4650
Deep learning aided compressed sensing for accelerated cardiac cine MRI1Department of Diagnostic and Interventional Radiology, University Hospital Würzburg, Würzburg, Germany
Synopsis
A reconstruction technique for accelerated functional cardiac MRI is presented that exploits a convolutional neural network trained for semantic segmentation of undersampled data. The idea is inspired by the experience that the human eye is capable of distinguishing between typical undersampling artifacts and cardiac shape and/or motion, even for high acceleration factors. The temporal courses of the segmentations determined by the network are used for an efficient sparsification within a compressed sensing algorithm.
Purpose
In this work, we introduce a compressed sensing technique for
accelerated cine MRI that exploits an artificial neural network
for an efficient sparsification of undersampled temporal image series of the
beating heart.Methods
Deep Learning
A fully convolutional network with a similar architecture as the VGG-16 network presented in [1] was implemented in MATLAB (The Mathworks, Natick, MA, USA) and trained to automatically perform semantic segmentation of both sub-Nyquist and fully sampled cardiac cine MR images. While VGG-16 was implemented and trained for image recognition, the second part of the developed network is represented by a decoder pattern and a final pixel classification-layer, equivalent to SegNet [2]. A dataset consisting of 100.248 cardiac cine MR images with corresponding labels for left and right ventricle as well as for myocardial tissue was prepared from the public Kaggle second annual data-science-bowl-database [3]. Labels were obtained by automatically segmenting all images using the method presented in [4], which has proven equal accuracy as human experts. In each of the 20 epochs of the training stage, the training images were retrospectively undersampled with a radial trajectory and a random undersampling factor R $$$\in$$$ [1.0, 2.1, 3.4, 5.5, 8.9].
Compressed Sensing Algorithm
The trained network was then used within an iterative reconstruction of undersampled cine MR data, which exhibits similarities to MOCCO [5]. The proposed algorithm yields a fully sampled cine series $$$x$$$ (two spatial and one temporal domain $$$t$$$), and will be referred to as DL-cine (deep learning aided cine):
