4569
Relaxation parameter estimation from limited time points1Department of Electronic Engineering, The Chinese University of Hong Kong, Shatin, Hong Kong, 2Department of Imaging and Interventional Radiology, The Chinese University of Hong Kong, Shatin, Hong Kong
Synopsis
T1rho is a useful biomarker for the diagnosis of several diseases. Current imaging techniques usually use uniform sampling and require a relatively large number of samples to get reliable estimations of T1rho. We show that the intuitive uniform sampling is not optimal, and propose an optimal sampling strategy. We also propose a fast estimation algorithm, which (with the use of spatial redundancy) provides accurate estimates of the T1rho relaxation map from as few as 3 different spin-lock time samples.
Introduction
One central task in different modalities of magnetic resonance imaging is to estimate the relaxation time of the MRI signal. For instance, this signal behaves like $$$ae^{-T_{SL}/T_{1,\rho}}+c$$$ in the $$$T_{1,\rho}$$$ modality, where TSL is the spin-lock time. The scan time increases proportionally with the increased number of TSLs (1) and the choice of TSL affects the quantification accuracy (2,3,4,5).
We demonstrate that the intuitive uniform TSL sampling is not optimal: the optimal sampling actually relies on 3 main TSL sampling times (with possible repetitions). Here we propose a method that is able to accurately estimate $$$T_{1,\rho}$$$ from 3 time samples, the minimum number of samples required. The accuracy of the method relies on the optimal sampling strategy and the use of spatial redundancy to mitigate the problems caused by the lack of samples.
Methods
Estimating $$$T_{1,\rho}$$$ amounts to fitting the pairs of measurements $$$(t_n,y_n)$$$ to the model $$$y=ae^{bt}+c$$$, where $$$b=-1/{T_{1,\rho}}$$$ and $$$t$$$ is the spin-lock time. This is done by minimising the mean squared error (MSE), i.e., $$\min_{a,b,c} \frac1N\sum_{n=1}^N\left(y_n-ae^{bt_n}-c\right)^2,$$ where $$$N$$$ is the number of samples. Once the optimal $$$a^*,b^*$$$ and $$$c^*$$$ are found, the maximum likelihood estimation of $$$T_{1,\rho}$$$ is given by $$$\hat T_{1,\rho}=-1/b^*$$$. The above minimisation problem is solved by first minimising the MSE over the two linear parameters $$$a$$$ and $$$c$$$ (solving a linear system of 2 equations), and thus expressing the MSE as a function of a single parameter $$$b$$$, then minimising over $$$b$$$ numerically using