3495
A Real-time Solver for Convex Optimization of Diffusion Encoding Gradient Waveforms1Radiology, Stanford University, Stanford, CA, United States
Synopsis
Recent work has demonstrated the usefulness of designing time optimal gradient waveforms for diffusion encoding, especially when incorporating gradient moment nulling to mitigate bulk motion artifacts. Prolonged optimization times, however, can limit the usability of these methods. This work presents a solver fast enough to run in real-time, and investigates the performance over a range of parameters and tests for convergence. The solver is able to generate diffusion encoding gradient waveforms with gradient moment nulling in 5-50 ms – fast enough to permit real-time optimization on the scanner.
Introduction
Recent work has demonstrated the usefulness of designing time optimal gradient waveforms for diffusion encoding1-4. By using the gradient hardware more efficiently and reducing gradient dead time, diffusion can be encoded with a smaller temporal footprint, which shortens TE and improves SNR. Additionally, gradients can be optimized to reduce sensitivity to bulk motion1 and reduce the effect of nerve stimulation5, eddy currents2, or concomitant fields3. Analytical solutions exist to subsets of these constraints4, however accomodating a wide range of protocols and choices in constraints requires optimization. Optimization techniques in previous work, however, generally require 2-30 minutes of compute time, limiting their real-world applicability. The purpose of this work was to demonstrate that diffusion gradients can be optimally designed in real-time, on the scanner, for on-the-fly protocol design. Tradeoffs between computation speed and the final gradient waveform designs are evaluated, and the optimization software is provided.Solver
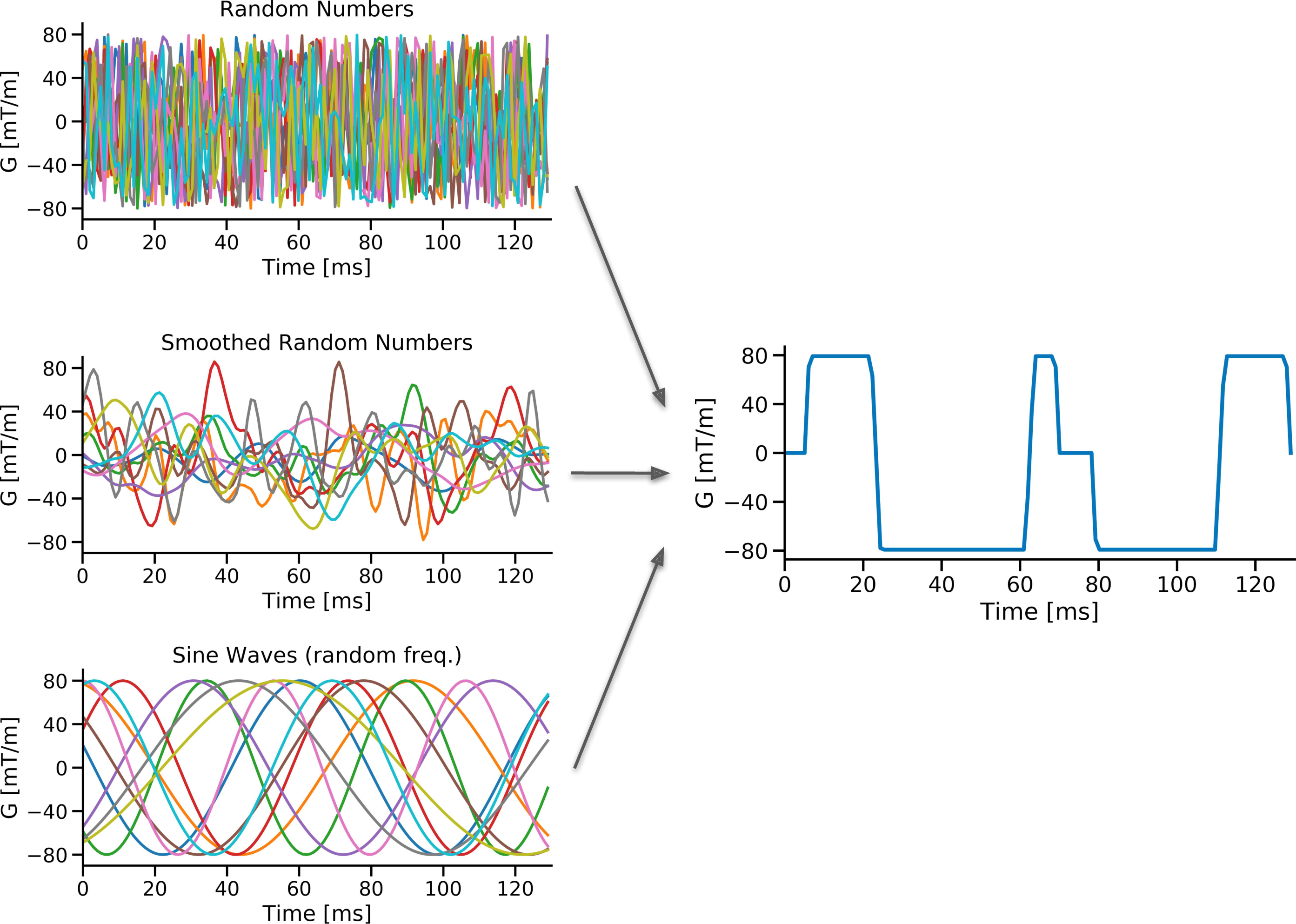
A primal-dual algorithm6 was used to run the maximization and enforce all of the constraints (Figure 1A). The optimization was run with two different maximization functions: on β-value and on b-value. β-value and is directly related to b-value1, but maximizing β-value does not necessarily maximize b-value. To speed up and promote convergence, a step in the optimization is added to restart and re-weight the descent if a solution was not reached in a set number of iterations, or if it is converging to a waveform that violates any of the hard constraints. The solver used for this study is available at github.com/mloecher/CVXG.Methods
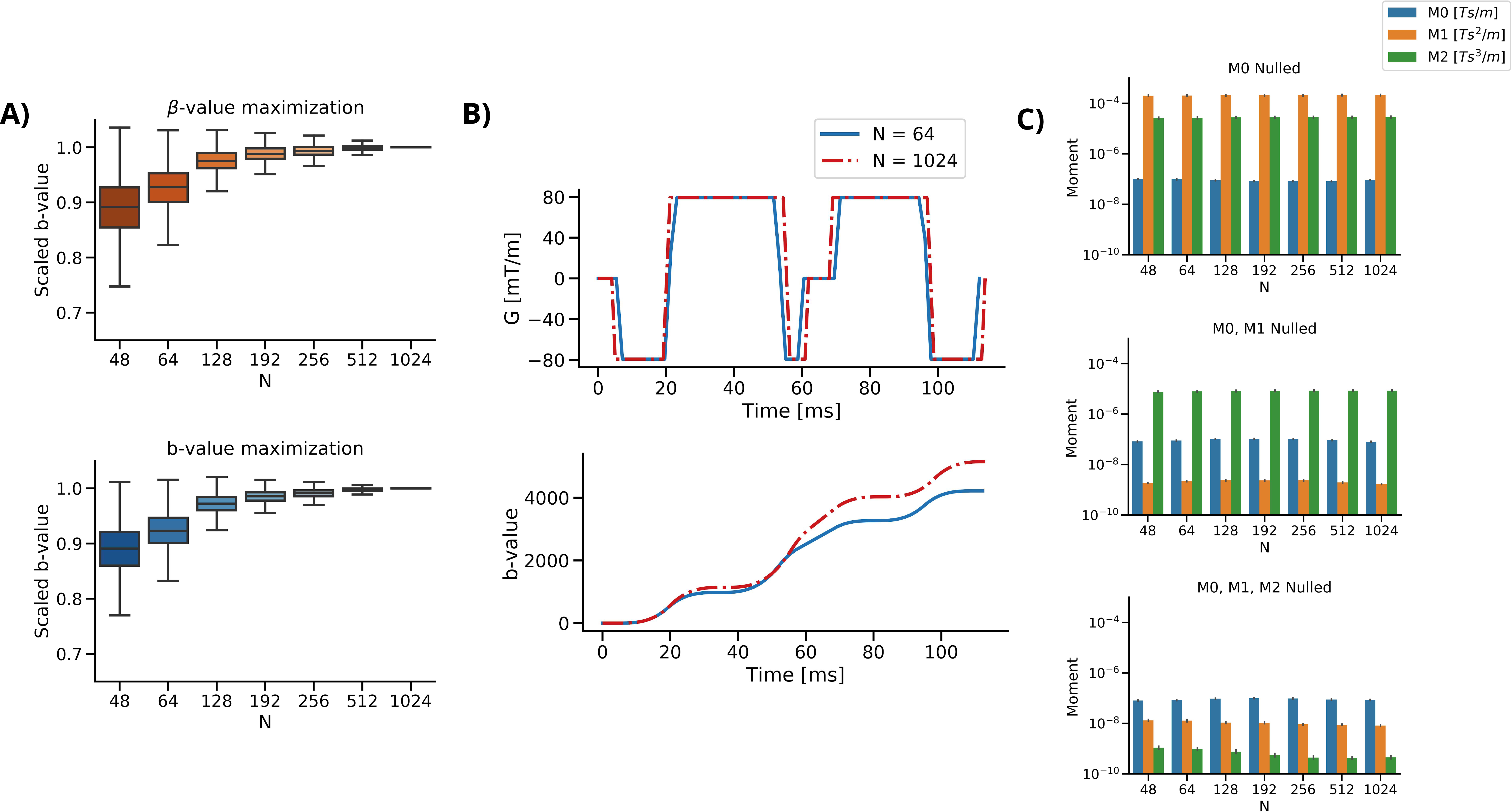
Analytic solutions are unavailable, therefore the solver was run on 10,000 random sets of input parameters (Figure 1B) and used to generate waveforms with either the β-value or b-value maximization cost function. This was done over a range of gradient raster