3482
DKI parameter inference by deep neural networks trained by synthetic data1Radiology, Hiroshima Heiwa Clinic, Hiroshima, Japan, 2Graduate School of Information Sciences, Hiroshima City University, Hiroshima, Japan
Synopsis
In general, DKI parameters (D and K) are obtained by fitting models to DWI signal values, such as by least-square fitting (LSF) methods. However, when DWI signal values are contaminated by noise of high level, fitting error is often observed especially for diffusional kurtosis K. In this study, we propose a robust method to infer DKI parameters based on deep neural networks trained by only synthetic data to overcome the limitations of real data training. Our experimental results including comparison with LSF showed the potential of our method for robust inference of DKI parameters.
Introduction
Diffusional kurtosis parameter in DKI model [1] quantifies non-Gaussian displacement of water molecules in vivo. However, it is often reported that robust inference of K is hard due to its sensitivity to DWI noise, and so-called pepper noise is observed [2]. Generally, DKI parameters are obtained by fitting models to DWI signal values, such as by least-square fitting (LSF) methods. Recently, it has been reported that machine-learning approaches are useful for such diffusion MRI parameter inference [3]. One of the important drawbacks of the approaches is that training data of limited amount and variation may cause inaccurate inference for the voxels such as at pathological structures not included in the training data. The purpose of this study is to infer DKI parameters using deep neural networks trained by only synthetic data to overcome the problem. Our synthetic training dataset with wider value range is contaminated with Rician noise [1]. In this abstract, we present experimental results of DKI parameter inference by neural networks trained with various levels of noise, and discuss optimal noise level determination for neural network training.Methods
In the first step of our training data synthesis, values of baseline signal $$$S_{0}$$$, diffusion coefficient D, and diffusional kurtosis K are generated as uniform random numbers. Next, DWI signal values for b-factor = 311, 1244, and 2800 are generated by the DKI signal value model . Then, Rician noise is added to $$$S_{0}$$$ and $$$S$$$ so that new value becomes $$$\sqrt{S^2+N(0, \sigma)^2}$$$, where $$$N$$$ shows zero-mean Gaussian noise of standard deviation $$$\sigma$$$. The noise ratio is adjusted for $$$\sigma\diagup S_{0}$$$ with values of 0.0, 0.1, 0.3, 0.5, 0.7, 1.0, and 1.5. For synthetic data test, another dataset is also created with different random number seed. For each dataset for training and test, $$$10^{5}$$$ samples are generated. The synthetic training data is transferred to multi-layer perceptron (MLP) [3] (Fig.1), which uses logarithm of signal decay as input and outputs D or K value. A real dataset is also prepared for test, which is a head DWI dataset of a healthy volunteer with informed consent. DWI is acquired in isotropic voxels of 3 mm, b-factor = 0, 311, 1244, 2800 DWI and MPG direction is AP (0, 1, 0). The LSF results are also obtained for comparison based on the DKI closed-form solution [2].