a dichotomic algorithm, which provides an excellent estimate of $$$b^*$$$ within just a few iterations (typically less than 10 iterations). The algorithm is fast and typically takes a few seconds to estimate the $$$T_{1,\rho}$$$ values over a whole sequence of eight 256 by 256 images. This comes from the fact that the dichotomic algorithm does not rely on the magnitude of the gradient, contrary to standard gradient descent algorithms, which undergo slow update when the MSE changes slowly in function of $$$b$$$. Besides, in the presence of noise, this maximum likelihood estimate is very accurate in the sense that its variance reaches the theoretical lower bound, the Cramer-Rao bound.
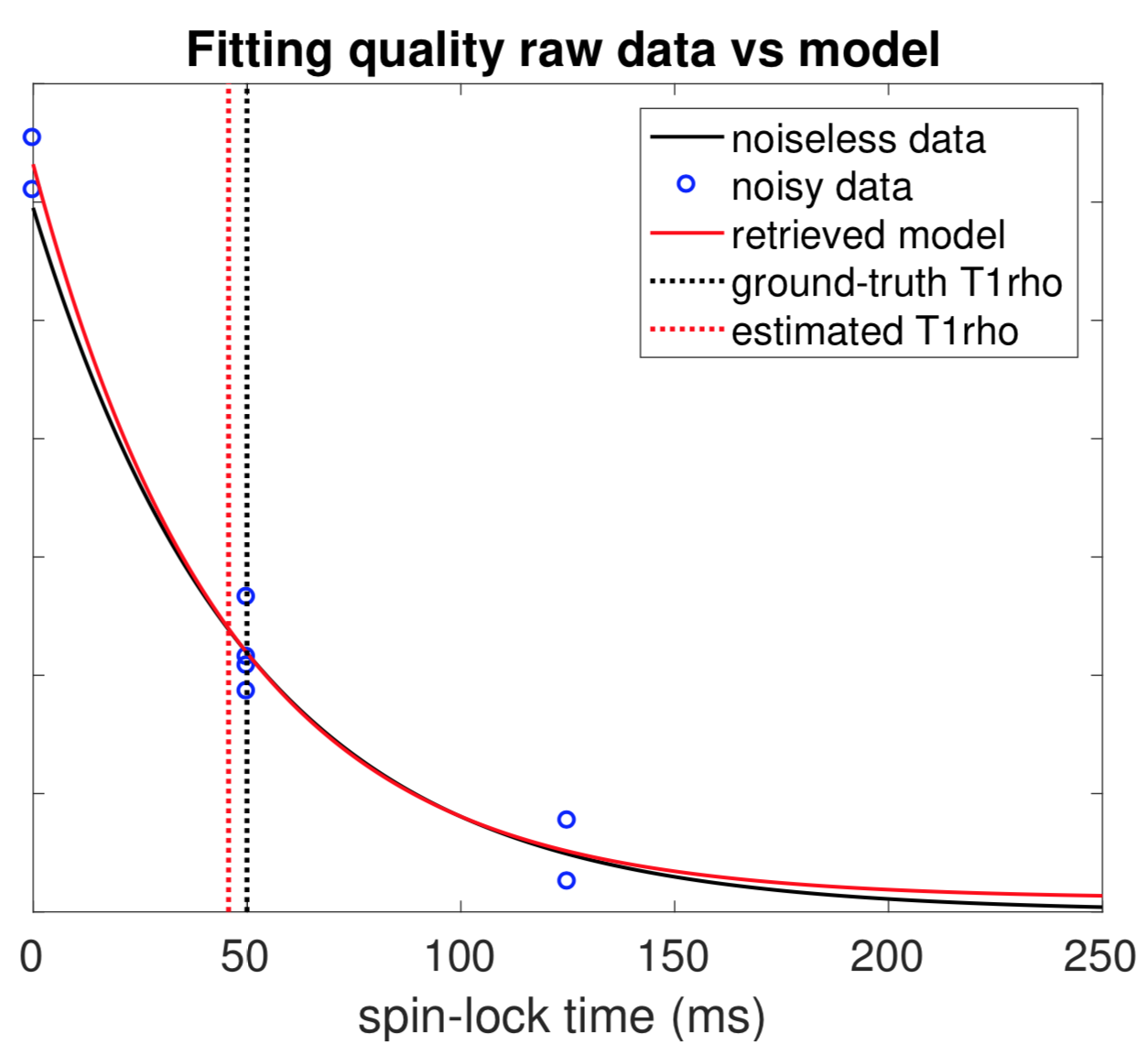
We show that the intuitive uniform sampling is not optimal and the estimation error, $$$E[(\hat T_{1,\rho}-T_{1,\rho})^2]$$$, is minimal when all the samples are concentrated at 3 time instances. Typically, in an $$$N$$$-sample setting, the optimal sampling consists of $$$N/4$$$ samples at the beginning ($$$t=0$$$), $$$N/2$$$ samples at the expected $$$T_{1,\rho}$$$ value and the other $$$N/4$$$ samples at a value of $$$t$$$ that is as large as possible. Figure 1 shows the optimal sampling strategy for the $$$N=8$$$ case. In practice, we roughly know the range of $$$T_{1,\rho}$$$ of the target tissue. Hence we take the 3 samples at 0, the middle point of the range and the maximum TSL available, respectively.
Moreover, since $$$T_{1,\rho}$$$ varies slowly in most regions of the image, we exploit this spatial redundancy to virtually increase the number of samples. We assume that the measurements taken in a neighbourhood of a pixel should be similar to that of the central pixel. Therefore, we treat these measurements as extra samples for the $$$T_{1,\rho}$$$ estimation of the central pixel. By using the neighbours and measurements taken at only 3 different TSLs, the proposed method provides a more accurate $$$T_{1,\rho}$$$ estimation than that of using 8 uniform samples.
Results and Discussion
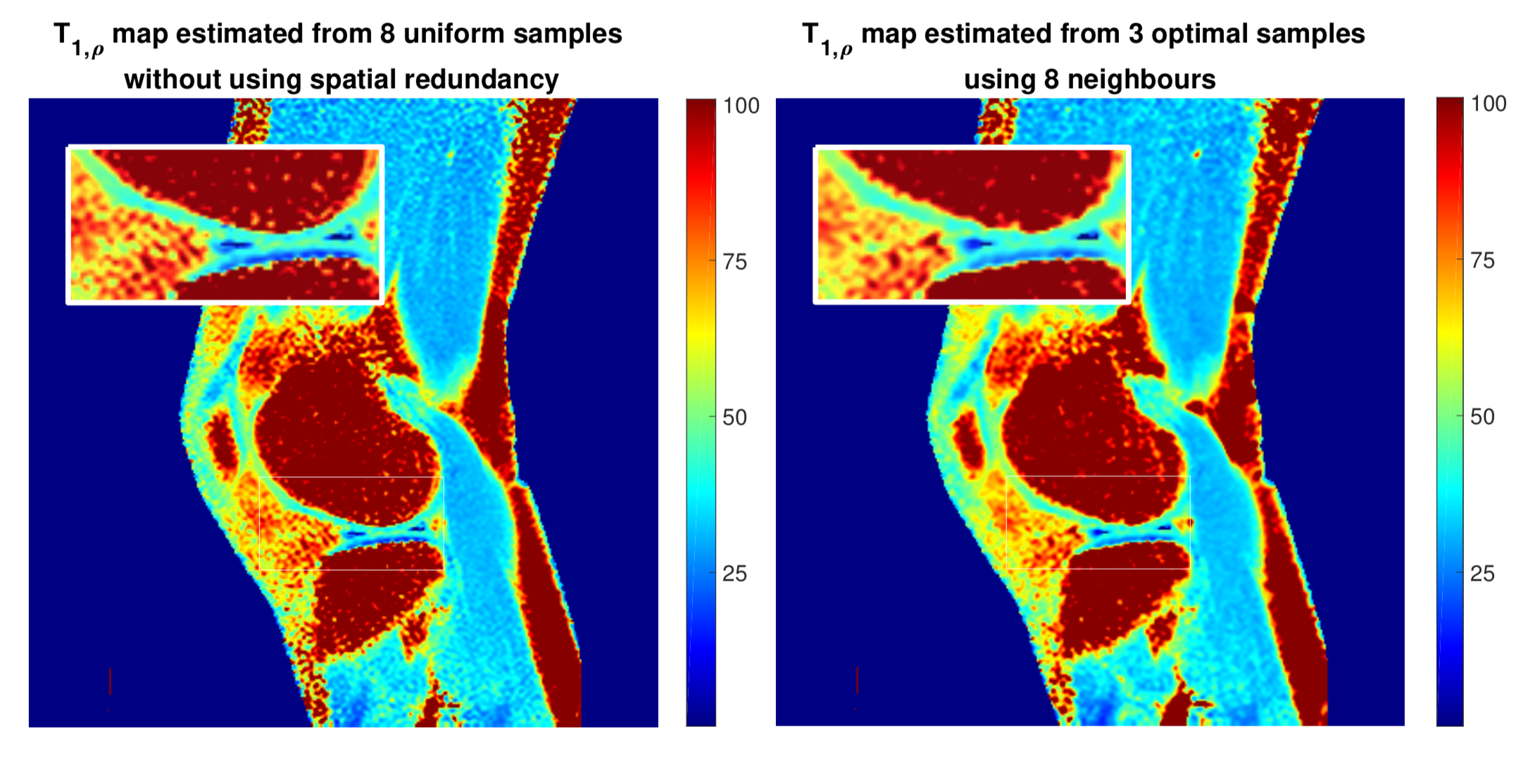
We first evaluated the proposed algorithm on synthetic data. As shown in Figure 2, by using extra measurements from 8 neighbouring pixels, the proposed method produces a more accurate estimation using the optimal 3-sample strategy, when compared with the estimation from 8 uniform time samples (but without exploiting spatial redundancy). In principle, using more neighbours