3348
Super-Resolution Diffusion Imaging using Deep Learning: A Feasibility Study1Department of Radiology and Imaging Sciences, Indiana University School of Medicine, Indiana University, Indianapolis, IN, United States, 2Indiana Alzheimer Disease Center, Indianapolis, IN, United States
Synopsis
In this study, we present and validate the efficacy of using a state-of-the-art deep-learning method to achieve submillimeter high-resolution diffusion-weighted (DW) images. The 2D-based deep-learning method was validated by comparing diffusion tensor imaging (DTI) and neurite orientation dispersion and density imaging (NODDI) of the deep-learning high-resolution images and the ground-truth.
Introduction
High-resolution diffusion imaging suffers from long scan times and low signal-to-noise ratio. In this abstract, we purpose a new method based on deep-learning to enable super-resolution of DW images. The single image super-resolution problem in its simplest form can be stated as the process of recovering a high-resolution image $$$Y$$$ from a low resolution image $$$X$$$ using a non-linear function $$$Ψ$$$:
$$Y = Ψ(X),$$
which is an ill-posed problem. One of the classes of the algorithms that solve the single image super-resolution is patch-based. In the patch-based algorithm, a given high-resolution image is divided into patches and each patch is downsampled to a low-resolution patch image, from which we can apply feature extraction. Then through iterative training between the high-resolution and low-resolution pair, the optimal function is obtained. Then the full image $$$Y$$$ can be reconstructed using the individual functions that map between the low-resolution and high-resolution.
This training can be achieved by building an external dictionary that encodes the mapping between the high-resolution patch and the low-resolution patch, which is usually computationally expensive. Deep-learning, however, may significantly reduce the computation time and the required resources. As proposed by 1, the super-resolution convolutional neural network (SR-CNN) algorithm 2 recovers the high-resolution image in a similar fashion (i.e., patch-based algorithm) without the need to explicitly learn the dictionaries. Instead, several CNN layers could be used to non-linearly map local and global image features between the low-resolution and high-resolution patches. Finally, the reconstruction is applied to form the high-resolution image $$$Y$$$ from the individually reconstructed high-resolution patches.
Methods
MRI acquisition and reconstruction
Hybrid Diffusion Imaging (HYDI) 3,4 was performed on a healthy volunteer. The diffusion images were acquired on a Siemens Prisma scanner using a single-shot spin-echo EPI with a multiband factor of 3. TR/TE = 4164/74.2 ms, 220 mm field of view, 114 slices. A four-shell diffusion imaging with monopolar diffusion scheme was used with b-values 500, 800, 1600, 2600 s/mm2, 134 diffusion directions, and 8 non-diffusion-weighted volumes. Data was acquired in two sets with reversed phase-encode blips. Using the same parameters described above, we acquired two sets of diffusion images: low resolution of 2.5x2.5x2.5 mm3 for a demonstration of the proposed method and high resolution of 1.25x1.25x1.25 mm3 as ground truth for comparison.
Preprocessing
All the DW images were denoised from Rician noise using overcomplete local Principal Component Analysis 5. And FSL-topup which is a part of the FSL package version 5.0.11 (FMRIB, Oxford, UK) was used to calculate and correct the susceptibility distortions, and FSL-eddy 6 was used to correct motion.
Deep Learning
We used an SR-CNN 1 based deep-learning model that has been already trained with a depth compatible with the diffusion-weighted images (DWI).
Validation
We compared the results on diffusion metrics derived from the diffusion tensor imaging (DTI) and neurite orientation dispersion and density imaging (NODDI 7) models. We validated the proposed method using two datasets: a downsampled 2.5x2.5 mm2 image from a ground-truth 1.25x1.25 mm2 image and an image with a true acquisition resolution of 2.5x2.5 mm2. For the former, the comparisons used direct subtraction of the deep-learning high-resolution image and the ground-truth image. For the latter, the comparisons were made using ROI based approaches, where means and standard deviations of diffusion metrics in the standard space (MNI) were compared in 48 white-matter regions-of-interest (ROI) from Johns-Hopkins University atlas 8 and in 48 cortical ROIs from Harvard-Oxford atlas 9.