Results
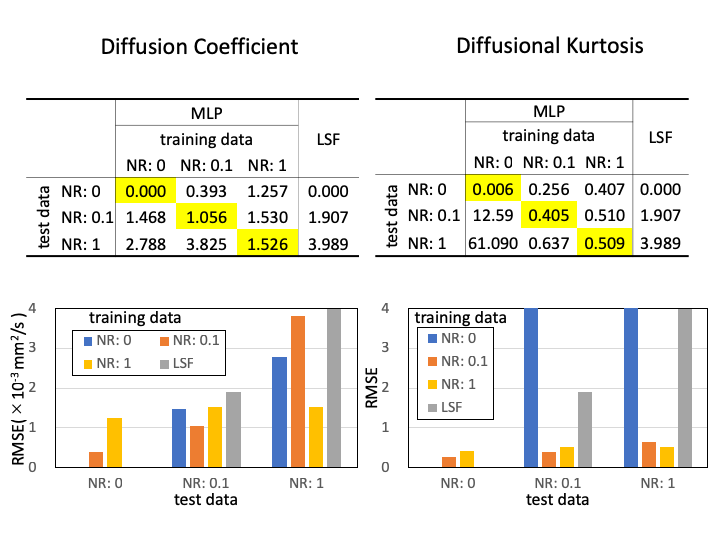
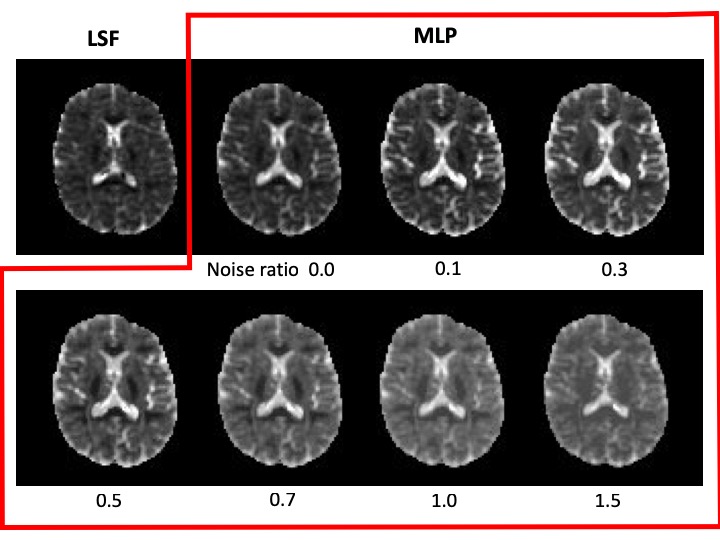
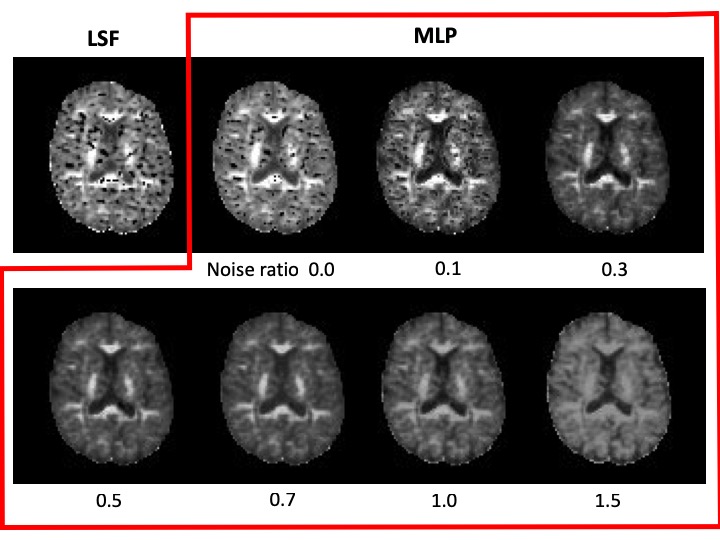
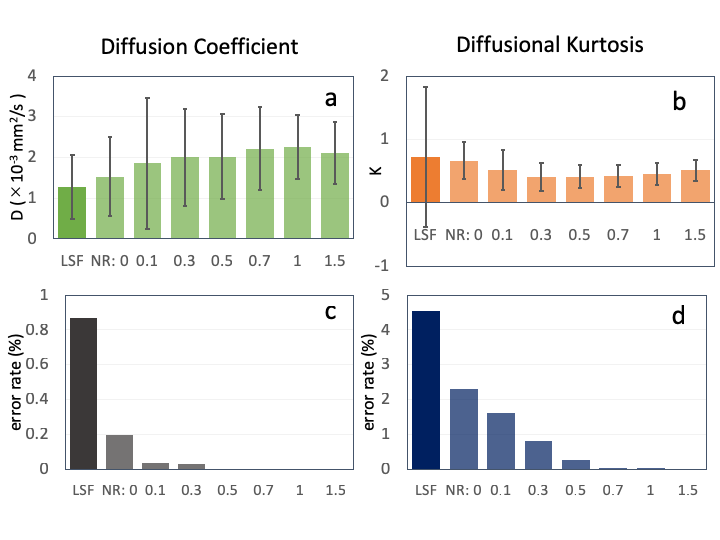
The root means square errors (RSME) of the inference results by LSF and MLPs in synthetic data test are summarized in Fig.2. Nine combinations of training data and test data were examined by using noise ratio of 0.0, 0.1 and 1.0. When the noise ratios of training data and test data matched, the error was minimized. For the real data test results, Fig.3 and 4 show D and K images inferred by LSF and MLPs trained with all noise ratios. Apparently, less pepper noise is observed in MLP results than LSF, and it seems to be disappeared in more than 0.5 of noise ratio. Fig.5 shows the mean and standard deviation (SD) of the signal values in the real data inference results excluding voxels with errors in addition to error rate within the whole brain. Inference error is defined when a negative value is obtained for D or K. The error rate was decreased by increasing the training noise ratio, however the inferred values might be biased and not be stable within the range of this experiment.Discussion
Our synthetic data test clearly indicates that matching of noise level between training data and test data is important for robust inference of parameters. In addition, our real data test also revealed important facts. As shown in the results of parameter inference by noiseless training, i.e. noise ratio is 0.0, the results is very similar to those by LSF. In addition, by increasing noise ratio, the robustness seems to be improved, although the image