for training with the aliasing or ground truth images.Conclusion
A new training process is studied in this abstract that uses only the aliased images from undersampled data as the training pairs. The experiment results demonstrate that the reconstruction quality is very close to that trained using the fully sampled ground truth images. Future work will investigate training of complex-valued MR images, optimization of the undersampling masks, and integration with other advanced network.Acknowledgements
This work is supported in part by the National Institute of Health R21EB020861.References
[1] O. Ronneberger, P. Fischer, and T. Brox, “U-net: Convolutional networks for biomedical image segmentation,” in International Conference on Medical Image Computing and Computer-Assisted Intervention. Springer, 2015, pp. 234–241.
[2] C. Dong, C. C. Loy, K. He and X. Tang, "Image Super-Resolution Using Deep Convolutional Networks," in IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 38, no. 2, pp. 295-307, 1 Feb. 2016.
[3] S. Wang, Z. Su, L. Ying, X. Peng, S. Zhu, F. Liang, D. Feng, D. Liang, “Accelerating magnetic resonance imaging via deep learning,” IEEE 14th International Symposium on Biomedical Imaging (ISBI), pp. 514-517, Apr. 2016.
[4] S. Wang, N. Huang, T. Zhao, Y. Yang, L. Ying, D. Liang, “1D Partial Fourier Parallel MR imaging with deep convolutional neural network,” Proceedings of International Society of Magnetic Resonance in Medicine Scientific Meeting, 2017.
[5] D. Lee, J. Yoo and J. C. Ye, “Deep residual learning for compressed sensing MRI,” IEEE 14th International Symposium on Biomedical Imaging (ISBI), Melbourne, VIC, pp. 15-18, Apr. 2017.
[6] Chang Min Hyun et al, “Deep learning for undersampled MRI reconstruction,” Phys. Med. Biol. 63 135007, 2018
[7] S. Wang, T. Zhao, N. Huang, S. Tan, Y. Liu, L. Ying, and D. Liang, “Feasibility of Multi-contrast MR imaging via deep learning,” Proceedings of International Society of Magnetic Resonance in Medicine Scientific Meeting, 2017
[8] Zhu, Bo, Jeremiah Z. Liu, Stephen F. Cauley, Bruce R. Rosen, and Matthew S. Rosen. "Image reconstruction by domain-transform manifold learning." Nature 555, no. 7697 (2018): 487.
[9] K. Hammernik, T. Klatzer, E. Kobler, M. P. Recht, D. K.Sodickson, T. Pock, and F. Knoll, “Learning a variational network for reconstruction of accelerated MRI data,”Magnetic Resonance in Medicine, vol. 79, no. 6, pp.3055–3071, 2018.
[10] K. H. Jin, M. T. McCann, E. Froustey and M. Unser, “Deep Convolutional Neural Network for Inverse Problems in Imaging,” in IEEE Transactions on Image Processing, vol. 26, no. 9, pp. 4509-4522, Sept. 2017.
[11] https://oai.epi-ucsf.org/datarelease/
[12] J. Lehtinen, J. Munkberg, J. Hasselgren, S. Laine, T. Karras, M. Aittala, T. Aila, “Noise2Noise: Learning Image Restoration without Clean Data,” Proceedings of the 35th International Conference on Machine Learning, PMLR 80:2965-2974, 2018.
Figures