times (fixed dt) or a fixed vector size N and therefore variable dt. N was used for most comparisons as it is directly related to compute time, while dt is also affected by TE (dt=TE/N). Compute time was measured on a standard desktop system (Intel 7700k) for all optimizations and reported in relation to N and dt. It is expected that a coarser waveform might not be able to generate as high of a b-value compared to a finely sampled one. The effect of N on b-value was evaluated by scaling all b-values from 0 to 1.0, where 1.0 is the b-value generated with the largest N (1024). The effect of N on the effectiveness of gradient moment nulling was also quantified. The b-value of waveforms generated with β-value maximization and b-value maximization was compared for different gradient moment nulling strategies. Additionally, the effect of gradient waveform initialization was tested as a preliminary investigation of convexity.Results
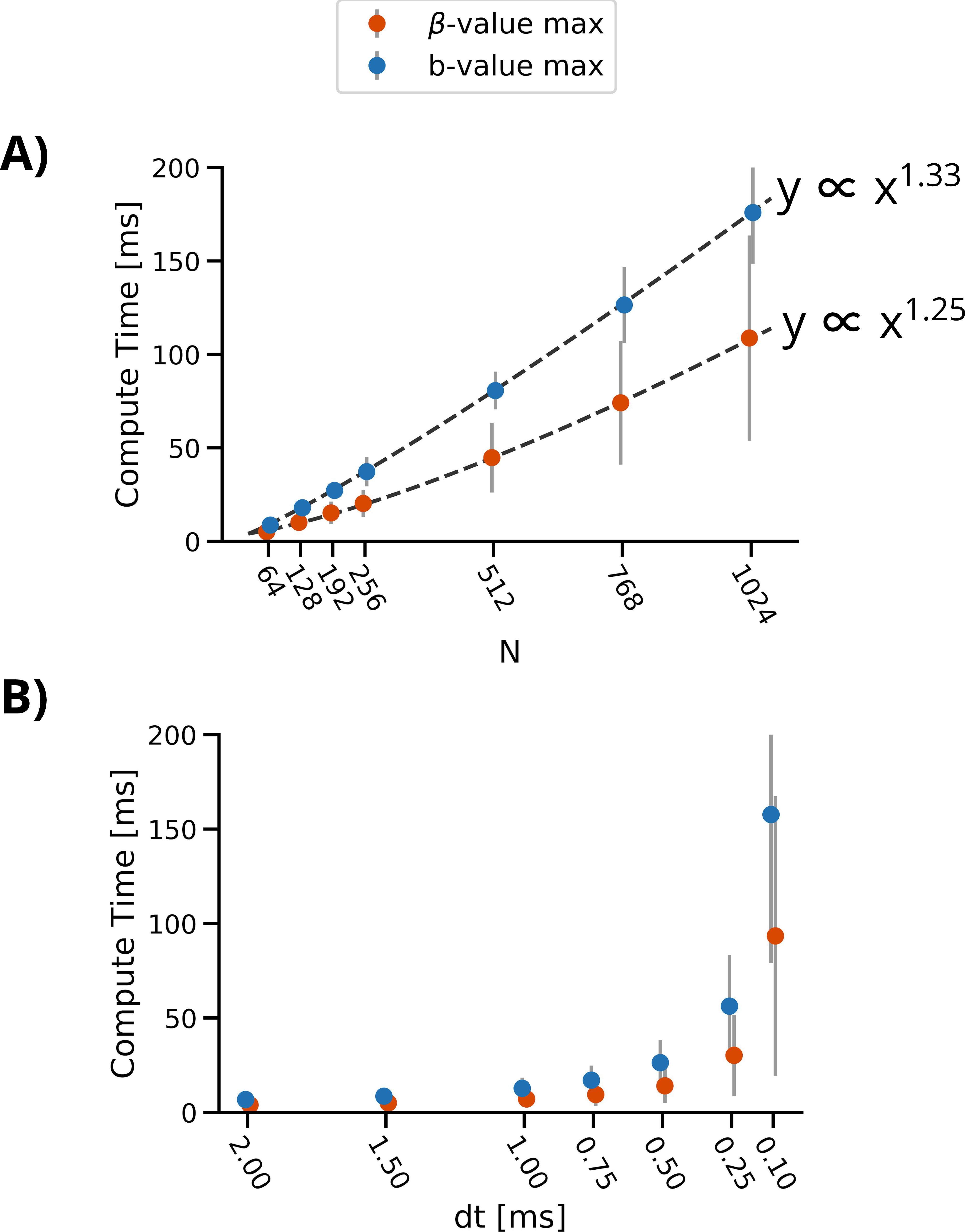
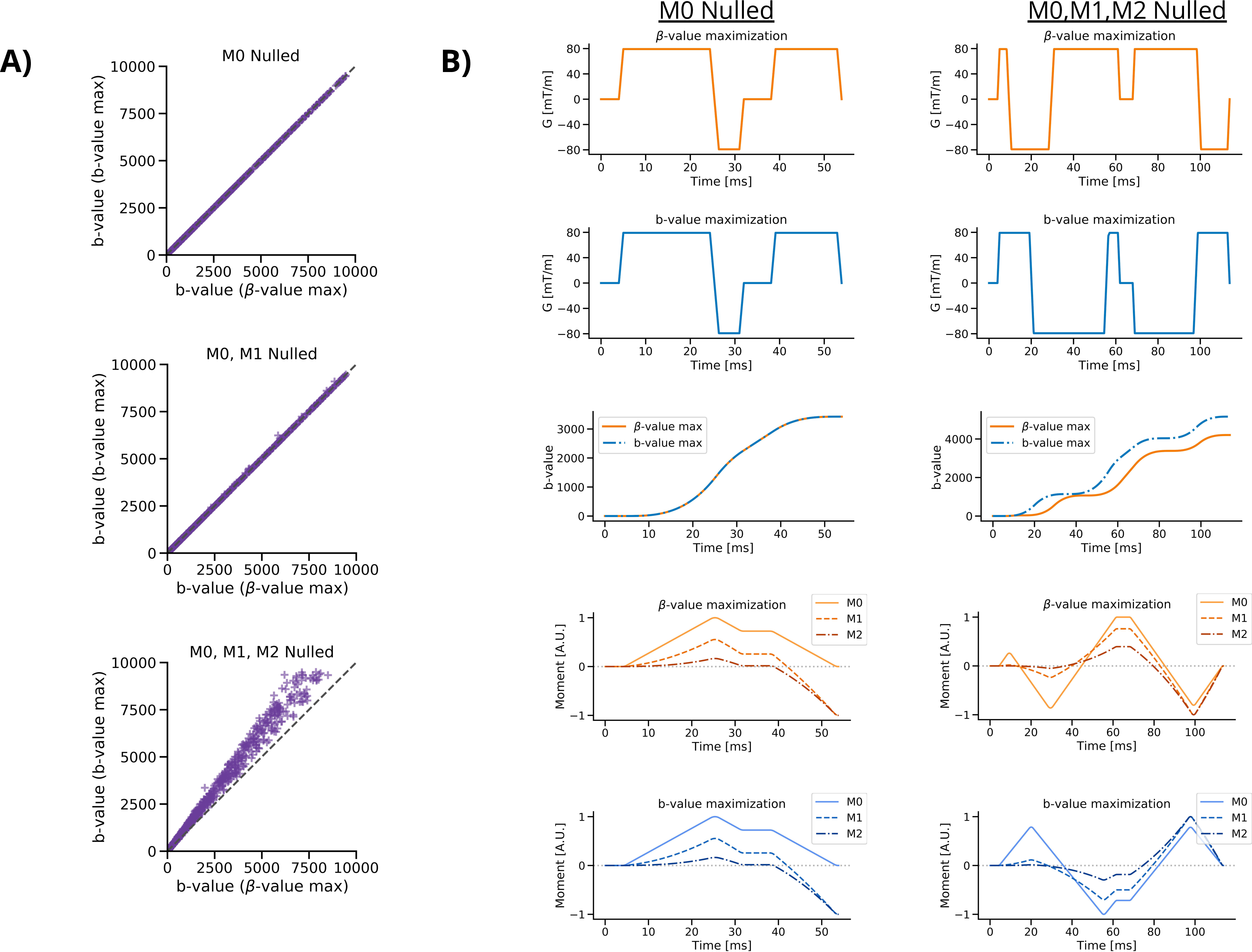
Figure 2 shows the compute time of the different maximization functions in relation to N or dt. The experimental computational complexity of β-value maximization was O(N1.25) and b-value maximization was O(N1.33). All compute times were fast (<50ms) for β-value maximization with N≤512, and for b-value maximization with N≤256. Figure 3A shows that smaller N leads to waveforms with