Results and Discussion
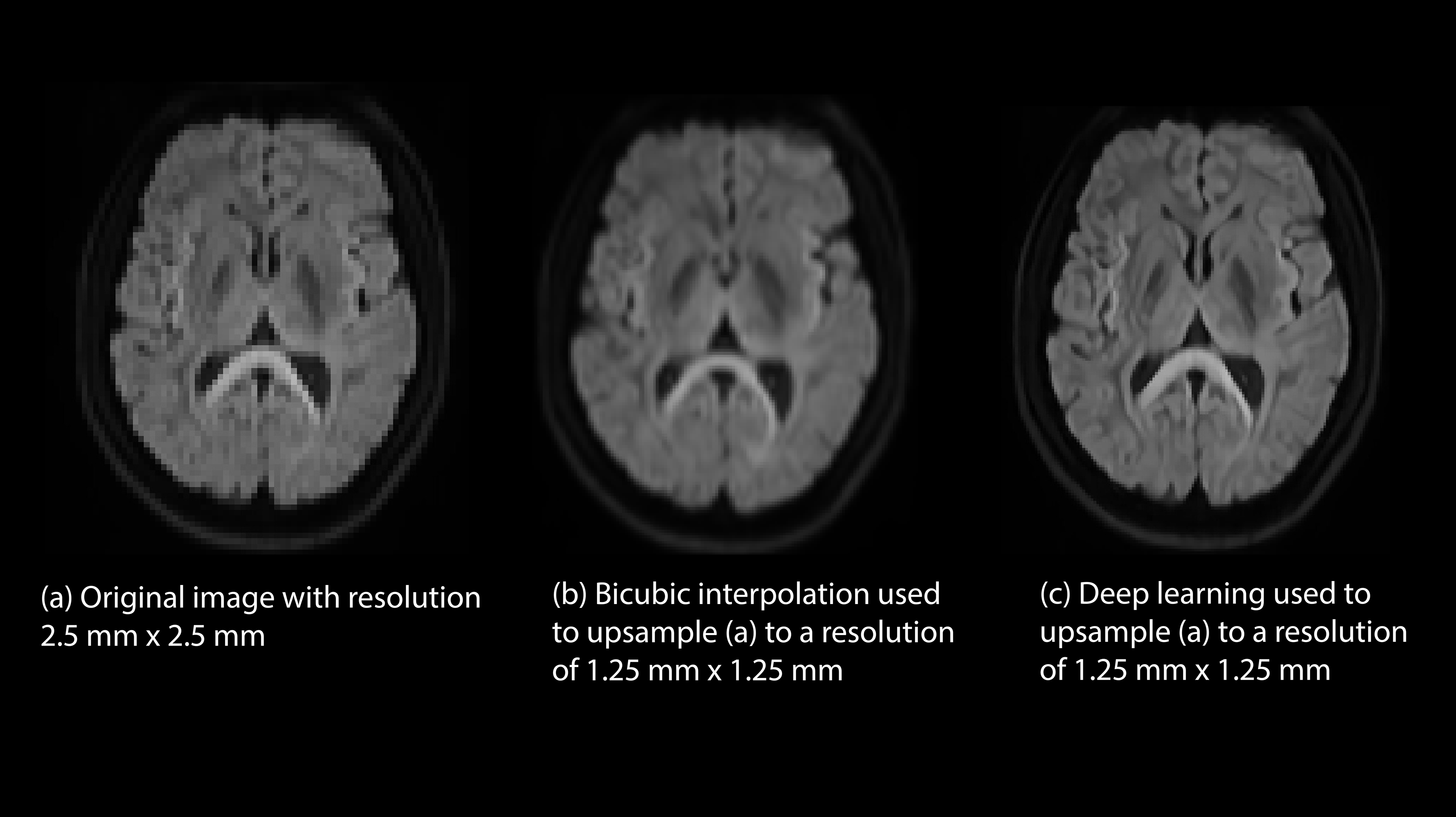
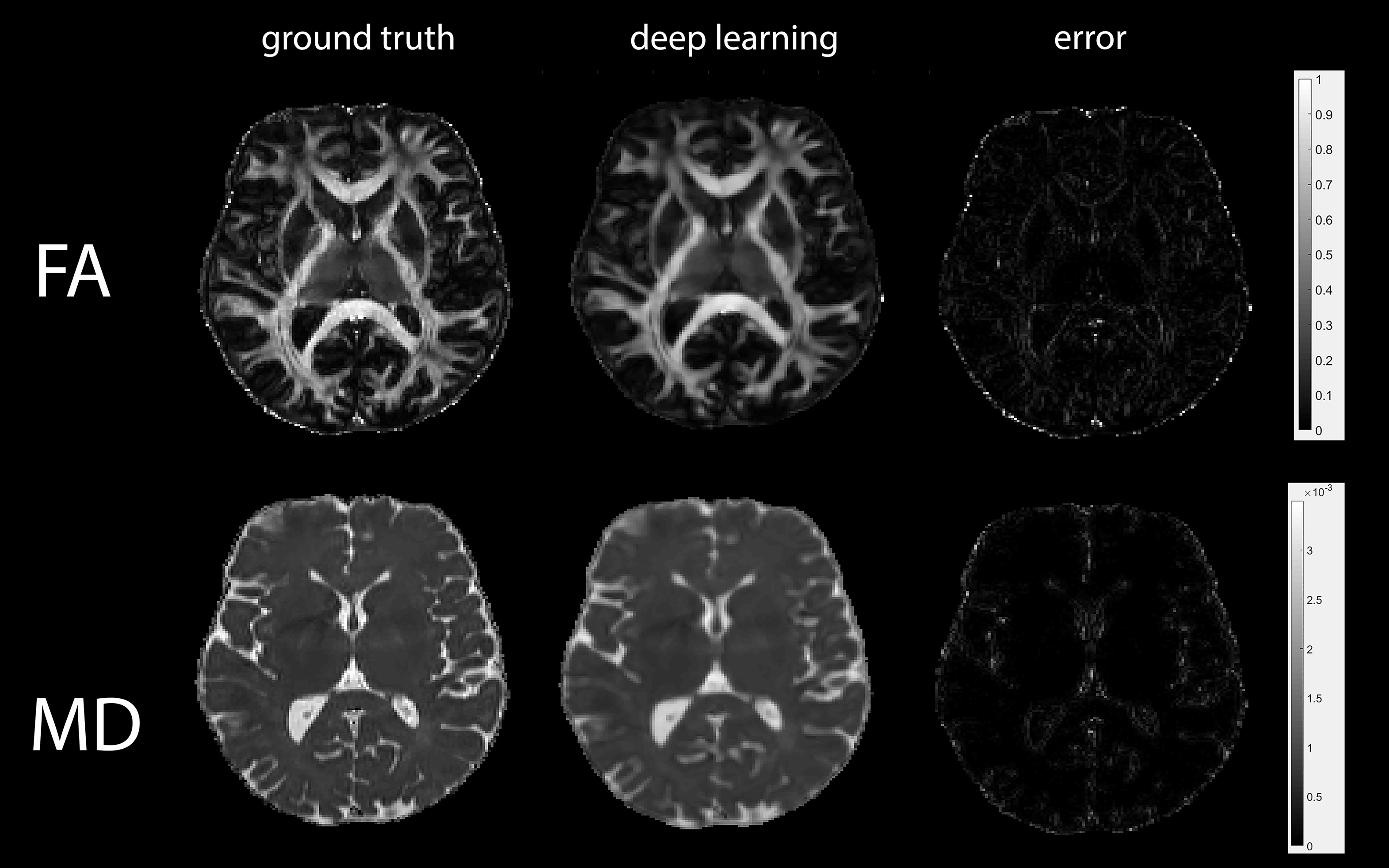
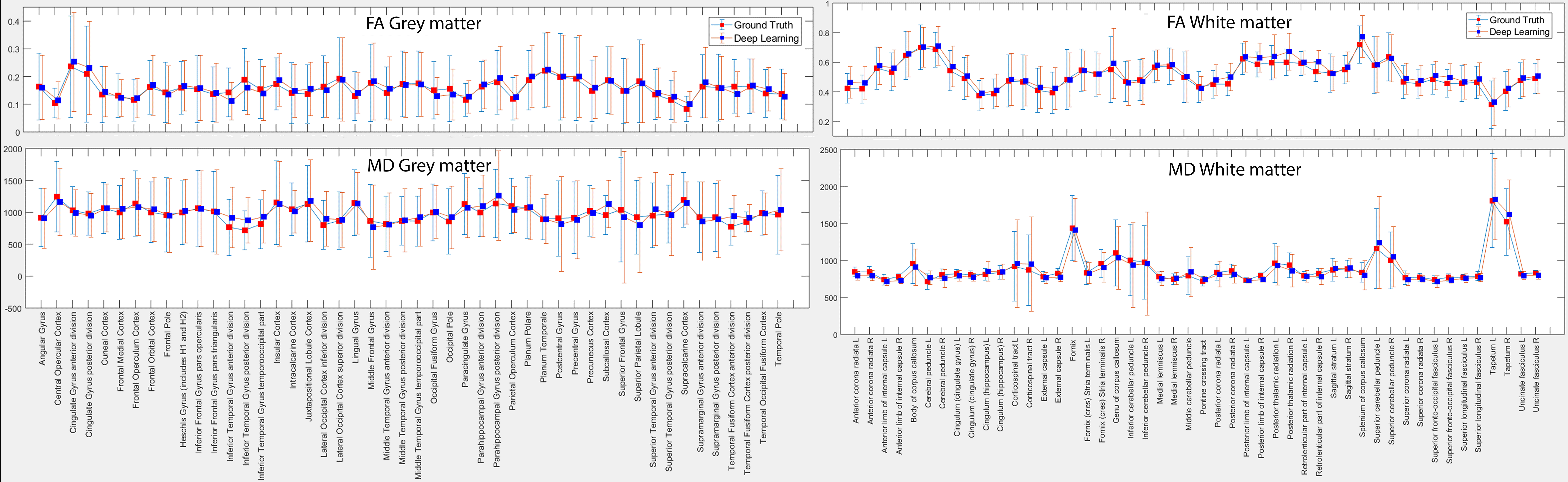
Figure 1 illustrates the ability of the deep-learning algorithm to produce high quality and high-resolution DWIs than regular bicubic interpolation. Figure 2 shows the ability of the algorithm to produce diffusion maps comparable to the ground-truth. High reconstruction errors were at the tissue boundaries, particularly between cerebrospinal fluid (CSF) and the brain parenchyma. Inside the brain, the reconstruction errors were less than 4%. For the ROI-based