$$ \min_{x}\left\{ || N(x) - x ||_1 + \alpha ||E(x) - y||_2^2 \right\} $$
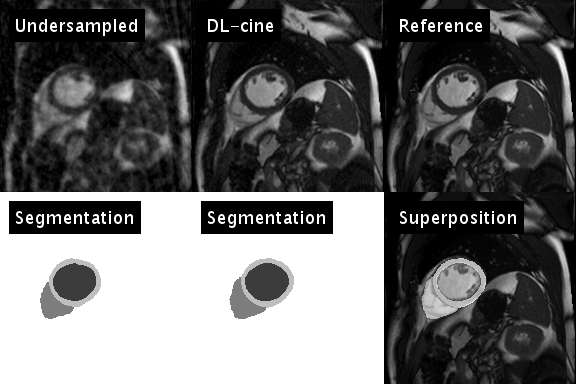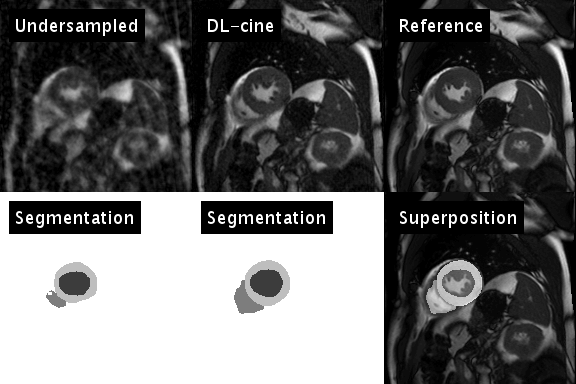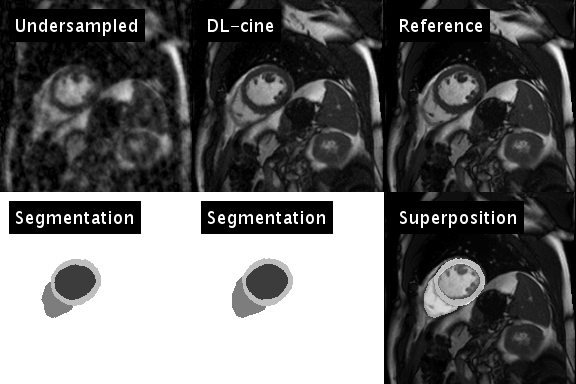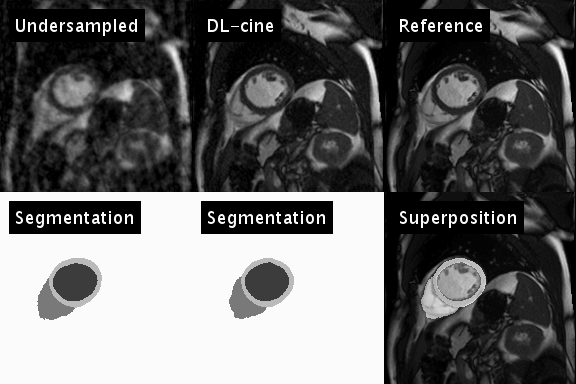
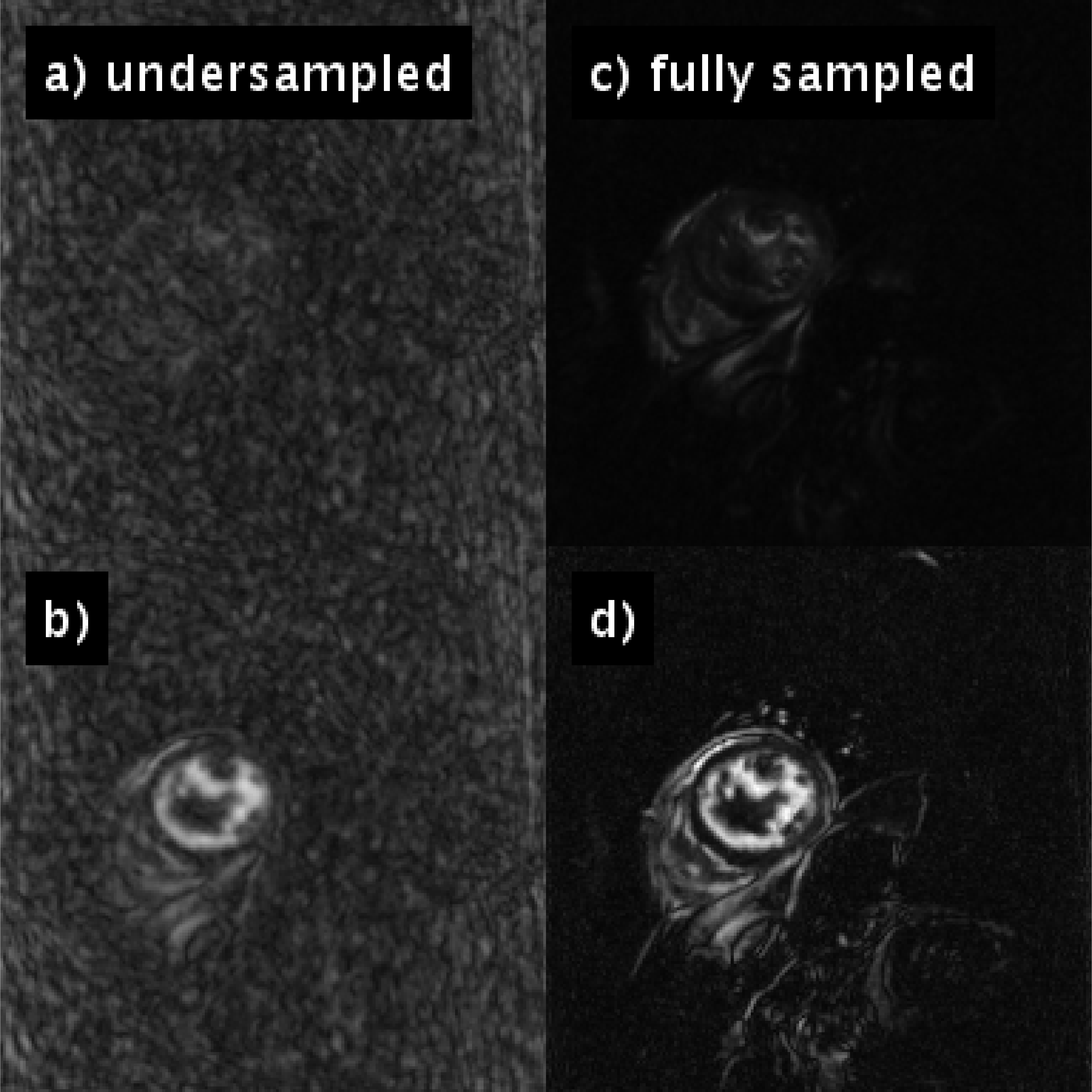
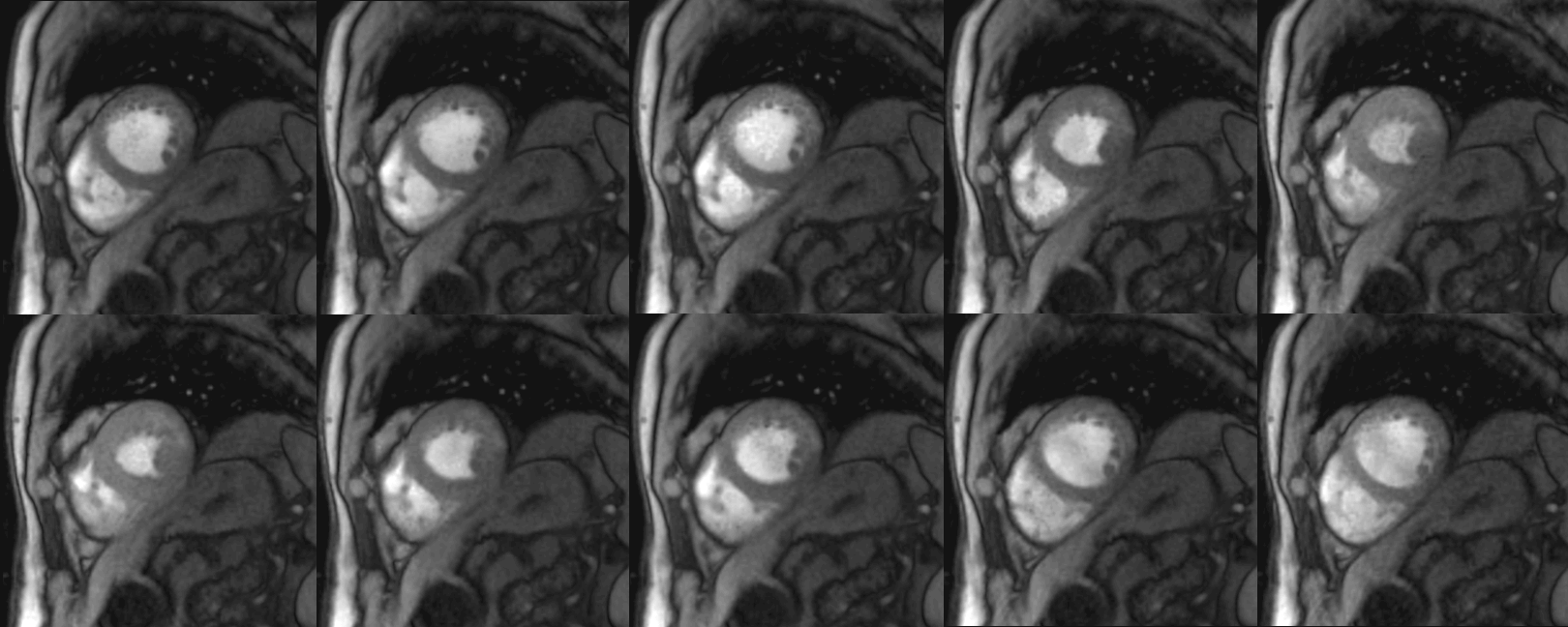
$$$y$$$ represents the sampled $$$k$$$-$$$t$$$-space data and $$$E$$$ the encoding operator. In each iteration, the trained neural network is applied to the current estimate of $$$x$$$, to determine an updated temporal image series of segmentations $$$s$$$ (see animation in Fig. 1, bottom left). $$$s$$$ is subsequently used to efficiently sparsify $$$x$$$: $$$N$$$ projects temporal waveforms of $$$x$$$ (i.e. the temporal course of an individual pixel) on a $$$K$$$-dimensional subspace spanned by the $$$K$$$ largest temporal principal components of $$$s$$$. It is thus expected, that $$$N(x)$$$ preserves the physical motion of the heart, and efficiently suppresses artifacts caused by the temporally varying undersampling pattern (see Fig. 2). $$$\alpha$$$ and $$$K$$$ were chosen empirically in this stage of the development.