results in more accurate estimations in smooth regions of the $$$T_{1,\rho}$$$ image at the cost of a slight spatial resolution loss at boundary regions. We evaluated the proposed method on in vivo $$$T_{1,\rho}$$$ acquisition. Figure 3 shows the estimated $$$T_{1,\rho}$$$ map of the knee using 8 (roughly) uniform samples (left) and that of using 3 samples with 8 neighbours (right). The results show that the estimation provided by the proposed method from 3 samples is very competitive in quality, while being significantly less demanding for the patients.Conclusion
In this work, we show that the intuitive uniform sampling strategy is not optimal for the estimation of the relaxation time in MRI problems. We propose an optimal sampling strategy and an efficient optimisation algorithm, able to accurately estimate the $$$T_{1,\rho}$$$ value from limited samples taken at 3 instances of spin-lock time. Experiments demonstrate the accuracy of the proposed method.Acknowledgements
This study is supported by a grant from the Innovation and Technology Commission of the government of Hong Kong SAR (Project ITS/051/17).References
- Weitian Chen, Queenie Chan, and Yi-Xiang J. Wang, "Breath-hold black blood quantitative T1ρ imaging of liver using single shot fast spin echo acquisition," Quantitative Imaging in Medecine and Surgery, vol. 6, no. 2, pp. 168, 2016.
- Casey P. Johnson, Daniel R. Thedens, and Vincent A. Magnotta, "Precision-guided sampling schedules for efficient T1ρ mapping," Journal of Magnetic Resonance Imaging, vol. 41, no. 1, pp. 242-250, 2015.
- R. I. Shrager, G. H. Weiss, and R. G. S. Spencer, "Optimal time spacings for T2 measurements: monoexponential and biexponential systems," NMR in Biomedicine, vol. 11, no. 6, pp. 297-305, 1998.
- Jose G. Raya, Olaf Dietrich, Annie Horng, Jurgen Weber, Maximilian F. Reiser, and Christian Glaser, "T2 measurement in articular cartilage: Impact of the fitting method on accuracy and precision at low SNR," Magnetic Resonance in Medecine, vol. 63, no. 1, pp. 181-193, 2010.
- Jean-Pierre Cercueil, Jean-Michel Petit, Stephanie Nougaret, Philippe Soyer, Audrey Fohlen, Marie-Ange Pierredon-Foulongne, Valentina Schembri, Elisabeth Delhom, Sabine Schmidt, Alban Denys, Serge Aho, and Boris Guiu, "Intravoxel incoherent motion diffusion-weighted imaging in the liver: comparison of mono-, bi- and tri-exponential modelling at 3.0-T," European Radiology, vol. 25, no. 6, pp. 1541-1550, 2015.
Figures