comparisons, the means and standard deviations of FA and MD were comparable in grey matter and white matter between the ground-truth image and the deep-learning high-resolution image (Figure 3).
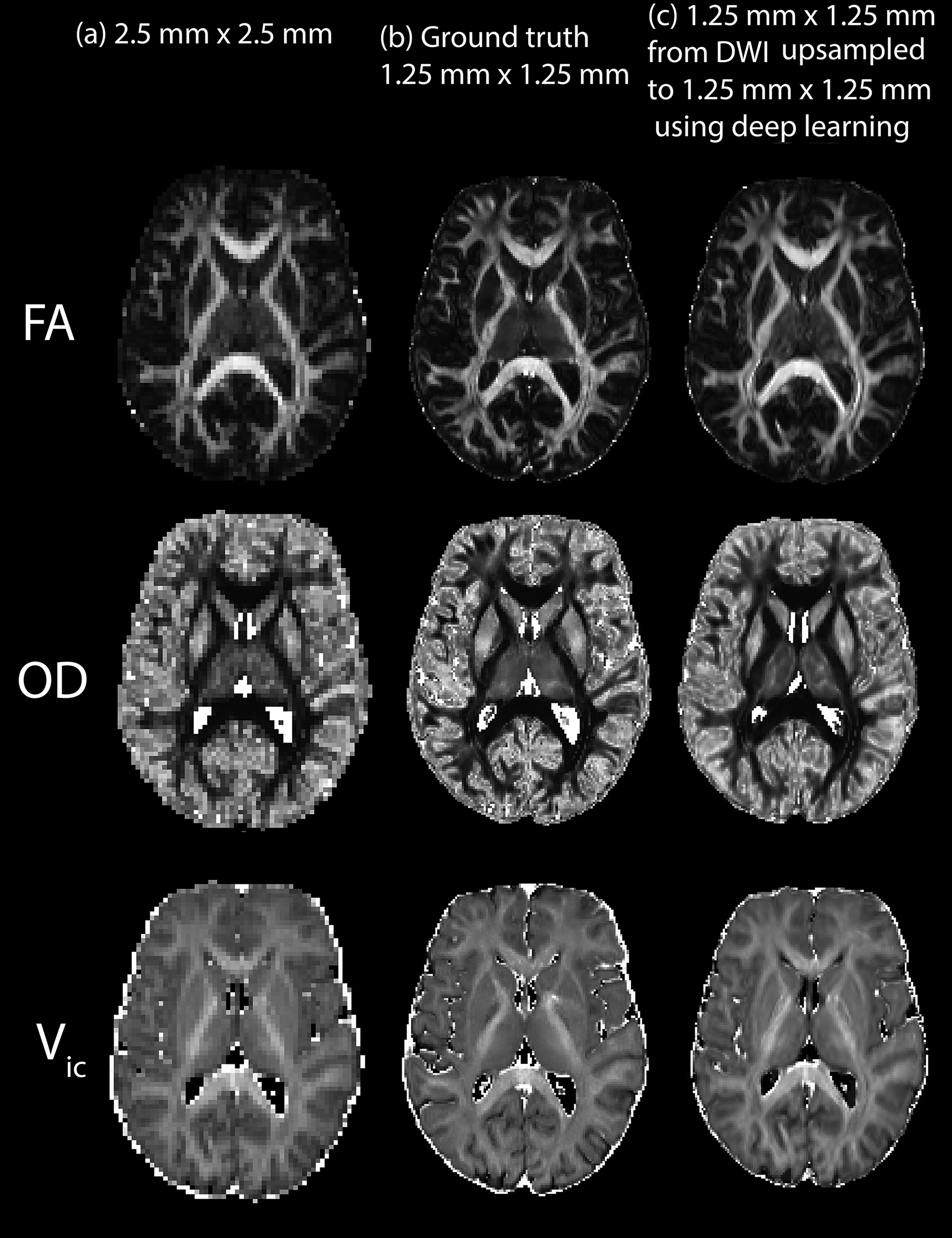
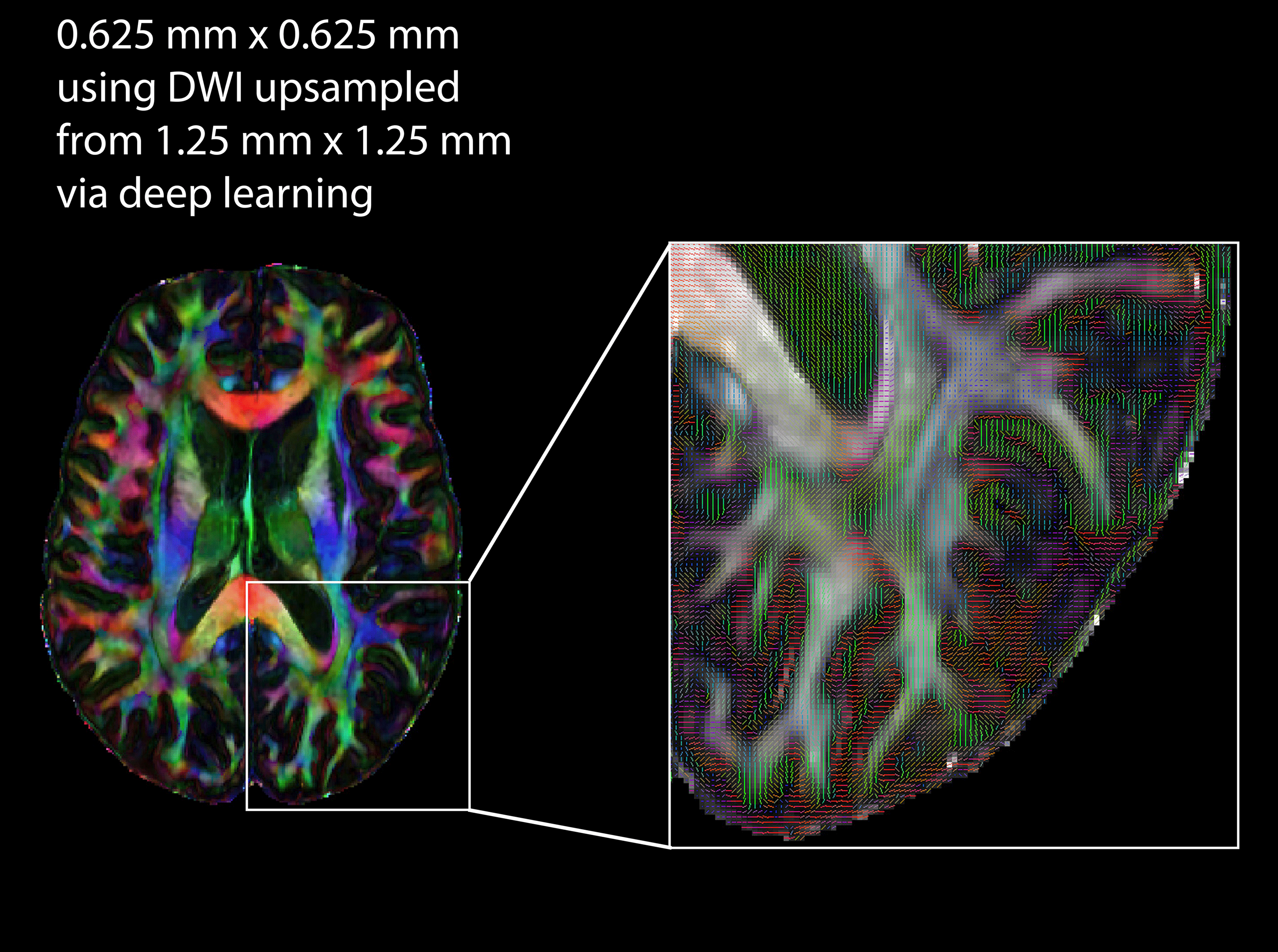
Figure 4 illustrates the ability of the proposed deep-learning method to yield quality diffusion metric maps (FA, OD and Vic) that are similar to diffusion metrics acquired at a true acquisition resolution. Finally, Figure 5 demonstrates directional information (i.e., major eigenvectors from DTI) from a deep-learning submillimeter resolution of 0.625x0.625 mm2 (learned from 1.25x1.25 mm2).