Validation
DL-cine was applied to 4272 test series (not part of
the training dataset), which were retrospectively undersampled using 34
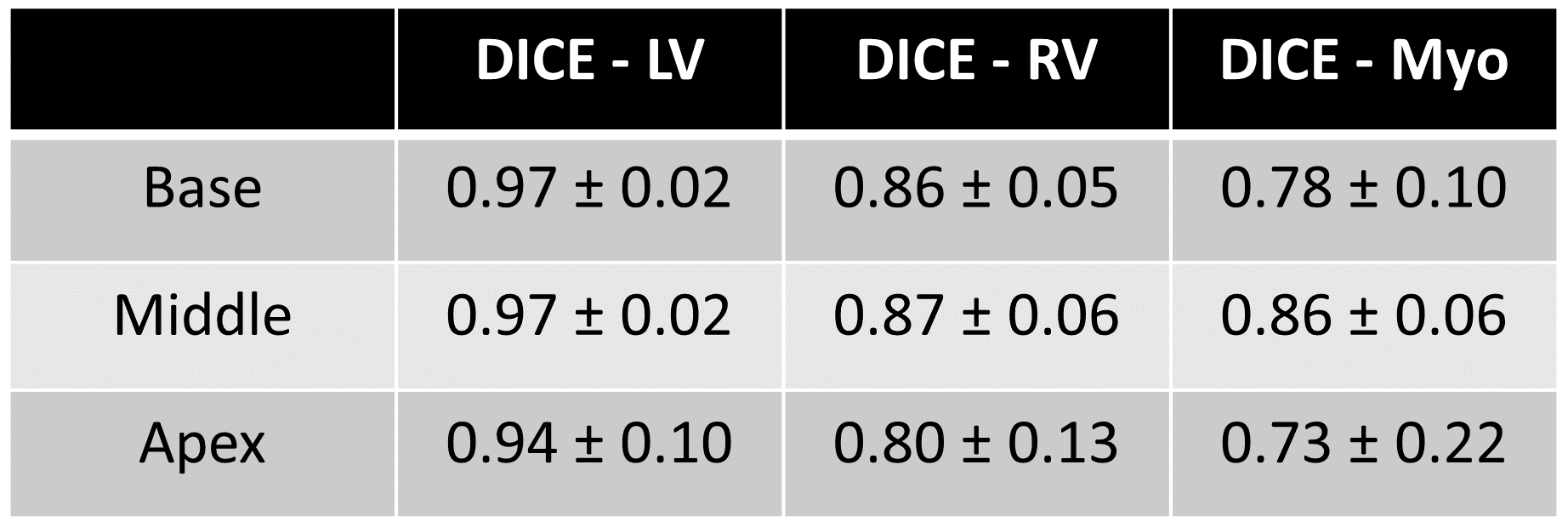
projections per timeframe (pattern varying in time). DICE scores were calculated to compare the segmentations
resulting from DL-cine with segmentations determined in the fully sampled test
series by the same network trained with fully sampled training data only. For one exemplary patient, the undersampled
datasets were prepared for both 34 and 55 projections per timeframe and were
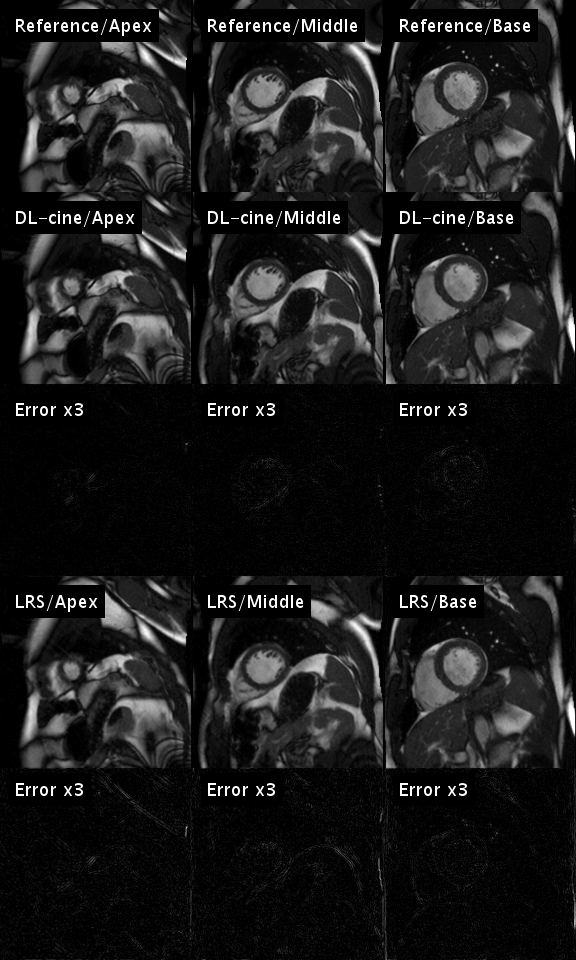
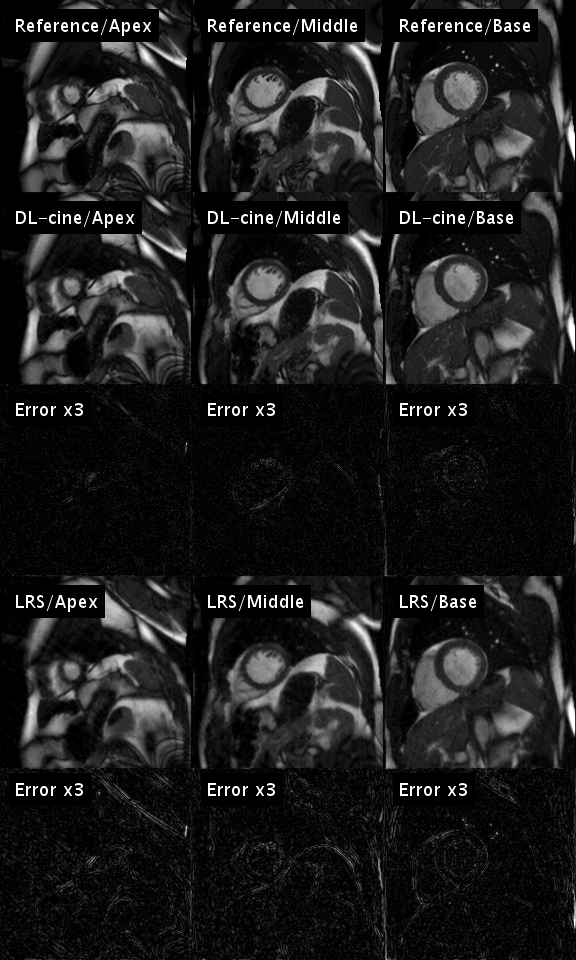
then subjected to DL-cine and to the low-rank plus sparse method (LRS)
presented in [6].
DL-cine was further exemplarily applied to an
undersampled in-vivo cine acquisition in a volunteer suffering from left-ventricular
myocardial infarction (mid-ventricular slice, TR = 3.3 ms, TE= 1.5 ms, in-plane
resolution = 1.7 mm, slice thickness = 8 mm, flip angle =12°, ~34
projections per frame, self-gating using central point of each projection).
Results
Figure 1 illustrates the artificial neural network’s ability to emulate the intuitive human skill of discriminating between artifacts and anatomical contours (left). Both the cine series and the segmentation were successfully optimized using DL-cine (Fig. 1, middle). When using 55 projections per timeframe, DL-cine shows a slightly reduced error compared to LRS (Fig. 3). The difference is more pronounced when using 34 projections only (Fig. 4). DICE-scores were high for the left ventricle and for all segmentations in the mid-ventricular