3858
Automatic Identification of ICA Components using A Generative Adversarial Network1Center for Neuroscience and Regenerative Medicine, Bethesda, MD, United States, 2Laboratory of Functional and Molecular Imaging, NINDS, Bethesda, MD, United States, 3Radiology and Imaging Sciences, NIH, Bethesda, MD, United States
Synopsis
Manual classification of the components derived from ICA analysis of rsfMRI data as particular functional brain resting state networks (RSNs) can be labor intensive and requires expertise; hence, a fully automatic algorithm that can reliably classify these RSNs is desirable. In this paper, we introduce a generative adversarial network (GAN) based method for performing this task. The proposed method achieves over 93% classification accuracy and out-performs the traditional convolutional neural network (CNN) and template matching methods.
Introduction
Examining the human brain as an integrative network of functionally interacting brain regions can provide new insights about large-scale neuronal communication in the human brain. Independent component analysis (ICA) is a popular technique for simultaneously extracting a variety of coherent RSNs without a priori information. However, ICA does not provide any classification or ordering of its components, and manual classification of ICAs as true RSNs (together with rejection of ICAs that do not match known RSNs) can be difficult. Therefore, a fully automatic algorithm that can reliably detect various types of functional brain networks is desirable. Generative adversarial networks (GANs1) have received attention due to its capability of generating visually realistic images and reducing the amount of training data required. GANs take advantage of adversarial processes to train two neural networks (including a generator and discriminator) that compete with each other until a desirable equilibrium is reached. The extension of GANs into semi-supervised learning has achieved state-of-the-art results on digit recognition, which makes use of large quantities of the additional generated data to increase their classification performance. In this work, we explored a semi-supervised GAN2 for the classification on ICA components by using a shared discriminator/classifier, which discriminates real data from fake while also predicting