contrast was lost and seems the values are biased. That is, under-contamination of training data leads to low robustness, and over-contamination yields to vanishing contrast effect. By considering that it is not a simple problem to estimate noise level in real MRI data, it is needed to prepare several MLPs of different level of noise level and to choose the most suitable one in an automatic way.Conclusion
A new approach of DKI parameter inference is proposed based on deep neural networks trained by only synthetic data. Experimental results show its potential usefulness for clinical data analysis. Further investigation is planned including automatic adaptation of training noise level for each clinical dataset.Acknowledgements
No acknowledgement found.References
- Jensen JH, Helpern JA, Ramani A, et al. Diffusional kurtosis imaging: the quantification of non-Gaussian water diffusion by means of magnetic resonance imaging. Magn Reson Med, 2005;53:1432-1440.
- Masutani Y, Aoki S. Fast and Robust Estimation of Diffusional Kurtosis Imaging (DKI) Parameters by General Closed-form Expressions and their Extensions. Magn Reson Med Sci, 2014;13(2):97-115.
- Golkov V, Dosovitskiy A, Sperl IJ, et al. q-Space Deep Learning: Twelve-Fold Shorter and Model-Free Diffusion MRI scans. IEEE Trans. Med. Imag., 2016;35(5):1344-1351.
Figures
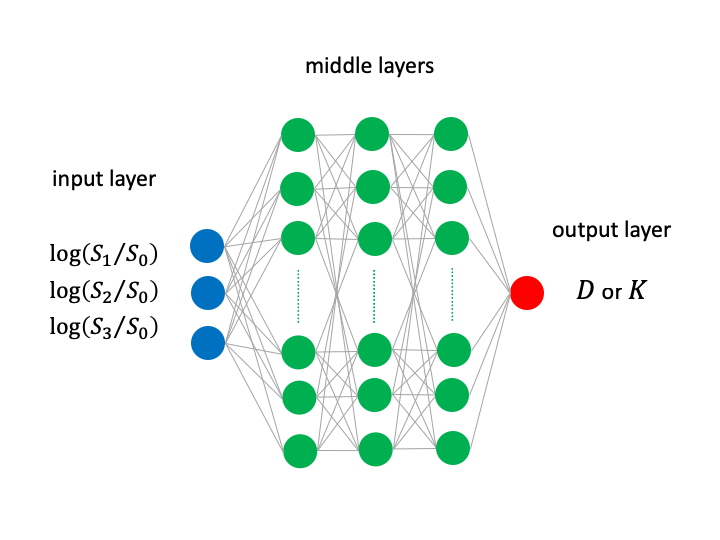
Figure 1. Structure of deep neural network for DKI parameter inference. A multi-layer perceptron with 3 middle layers of 128 units, activation function of ReLU, and no drop out units was used and was trained with batch size of 100 and 100 epochs.