sector (see Tab. 1). Towards base and apex, Dice scores were lower, especially for myocardial tissue. The prospectively undersampled in-vivo example reconstructed by DL-cine (Fig. 5) resulted in overall good image quality. The “ejection fraction”, exemplarily determined for this slice (EFslice = 0.50) corresponded well to the value determined manually for the same slice within the clinical cine examination (bSSFP, EFslice = 0.51).Discussion & Conclusion
The AI-driven technique DL-cine provides excellent reconstructions of undersampled cardiac examinations, and intrinsically delivers a complementary fully automated segmentation. Despite high acceleration factors with only 34 projections per timeframe, results showed only slight differences with respect to a fully sampled reference. The accuracy of the segmentations for RV and myocardium at peripheral positions (apex, base) could be improved by including more training data, as the appearance of the heart is certainly much more heterogeneous for images in these regions.Acknowledgements
The authors sincerely thank
Ricardo Otazo,
PhD
and Dr. Wenjia Bai for making reconstruction code publically available, as well as kaggle for providing a large pool of well-structured cardiac cine datasets.
References
[1] Simonyan et al., CoRR preprint arXiv:1409.1556 [2] Badrinarayanan et al., CoRR preprint arXiv:1511.00561v3 [3] Kaggle. Data Science Bowl Cardiac Challenge Data. https://www.kaggle.com/c/second-annual-data-science-bowl/data. [4] Bai et al., JCMR 20:65 (2018) [5] Velikina et al., MRM 74:1279-1290 (2015) [6] Otazo et al., MRM 73:1125-1136 (2015)
Figures