3359
Deep learning for DSI parameter map generation without image pre-processing1Radiology and Imaging Sciences, University of Utah, Salt Lake City, UT, United States, 2Bioengineering, University of Utah, Salt Lake City, UT, United States
Synopsis
Recent advances in diffusion spectrum imaging (DSI) have reduced scan time considerably. Through the use of deep learning, DSI parameter maps (NODDI, GFA, etc.) can be generated with only a fraction of the number of q-space samples compared to conventional acquisition strategies. However, image pre-processing prior to the deep learning parameter map generation step is a computational bottleneck. This abstract explores if this bottleneck can be bypassed entirely and use images straight from the scanner as CNN inputs. We show that the image pre-processing is not necessary to generate NODDI and GFA parameter maps--thereby avoiding the image processing computation time.
Introduction
Diffusion magnetic resonance imaging (MRI) is an invaluable tool in neuroimaging and is included in many neurological protocols for imaging intracranial diseases such as stroke, infection, and tumor monitoring. Common quantitative diffusion imaging techniques include diffusion tensor imaging (DTI) and diffusion spectrum imaging (DSI). DSI techniques--particularly quantitative approaches such as generalized fractional anisotropy (GFA)--aim to generalize DTI by increased sampling of q-space, though at the cost of increased scan time. While advances have reduced DSI scan time to 15 minutes, DTI still remains the clinical standard. Recent Deep learning techniques have further reduced DSI imaging scan time to the order of 2-3 minutes[1,2].
