3300
Tissue microstructure information from T2 relaxometry and diffusion MRI can identify multiple sclerosis (MS) lesions undergoing blood-brain barrier breakdown (BBB)1Univ Rennes, Inria, Inserm, CNRS, IRISA UMR 6074, VISAGES - ERL U 1228, F-35000, Rennes, France, 2Computational Radiology Laboratory, Boston Children's Hospital, Harvard Medical School, Boston, MA, United States
Synopsis
Gadolinium based contrast agents (GBCA) play a critical role in identifying MS lesions undergoing BBB which is of high clinical importance. However, repeated use of GBCAs over a long period of time and the risks associated with administering it to patients with renal complications has mandated for greater caution in its usage. In this work we explored the plausibility of identifying MS lesions undergoing BBB from tissue microstructure information obtained from T2 relaxometry and dMRI data. We also proposed a framework to predict MS lesions undergoing BBB using the tissue microstructure information and demonstrated its potential on a test case.
Purpose
Identification of MS lesions undergoing BBB without use of gadolinium based contrast agents(GBCA).Introduction
Early stage MS lesions undergo BBB and appear hyperintense on T1-weighted images acquired post GBCA administration (also known as active lesions). The identification/presence of these lesions is an important clinical indicator of the disease stage and progression. Hence, MS patients undergo multiple MRI scans post GBCA administrations. However, Repeated GBCA usage leads to its deposition in the brain tissues1,2. GBCA administration to patients with renal complications is associated with high risks. Hence there is an increasing debate over its repeated usage. This work investigates the plausibility of identifying MS lesions undergoing BBB from tissue microstructure information obtained from T2 relaxometry and diffusion MRI (dMRI).Method
Multi-compartment models
Multi-compartment T2 relaxometry (MCT2) and dMRI (MCDiff) models are used to obtain the brain tissue microstructure information which are used to identify the Gd-active MS lesions.
MCT23,4: Each voxel is considered to have three compartments: short-T2: myelin and highly myelinated axons; medium-T2: mixed pool comprising of axons, intra/extracellular matter and high-T2: cerebrospinal fluids (and edema). The fraction of each compartment in a voxel, i.e. short-T2, medium-T2 and high-T2 weights are the MCT2 biomarkers.
MCDiff: We chose the ball and stick model5. Three anisotropic and a free water compartment were considered for each voxel. The estimations were performed as proposed by Stamm et al.6. Weighted averages of the scalar maps corresponding to each compartment were used as MCDiff biomarkers3: fractional anisotropy, apparent diffusion coefficient and axial diffusivity. The diffusion free water fraction was also used as a MCDiff biomarker.
Data specification
T2 relaxometry: echo time(TE)/repetition time(TR)/number of echoes/voxel resolution=13.8ms/4530ms/7/1.33x1.33x3.0mm3.
dMRI: 30-directions; b-value=1000s/mm2; TE/TR=94ms/9sec; voxel resolution=2x2x2mm3. T1-weighted images (1x1x3mm3) post GBCA infusion (0.1mmol/kg gadopentetate dimeglumine) were acquired to identify Gd-active lesions. All images and lesion annotations were registered to the T2-weighted image.
Our dataset had 11 patients with 21 Gd-active lesions (E+) and 173 late stage lesions (L-). The combined acquisition time of the T2 relaxometry and dMRI data was less than 14 minutes.
Experiment-1: Feature analysis
Lesion-wise statistics (median, variance, skewness, entropy) of the MCT2 and MCDiff values inside E+ and L- lesions were used as features describing each lesion. A Mann-Whitney U test was performed to observe the E+ and L- group differences for these features.
Experiment-2: Gd-active lesion detection
A framework is proposed to predict E+ lesions using the aforementioned features. The features for which the group differences were found to be significant (p<0.05) were considered for the lesion prediction task. The training set consisted of lesion information from 10 patients (162 L- and 19 E+ lesions). One patient case was not used for training at any stage (test case) on which the lesion detection performance was evaluated. The proposed method is shown in Figure-2. The imbalance in labels (much higher number of L- samples compared to E+) was compensated by adopting a random shuffle and repeat strategy (RSRS). For every repetition, some L- samples were randomly selected from the training set such that the ratio between L- and E+ sample was 3:2. A support vector machine (SVM) based classifier with radial basis function (RBF) kernel was used for prediction. A grid search hyperparameter optimization technique was performed to determine model parameters. The learnt model was used to predict the lesion type of the test case lesions at every repetition. 10000 repetitions were performed to ensure enough sample combinations were accounted for in the training phase. A voting score is generated for the 10000 predictions of each lesion in the test case on which a majority voting thresholding is done to predict the whether the lesion is E+/L-.
Results
Experiment-1
Statistics of the features are compared for E+ and L- groups as box plots in Figure-3 and Figure-4. Significant difference between E+ and L- groups (p<0.05) were observed for several statistics of the features.
Experiment-2
The training phase performance metrics are shown in Figure-5(a). The test case results are shown in Figure-5(b). Both E+ lesions present in the test case were correctly predicted and there were no false positives.
Discussion
The MCT2 and MCDiff features are able to identify MS lesions undergoing BBB from the others as these features provide information on demyelination, edema formation and axonal damage in the lesion affected brain tissues. We proposed a prediction framework to identify these lesions using statistics of MCT2 and MCDiff biomarkers values in a lesion and demonstrated its potential on a test case. In future works we plan to compute features describing the lesions groups more effectively and work with a better quality data to which state-of-the-art multi-compartment models can be applied.Acknowledgements
MRI data acquisition was supported by the Neurinfo MRI research facility from the University of Rennes I. Neurinfo is granted by the the European Union (FEDER), the French State, the Brittany Council, Rennes Metropole, Inria, Inserm and the University Hospital of Rennes. This research was also supported in part by the grants NIH R01 EB019483 and NIH R01 NS079788.References
- Kanda, T., Osawa, M., Oba, H., Toyoda, K., Kotoku, J.I., Haruyama, T., Takeshita, K. and Furui, S., 2015. High signal intensity in dentate nucleus on unenhanced T1-weighted MR images: association with linear versus macrocyclic gadolinium chelate administration. Radiology, 275(3), pp.803-809.
- Naganawa, S., Suzuki, K., Yamazaki, M., & Sakurai, Y. (2014). Serial scans in healthy volunteers following intravenous administration of gadoteridol: time course of contrast enhancement in various cranial fluid spaces. Magnetic Resonance in Medical Sciences, 13(1), 7-13.
- Chatterjee, S., Commowick, O., Afacan, O., Warfield, S.K. and Barillot, C., 2018, September. Identification of Gadolinium contrast enhanced regions in MS lesions using brain tissue microstructure information obtained from diffusion and T2 relaxometry MRI. In International Conference on Medical Image Computing and Computer-Assisted Intervention (pp. 63-71). Springer, Cham.
- Chatterjee, S., Commowick, O., Afacan, O., Combes, B., