4651
W-net: A Hybrid Compressed Sensing MR Reconstruction Model1Radiology and Clinical Neuroscience, Hotchkiss Brain Institute, University of Calgary, Calgary, AB, Canada, 2Seaman Family MR Centre, Foothills Medical Centre, Calgary, AB, Canada
Synopsis
Compressed sensing (CS) magnetic resonance (MR) imaging acquisitions reduce MR exam times by decreasing the amount of data acquired during acquisition, while still reconstructing high quality images. Deep learning methods have the advantage of reconstructing images in a single step as opposed to iterative (and slower) CS methods. Our proposal aims to leverage information from both k-space and image domains, in contrast to most other deep-learning methods that only use image domain information. We compare our W-net model against four recently published deep-learning-based methods. We achieved second best results in the quantitative analysis, but with more visually pleasing reconstructions.
Purpose
Propose a hybrid W-net deep learning model that leverages both k-space and image domain information, which can potentially reduce magnetic resonance (MR) imaging examination times.Introduction
Compressed sensing (CS) magnetic resonance (MR) imaging acquisitions reduce MR exam times by decreasing the amount of data acquired during acquisition, while still reconstructing high quality images. Deep learning methods have the advantage of reconstructing images in a single step as opposed to iterative (and slower) CS methods. Our proposal aims to leverage information from both k-space and image domains, in contrast to most other deep-learning methods that only use image domain information. We compare our W-net model against four recently published deep-learning-based methods.Methods
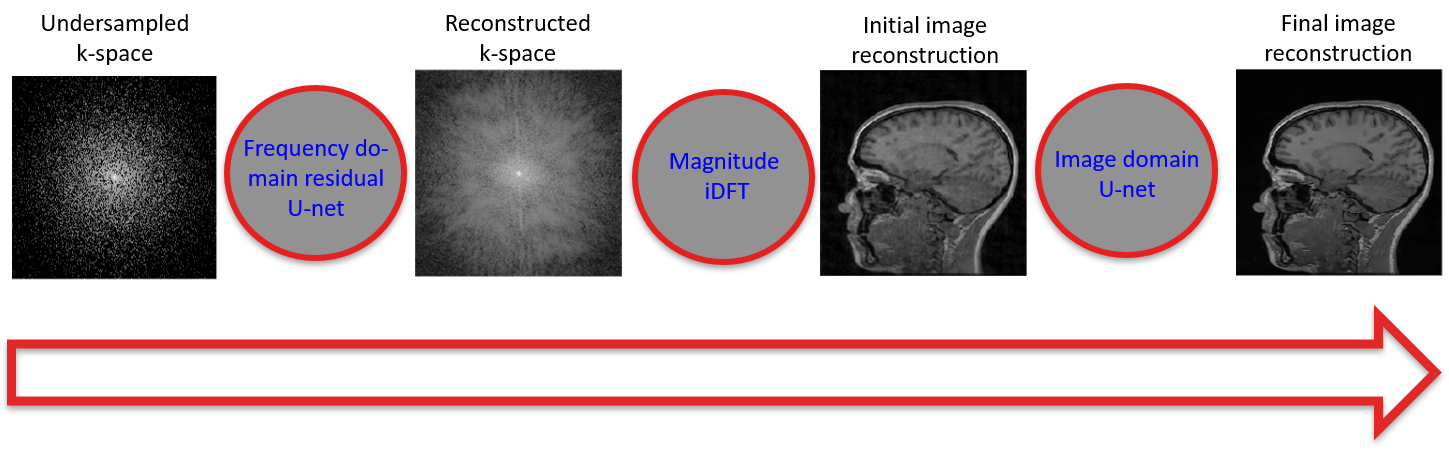
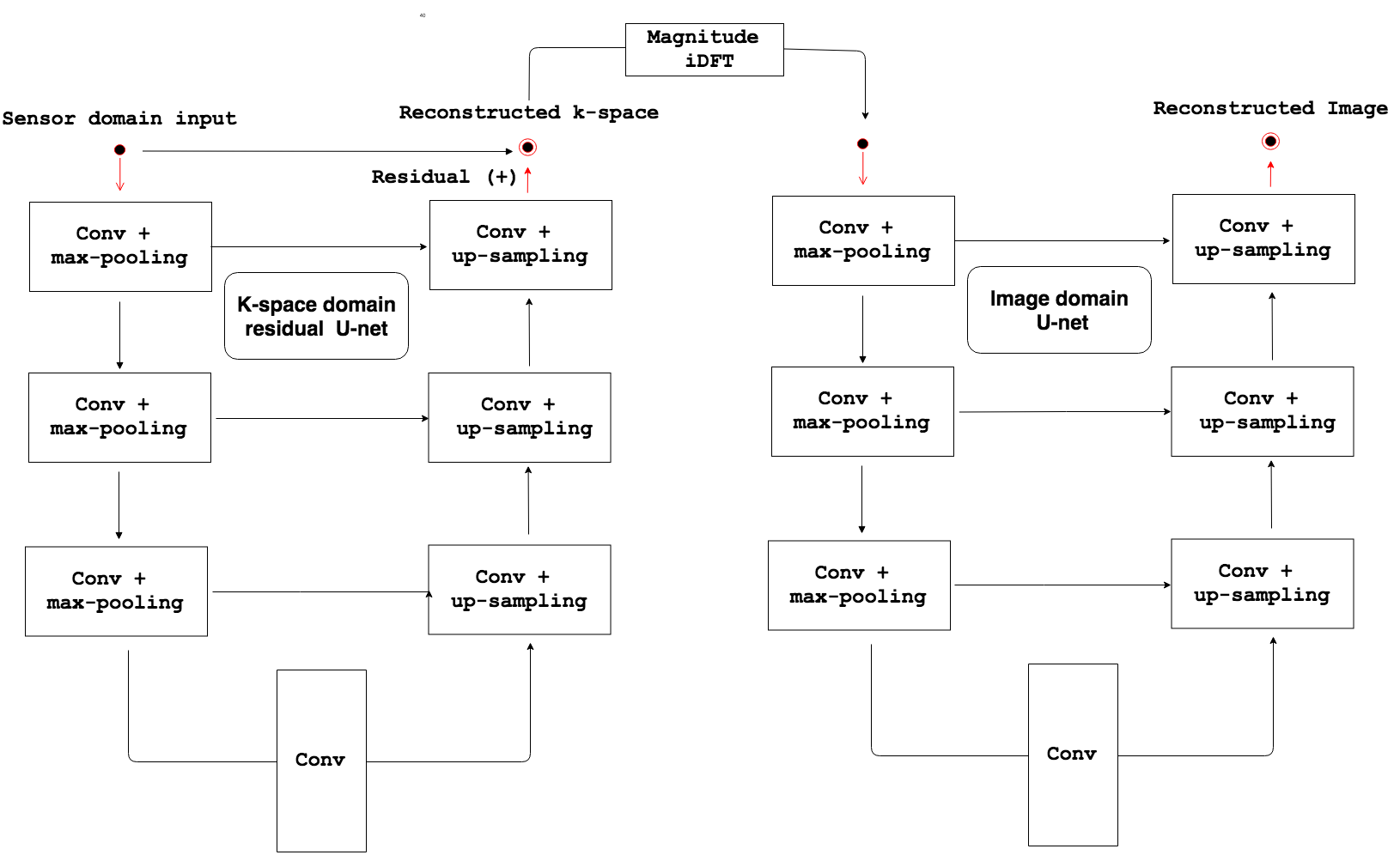
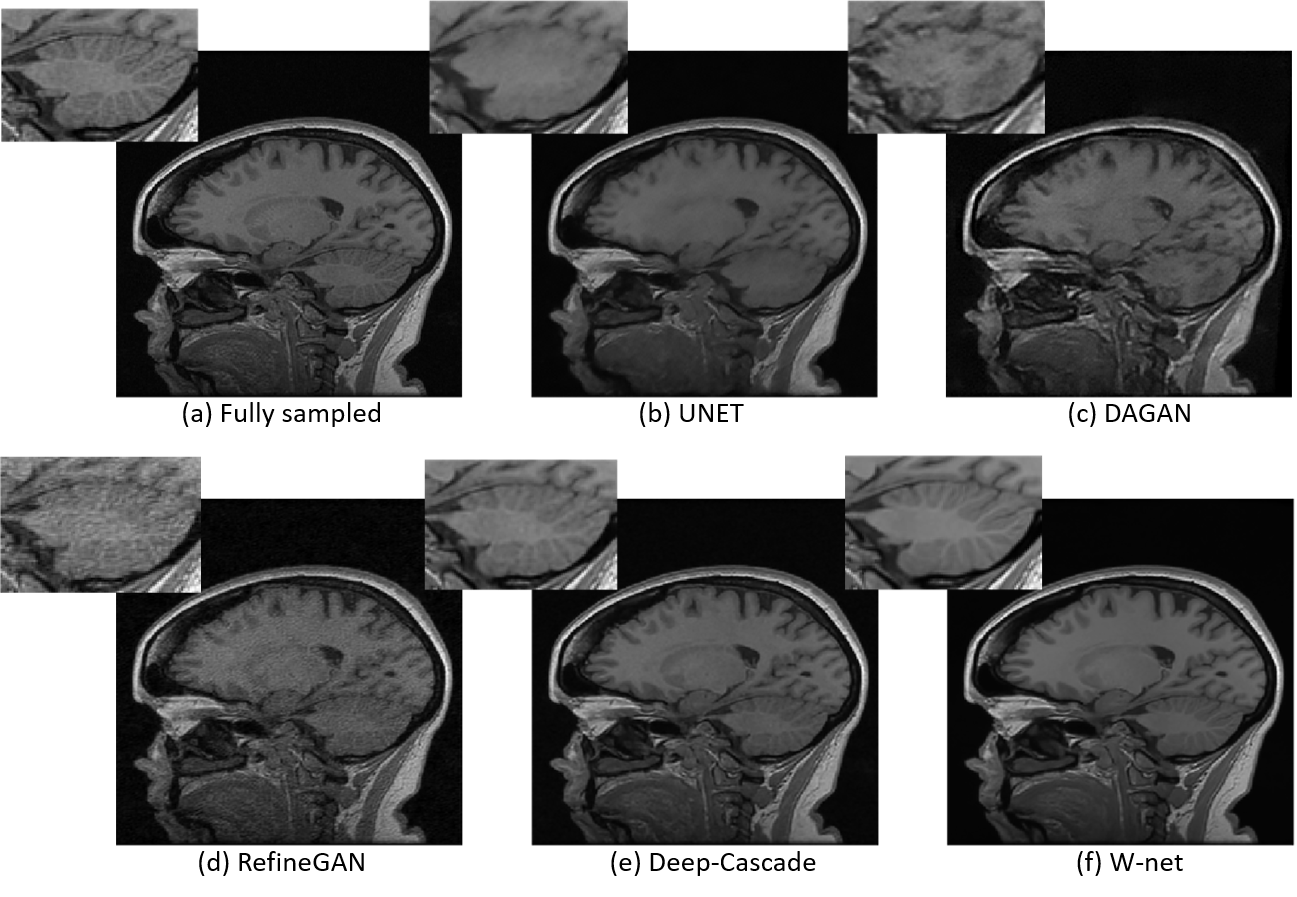
We propose a hybrid compressed sensing MR reconstruction framework that first receives an undersampled k-space as input and processes it using a frequency domain residual U-net1 where real and imaginary values are split into two image channels. The magnitude of the inverse Discrete Fourier Transform (iDFT) is applied to the output of the first U-net and fed as input to an image domain U-net, which generates a reconstructed image (Figure 1). The concatenation of two U-nets resembles a “W”, which leads to the naming of our model as the W-net (Figure 2). The hypothesized advantage of our approach is leveraging of information in both the k-space and image domains. Most other deep learning-based reconstruction techniques use only image domain information, by using the zero-filled reconstructed images as a starting point. One exception is AUTOMAP2, which learns the “optimal iDFT” given under-sampled k-space data. Although an interesting approach, for 256x256 images, AUTOMAP model has more than 1010 parameters that need to be learned, making it infeasible to be trained using currently available hardware. For identically sized images, the number of parameters of our W-net is on the order of 107, i.e. 1000× less parameters compared to AUTOMAP. We compared our W-net method against 1) a plain vanilla U-net1 with a residual connection, referred to as UNET; 2) RefineGAN;3 3) DAGAN;4 and 4) Deep-Cascade.5 We use structural similarity (SSIM)6, normalized root mean squared error (NRMSE) and peak signal-to-noise ratio (PSNR) as quantitative evaluation metrics. A qualitative evaluation of images was also conducted. Analysis of variance (ANOVA) and paired t-tests were used to determine statistically significant pair-wise differences. Statistical significance was conservatively set at p<0.01. We tested a 5x acceleration (i.e., collection of only 20% of data) in the experiments. All networks were trained from scratch using the same datasets. The test set has 10 volumes, which correspond to 1,700 slices.Results and Discussion
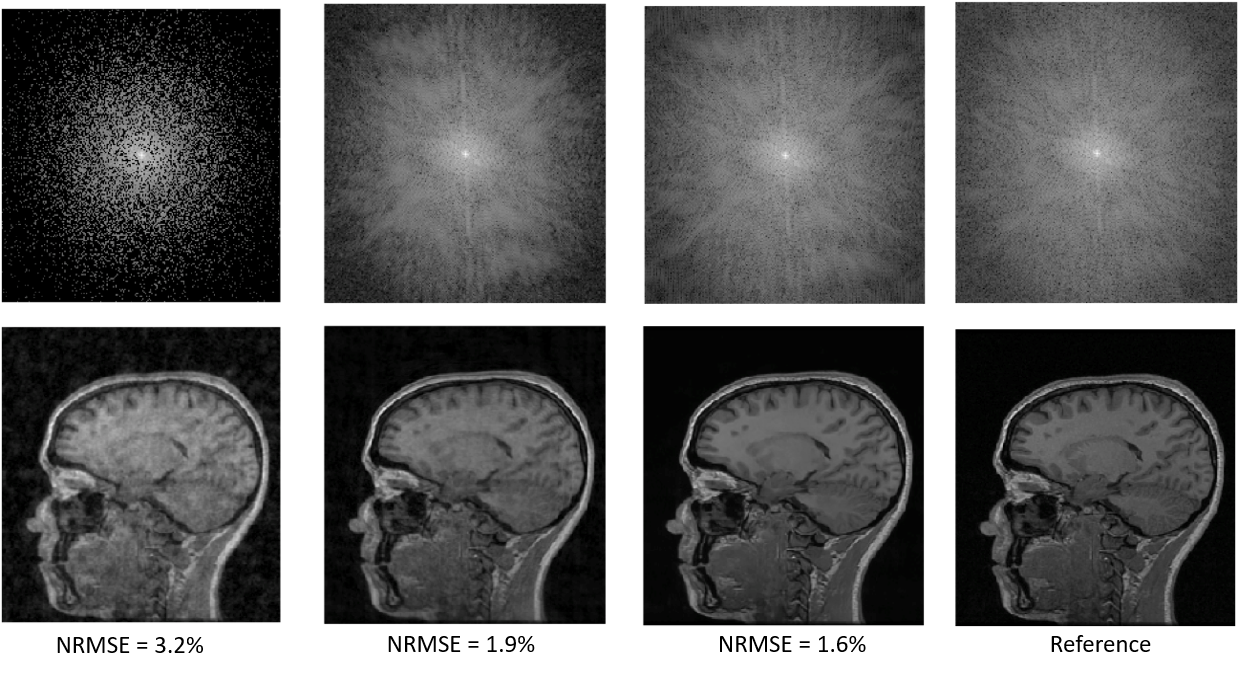
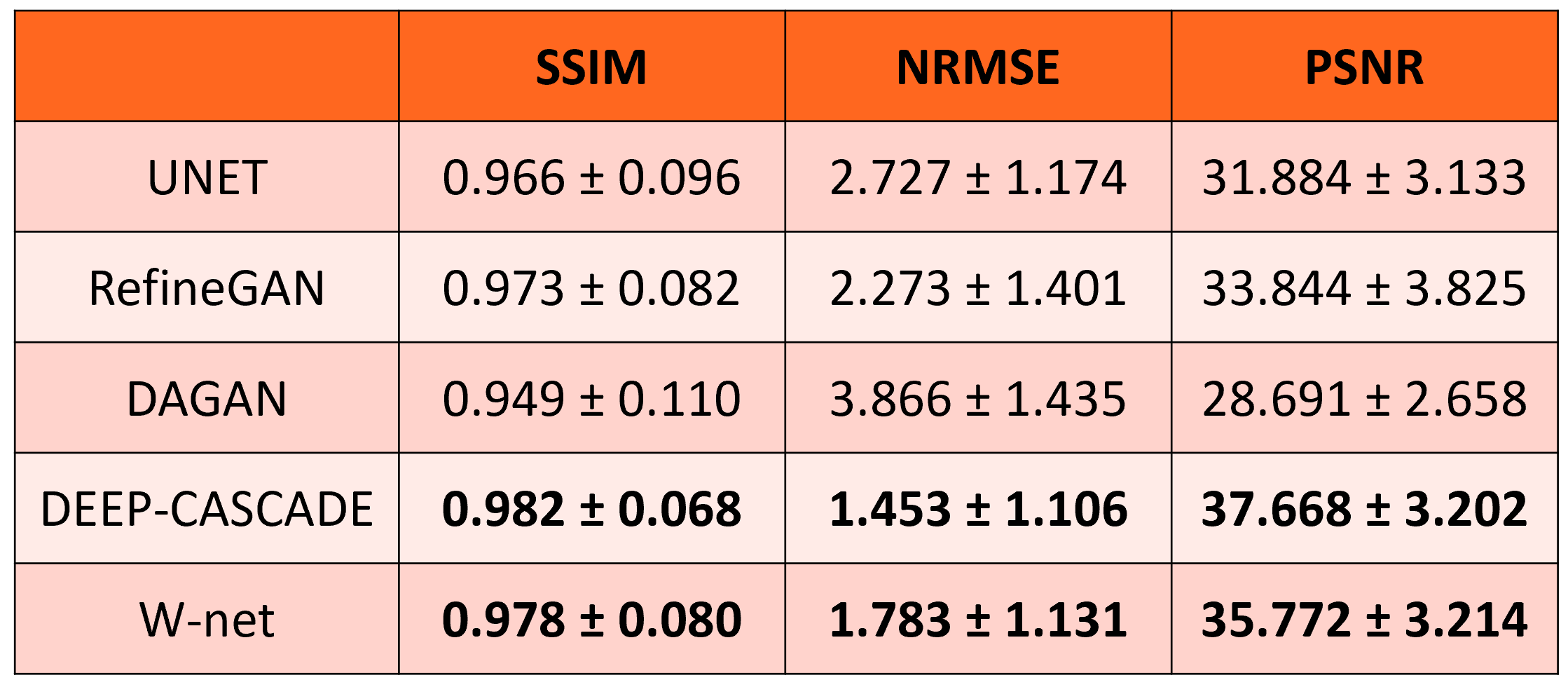
A sample reconstruction using our approach is depicted in Figure 3. The NRMSE of the zero-filled reconstruction was 3.2%, after the k-space U-net it decreased to 1.9%, then after the image domain U-net to 1.6%. The input k-space was heavily under-sampled, especially at the higher spatial frequencies, which likely explains why the k-space U-net did well at reconstructing the mid-to-low frequencies of k-space, due to the receptive field of the network, i.e. how much of its neighbourhood it sees. The image domain U-net did at better job recovering higher spatial frequencies, likely due to the global nature of the iDFT that connects the two U-nets, confirming that neighbouring pixels in image domain contain information about all frequencies in k-space. The global evaluation metrics are summarized in Figure 4. Deep-Cascade was statistically better (p<0.01) than the other methods in the comparison. W-net, while worse than Deep-Cascade, was statistically better than UNET, DAGAN, and RefineGAN (p < 0.01). We also note that the absolute differences between Deep-Cascade and Hybrid networks, while statistically significant, were small. It is important to highlight that Deep-Cascade concatenates five convolutional neural networks to achieve these results, i.e. it is a more complex model. Qualitative analysis indicated that the W-net produced the most pleasing image, particularly in regions with large signal differences like the cerebellum (Figure 5).Conclusions
We presented a W-net MR imaging reconstruction model. We performed second best in the overall quantitative comparison, but generated more visually pleasing images specially in regions harder to reconstruct. Our next steps are to optimize the network architecture, and potentially incorporate data consistency layers, which have shown potential to improve reconstruction.5 Other challenges remain, such as adapting the proposal to parallel imaging approaches.Acknowledgements
The authors would like to thank the Natural Science and Engineering Council of Canada (NSERC) for operating support, and Amazon Web Services for access to cloud-based GPU services. We would also like to thank Dr. Louis Lauzon for setting up the script to save the raw MR data at the Seaman Family MR Centre. R.S. was supported by an NSERC CREATE I3T Award and currently holds the T. Chen Fong Scholarship in Medical Imaging from the University of Calgary. R.F. holds the Hopewell Professor of Brain Imaging at the University of Calgary.References
1Ronneberger et al., “U-net: Convolutional networks for biomedical image segmentation,” MICCAI 2015, pp. 234-241;
2Zhu et al., “Image reconstruction by domain-transform manifold learning,” Nature 2018, pp. 487-;
3 Quan et al., “Compressed sensing MRI reconstruction using a generative adversarial network with a cyclic loss,” IEEE Tran Med Imaging, 2018, pp. 1488-1497;
4Yang et al., “DAGAN: Deep de-aliasing generative adversarial networks for fast compressed sensing MRI reconstruction,” IEEE Tran Med Imaging, 2018, pp. 1310-1321;
5Schlemper et al., “A deep cascade of convolutional neural networks for dynamic MR image reconstruction,” IEEE Tran Med Imaging, 2018, pp. 491-503;
6Wang et al., “Image quality assessment: from error visibility to structural similarity,” IEEE Tran Image Processing, 2004, pp. 600-612.
Figures