Deep learning techniques have relied on extensive image pre-processing prior to being fed into the neural network. This pipeline consists of for example skull stripping[3], noise removal[4], removal of noise bias[5], Gibb’s ringing correction[6], and off-resonance and eddy current distortion removal. While the network has been demonstrated to achieve high performance with these preprocessed images, using this pipeline is cumbersome. In particular, a scan with 51 slices can take up to two hours to process, which can hamper clinical feasibility. This work examines the necessity of using these pre-processing techniques or if deep learning networks can be successful given noisy inputs with no pre-processing.
Methods
DSI data were acquired from 48 scans from a total of 29 subjects. All DSI data were acquired using a Siemens 3T Verio (Erlangen, Germany) with max gradient strength of 45 mT/m, maximum slew rate of 200 mT/m/s, and a 32 channel head coil. Each DSI scan acquired data with a maximum b-value of 4000 s/mm2 and 203 directions. For all scans, a simultaneous multi-slice blipped CAIPIRINHA pulse sequence with a threefold slice acceleration was used to acquire 51 slices per participant. The field-of-view was 250 mm x 250 mm with a voxel dimension of 1.9 mm x 1.9 mm x 2.1 mm. The TE/TR was 114.2 ms / 3.7 s. The total data acquisition time for each DSI scan was approximately 13 minutes.
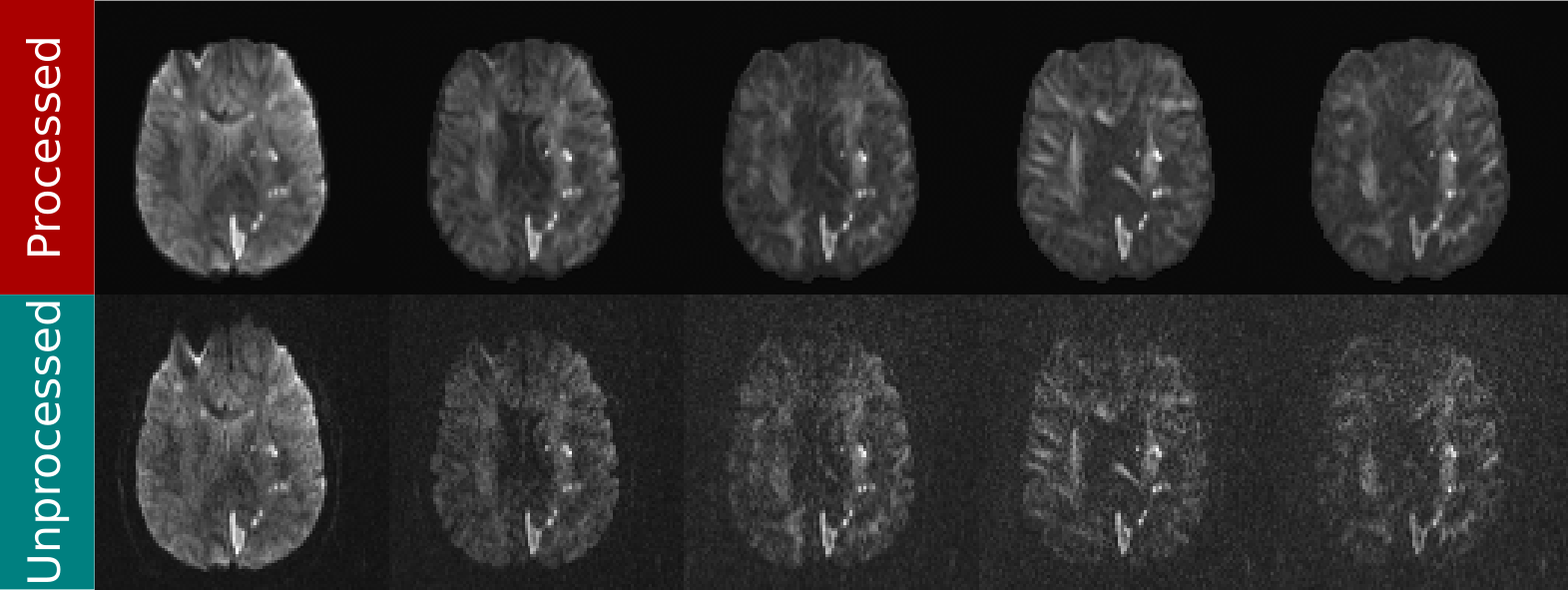
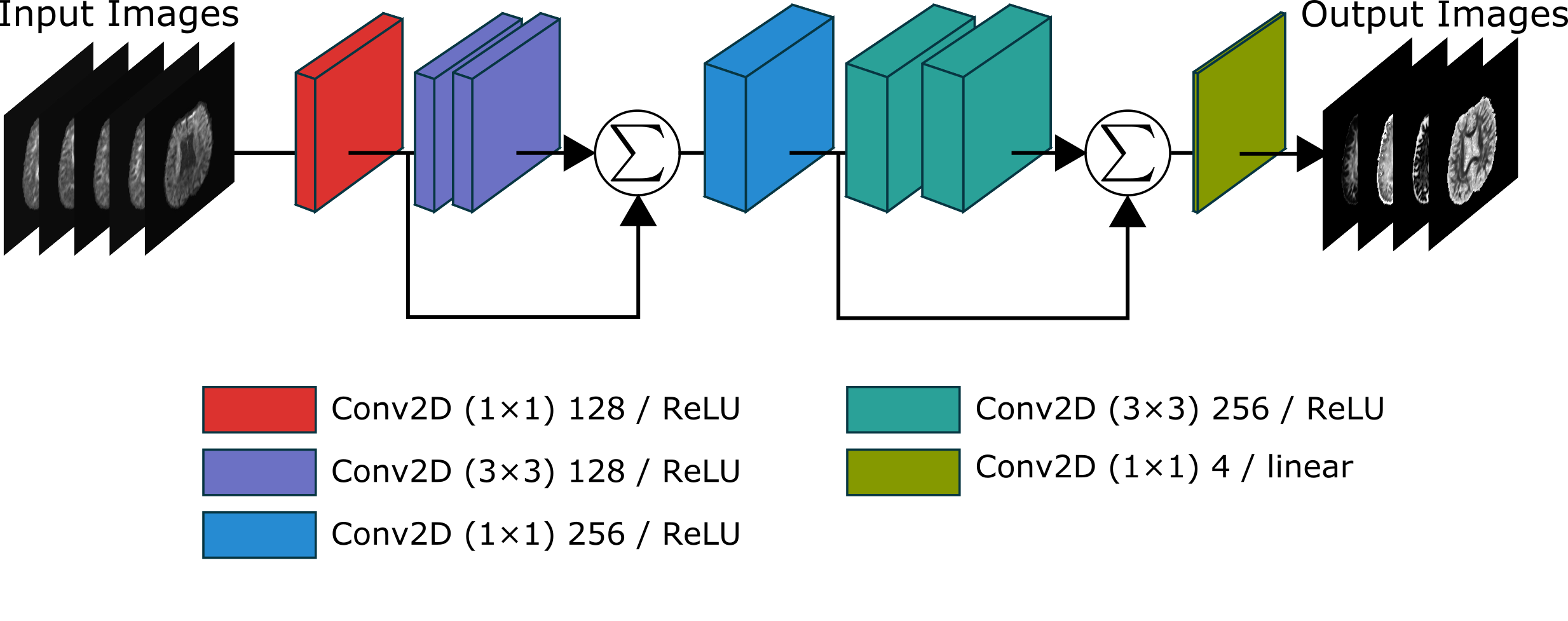
The data were pre-processed using the pipeline described above. A neural network as in [2] (see Fig. 1) was trained using the unprocessed and pre-processed data separately. Fig. 2 shows an example of both the pre-processed and the unprocessed data. Additionally, a deeper network (the same basic architecture as in [2] but with twice the number of layers) was trained using the unprocessed data to determine if there could be performance gains by modifying the network architecture. Comparisons for ODI and GFA against a reference were done by comparing standard metrics: NRMSE, PSNR, SSIM.
Results
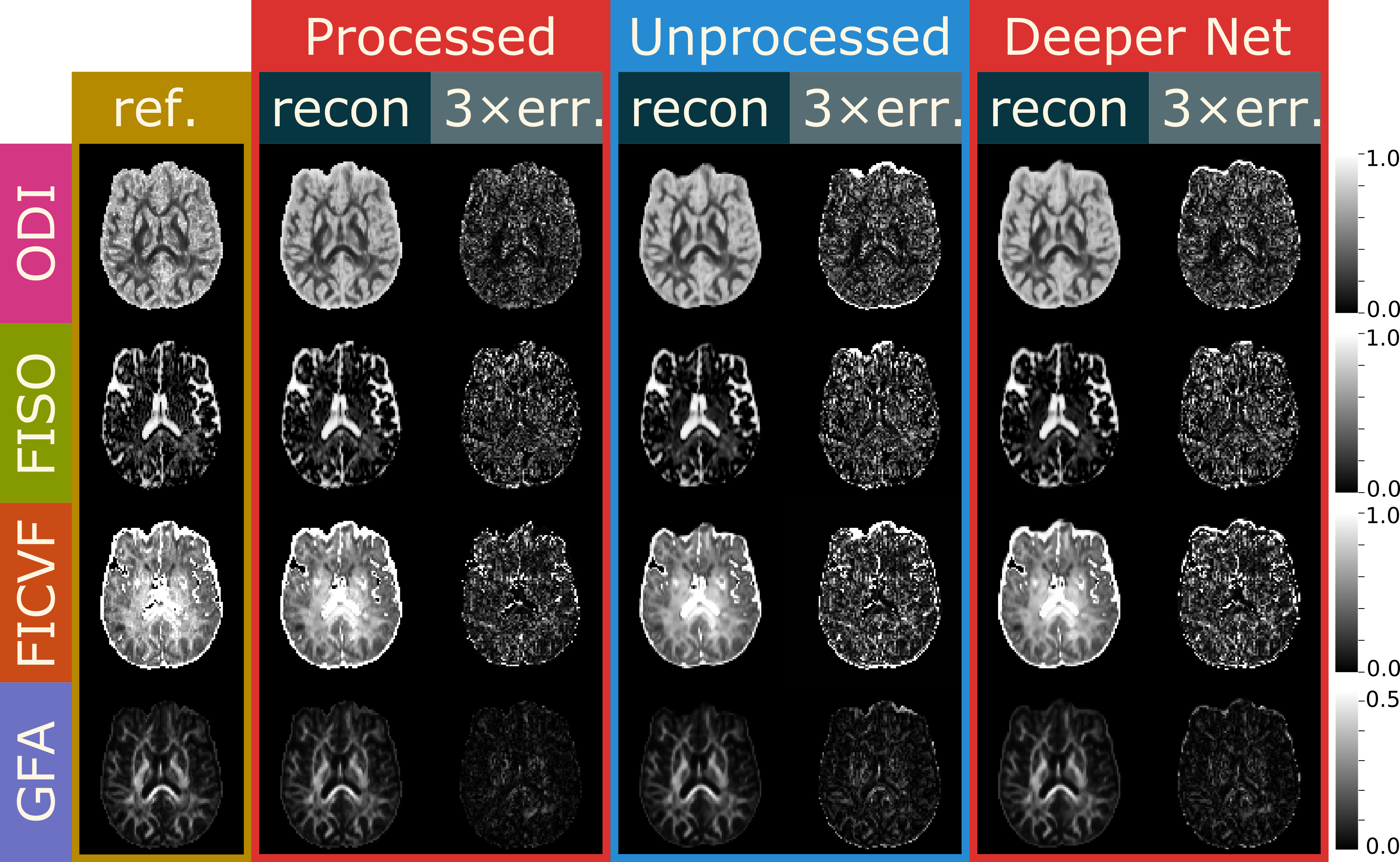
Fig. 3 shows example output images where q-space was subsampled to only 24 directions for three scenarios: the original network and preprocessed input data, the original network and unprocessed data, and a deeper network with unprocessed data. In difference images, eddy current correction is not resolved by the neural networks showing strong deviations from the reference along the perimeter of the brain.
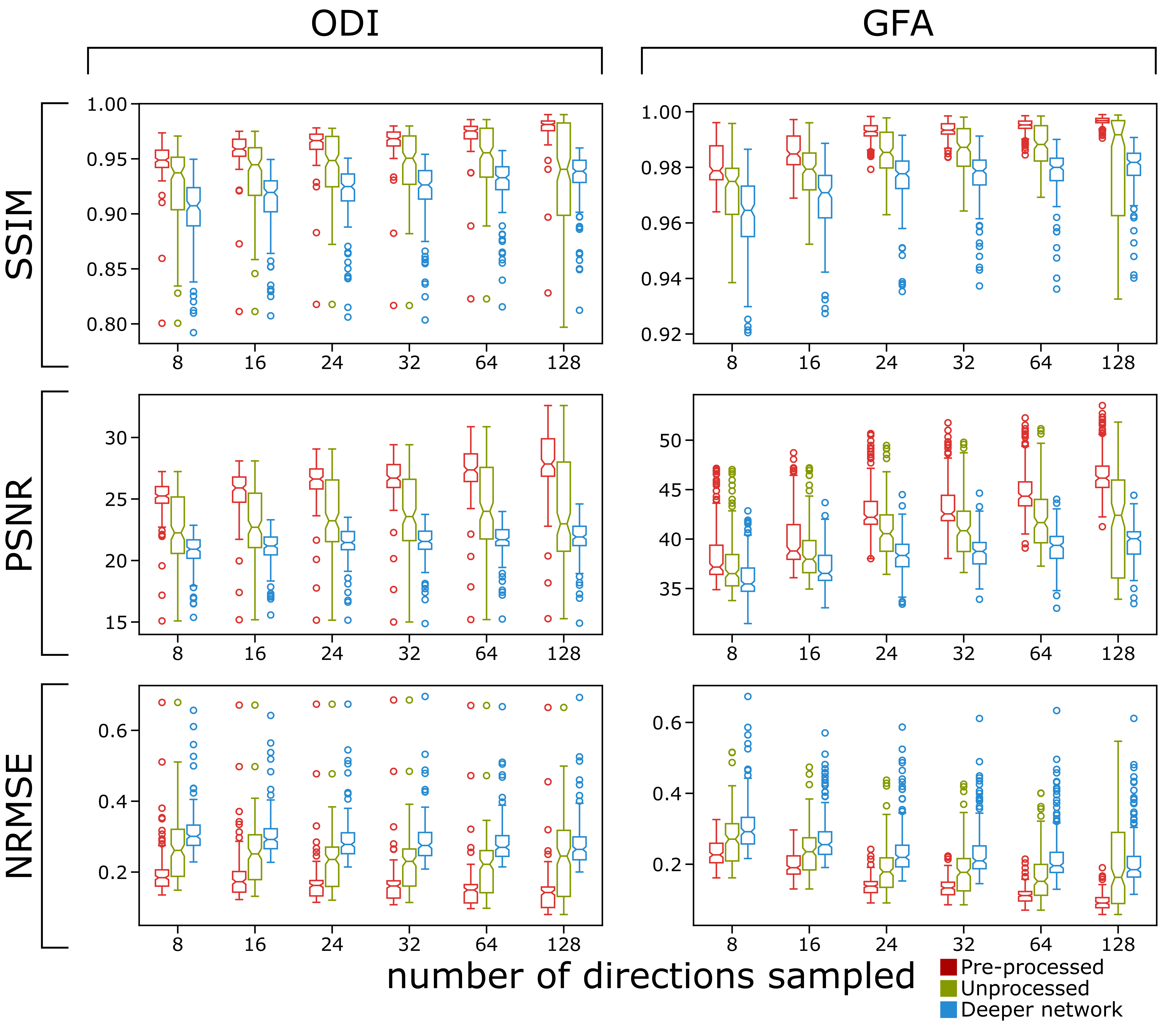
Quantitative results are seen in Fig. 4. It is clear from the box and whisker plots that the preprocessed data result in higher fidelity output images in terms of SSIM, PSNR, and NRMSE. Additionally, the shallower network also outperforms the deeper network across all metrics.