Conclusion
We have demonstrated the feasibility of deep-learning algorithm SR-CNN in diffusion imaging. Future work is to adapt the method to work with 3D CNN instead of 2D CNN to achieve accuracy in an isotropic form.Acknowledgements
The work is supported by grant NIH NIA R01 AG053993.References
1. Dong, C., Loy, C., He, K. & Tang, X., Image super-resolution using deep convolutional networks. IEEE Transactions on Pattern Analysis and Machine Intelligence 38, 295 - 307 (2016).
2. LeCun, Y. et al., Backpropagation applied to handwritten zip code recognition. Neural computation, 541-551 (1989).
3. Wu, Y.-C. & Alexander, A. L., Hybrid diffusion imaging. NeuroImage 36, 617-629 (2007).
4. Wu, Y.-C., Field, A. S. & Alexander, A. L., Computation of diffusion function measures in q-space using magnetic resonance hybrid diffusion imaging. IEEE Trans Med Imaging 27 (6), 858-865 (2008).
5. Manjón, J., Coupé, P., Concha, L., Buades, A. & Collins, D., Diffusion weighted image denoising using overcomplete local PCA. PLoS ONE 8 (9) (2013).
6. Andersson, J., Graham, M., Zsoldos, E. & Sotiropoulos, S., Incorporating outlier detection and replacement into a non-parametric framework for movement and distortion correction of diffusion MR images. NeuroImage 141, 556-572 (2016).
7. Lampinen, B. et al., Neurite density imaging versus imaging of microscopic anisotropy in diffusion MRI: A model comparison using spherical tensor encoding. NeuroImage 147, 517-531 (2017).
8. Mori, S., Wakana, S., van Zijl, P. & Nagae-Poetscher, L., MRI Atlas of Human White Matter (Elsevier, Amsterdam, The Netherlands, 2005).
9. Desikan, R. et al., An automated labeling system for subdividing the human cerebral cortex on MRI scans into gyral based regions of interest. NeuroImage 31, 968-980 (2006).
Figures