the class label. The advantage of this approach is that out-of-distribution examples – i.e. images that are significantly different from any example in the training data set - do not need to be explicitly labeled in order to train the network. We show that a GAN based proposed approach performs better than both template matching3,4 and traditional CNN approaches. The model can also synthesize realistic images that could potentially be further used as a source of data augmentation.Method
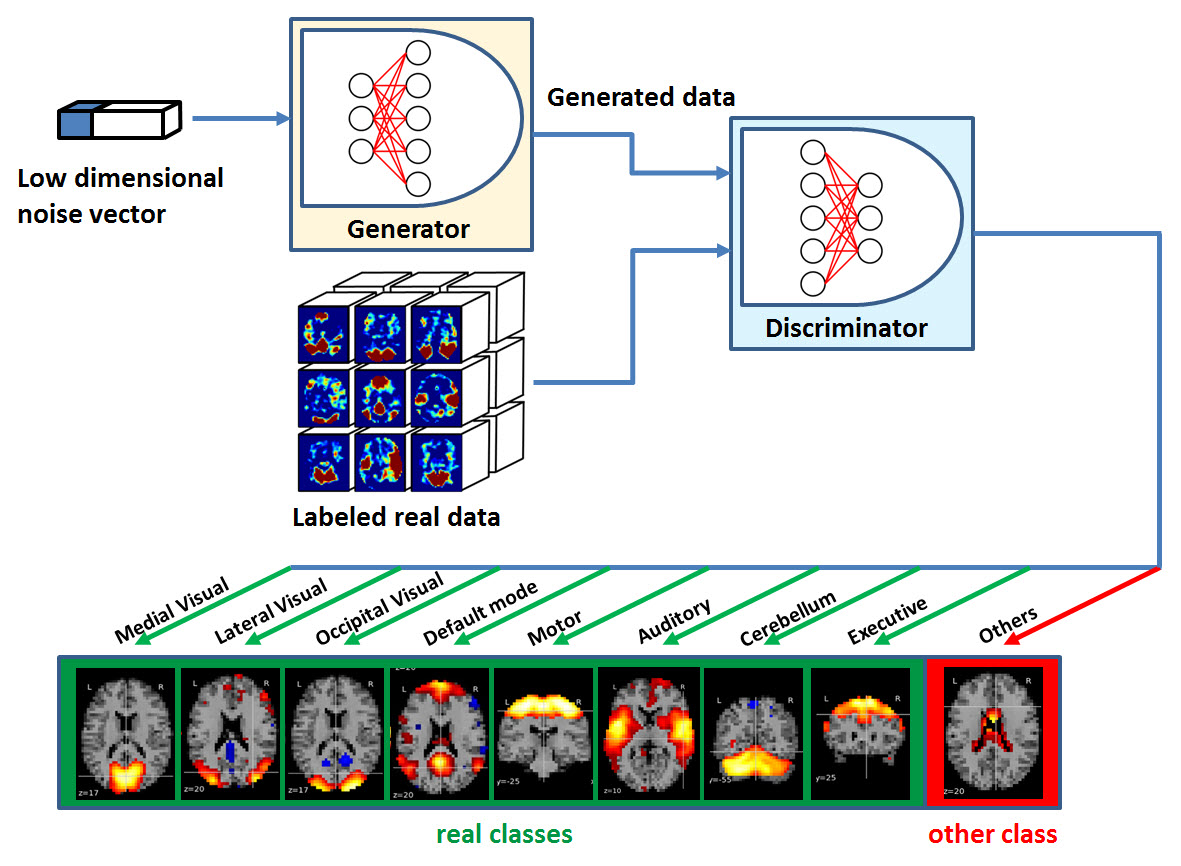
A total of rsfMRI datasets (7 min acquisition) and corresponding 3D T1-weighted volumes were pre-processed and decomposed into 30 components using MELODIC5 (FMRIB Software Library) to extract spatial maps of potential RSNs (scaled as a z-score). In each case, RSNs derived from ICA analysis were manually classified via visual inspection as one of the following eight RSNs: medial visual, occipital visual, lateral visual, default mode, cerebellum, motor, auditory and executive. The 147 datasets were separated into 3 groups, including training (60), testing (30) and evaluation (57) data sets. Training and testing data were manually labeled ICA components that were used for optimizing the GAN parameters and examining the accuracy of identifying the network of a single ICA component respectively. The evaluation data was used to examine the accuracy of extracting a specific network from all ICA components of a single subject. Unlike the standard GAN, here the discriminator is extended from a binary classifier (real vs generated data) to a multi-class classifier (Figure 1). After training, the generator was discarded because it was used only for training the discriminator. The discriminator then served as a multi-label classifier computing the probability that an ICA component represents on one of the eight RSNs or belongs to the “other” class, which can be represented as noise components or any RSN not under consideration.Results
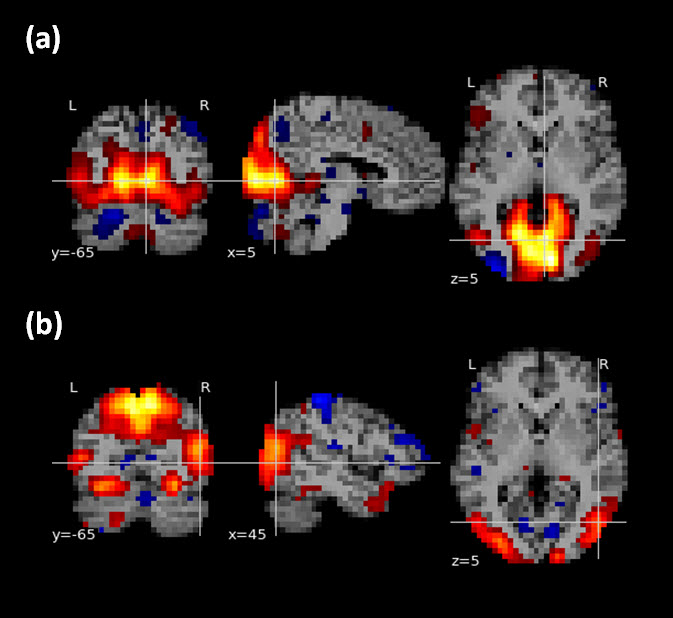
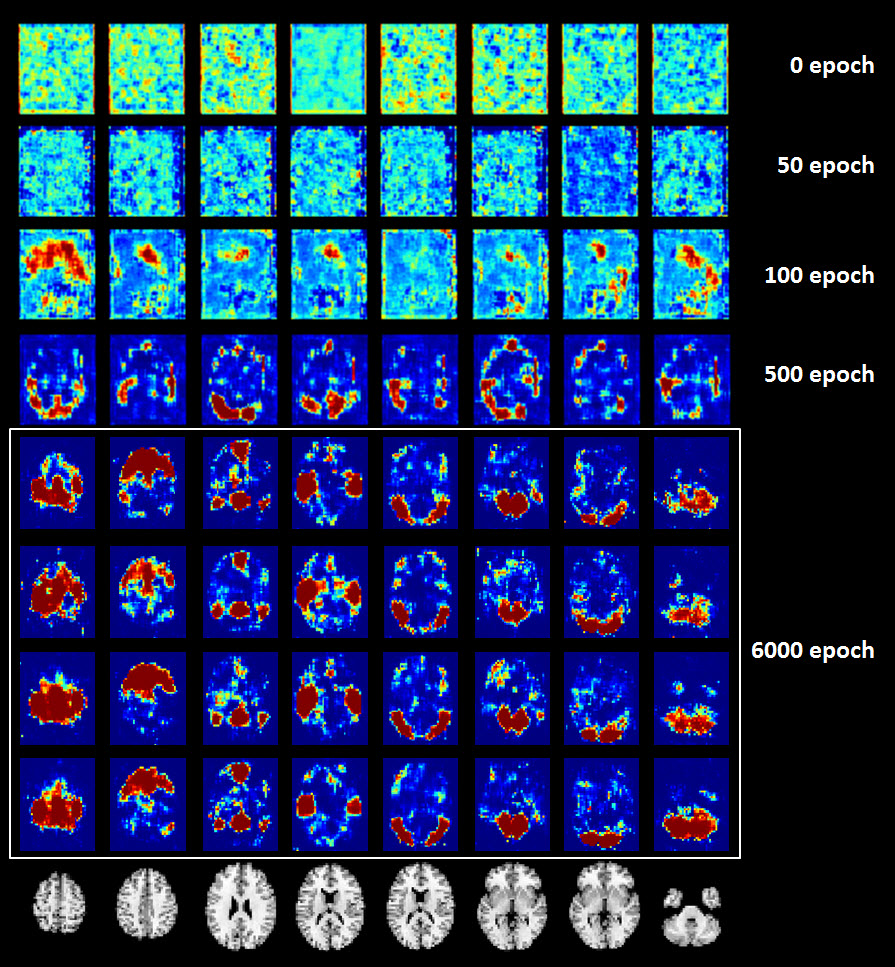
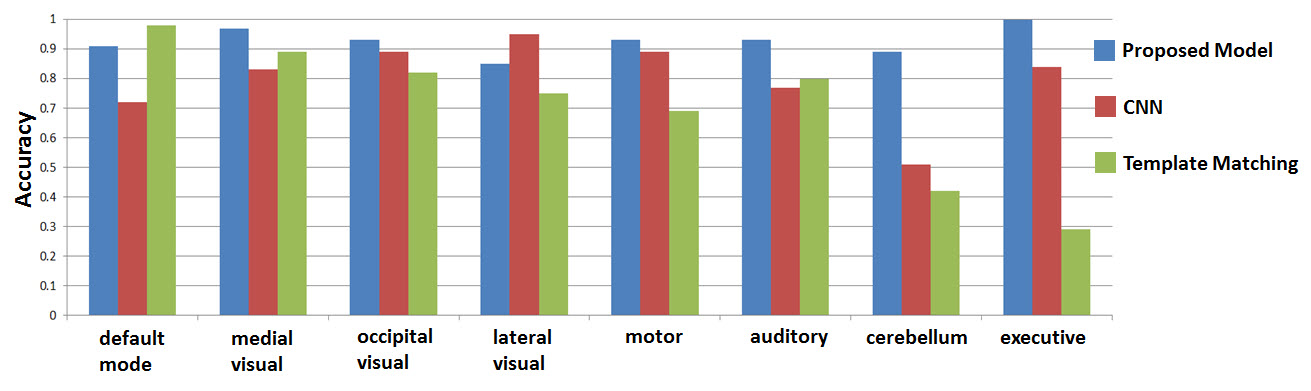