Discussion
While the preprocessed input provides higher fidelity output images based on standard quantitative image comparison metrics, it is misguided to discount the method of using the unprocessed images. Much of superiority of the pre-processed case in terms of quantitative metrics seen in Fig. 4 likely comes from image blurring for the outputs for the unprocessed images as well as failure to correct for eddy current-induced image warping. In terms of blurring, we hypothesize that because the input images are inherently noisy, the network learns considerable noise suppression, which leads to image blurring as a secondary effect. This seems compounded in the case of the deeper network where there are more convolutional layers, which is likely why we see more blurring in those images compared to the shallower network. In terms of image warping, the edges of the output images will not perfectly align with the edges of the reference images. While the network is able to resolve parameter maps through noise, noise bias, and Gibb’s ringing, it may not fully handle image distortion. There is some improvement in this area by using a deeper network.
Conclusion
We have demonstrated a rapid method of generating DSI parameter maps using unprocessed images as inputs to a convolutional neural network with slight compromise in image fidelity. Future improvements could include a separate network to handle the image pre-processing steps to achieve both higher parameter map fidelity as well as processing speed.Acknowledgements
The authors would like to thank the Departments of Neurology and Occupational and Recreational Therapies for assistance in data collection.References
[1] Golkov V, Dosovitskiy A, Sperl JI, Menzel MI, Czisch M, Samann P, Brox T, Cremers D. q-space deep learning: twelve-fold shorter and model-free diffusion MRI scans. IEEE Transactions on Medical Imaging 2016; 35:1344-1351.
[2] Gibbons EK, Hodgson KK, Chaudhari AS, Richards LG, Majersik JJ, Adluru G, and DiBella EVR. Simultaneous cross parameter map generation from subsampled q-space imaging using deep learning. Magnetic Resonance in Medicine, 2018; 00:1-13.
[3] Smith SM. Fast robust automated brain extraction. Human Brain Mapping 2002; 17:143-155.
[4] Veraart J, Fieremans E, Novikov DS. Diffusion MRI noise mapping using random matrix theory. Magnetic Resonance in Medicine 2016; 76:1582-1593.
[5] Koay CG, Basser PJ. Analytically exact correction scheme for signal extraction from noisy magnitude MR signals. Journal of Magnetic Resonance 2006; 179:317-322.
[6] Kellner E, Dhital B, Kiselev VG, Reisert M. Gibbs-ringing artifact removal based on local subvoxel-shifts. Magnetic Resonance in Medicine 2016; 76:1574-1581.Andersson JL, Graham MS, Zsoldos E, Sotiropoulos SN. Incorporating outlier detection and replacement into a non-parametric framework for movement and distortion correction of diffusion MR images. NeuroImage 2016; 141:556-572.
Figures