less than optimal b-value relative to the ‘best’ solution. With N≥192, b-values were within 95% of the target b-value. Figure 3C shows the resultant gradient moments where no difference was seen as a function of N. Figure 4A shows that the b-value from both maximization functions are equivalent for M0 and M1 nulling, but with M1+M2 nulling the b-value maximization generated higher b-value waveforms for the same encoding duration. This will translate to shorter TEs with b-value maximization. Figure 5 shows the result of initializing the optimization with different input waveforms, where all input waveforms were seen to converge to the same output.Discussion
This work demonstrated a gradient optimization method that can operate fast enough for on-the-fly calculations. With N=256, solutions can be reached in under 50ms and within ~5% of the optimal b-value, giving a good tradeoff between compute speed and high b-values. The choice of maximization function appears to have no effect on the waveform design for M0 and M0+M1 nulling, however, b-value maximization performs better for M0+M1+M2 maximization. When tested, non-convex behavior was not observed with this solver, however, it has not been proven that all optimizations are truly convex, nor is it known with certainty that the solutions are the most time-optimal. Future work aims to address this with comparisons to known analytical solutions as well as more brute force techniques. Additionally, similar comparisons and analyses should be run with other constraints, such as those to limit eddy currents or concomitant fields.Acknowledgements
We would like to acknowledge funding sources NIH R01 HL131975 and HL131823References
1) Aliotta, E., Wu, H. H. & Ennis, D. B. Convex optimized diffusion encoding (CODE) gradient waveforms for minimum echo time and bulk motion-compensated diffusion-weighted MRI. Magnetic Resonance in Medicine 77, 717–729 (2017).
2) Aliotta, E., Moulin, K. & Ennis, D. B. Eddy current-nulled convex optimized diffusion encoding (EN-CODE) for distortion-free diffusion tensor imaging with short echo times. Magnetic Resonance in Medicine 79, 663–672 (2018).
3) Yang, G. & McNab, J. A. Eddy current nulled constrained optimization of isotropic diffusion encoding gradient waveforms. Magnetic Resonance in Medicine (2018)
4) Waqas Majeed, Prateek Kalra, Arunark Kolipaka. Motion Compensated, Optimized Diffusion Encoding (MODE) Gradient Waveforms. ISMRM 2018
5) Michael Loecher, Patrick Magrath, Eric Aliotta, Daniel Ennis. Accelerating 4D-Flow Acquisitions by Reducing TE and TR with Optimized RF and Gradient Waveforms. ISMRM 2018
6) Chambolle, A. & Pock, T. A First-Order Primal-Dual Algorithm for Convex Problems with Applications to Imaging. Journal of Mathematical Imaging and Vision 40, 120–145 (2011).
Figures