The discriminator achieved 99.8% and 98.7% classification accuracy for training and testing dataset respectively on the 8 RSNs in consideration, demonstrating the effectiveness of the proposed model and parameter selection. Figure 2 shows two cases that were not agreed with the manual labeling in the testing dataset. Figure 3 shows that the trained generator can synthesize real-world like RSN data after 6000 epochs. For the 57 evaluation datsets, we compared the proposed method to a a traditional deep convolutional neural network (CNN, with similar network architecture as the discriminator) and a template matching method. As observed in Figure 4, the proposed CNN method showed over-all improvement in the detection of the eight RSNs in considered (93%-GAN vs 78%-CNN vs 70% - Template Matching).Discussion and Conclusion
We propose a fully automatic deep 3D GAN based method that can reliably identify ICA components corresponding to the eight major RSNs which out-performs the traditional CNN and template matching methods. Template matching does not generalize well to unseen samples that do not match any of the templates. CNNs are easy to train, but are prone to over-fit to a particular data source when the amount labeled training data is limited. In addition, CNNs can easily be fooled to give high-confidence predictions to out-of-distribution examples. Finally, the generated images could potentially be used as a source of data augmentation.Acknowledgements
This work was supported by the Department of Defense in the Center for Neuroscience and Regenerative Medicine and the Intramural Research Program of the National Institutes of Health (Clinical Center and NINDS).References
1. Goodfellow I, Pouget-Abadie J, Mirza M, et al. Generative adversarial nets. Advances in Neural Information Processing Systems. 2014; 2672–2680.
2. Odena Augustus. Semi-supervised learning with generative adversarial networks. Data Efficient Machine Learning workshop at ICML 2016.
3. Grecius M, Srivastava G, Reiss A, et al. Default-mode network activity distinguishes Alzheimer’s disease from healthy aging: Evidence from functional MRI. Proceedings of the National Academy of Sciences 101. 2004; 4637-4642.
4. Demertzi A, Gomez F, Crone J, et al. Multiple fMRI system-level baseline connectivity is disrupted in patients with consciousness alterations. Cortex 2014; 52: 35-46.
5. Beckmann C, Smith S, Probabilistic independent component analysis for functional magnetic resonance imaging. IEEE Trans. Med. Imaging. 2004; 230 (2): 137–152.
Figures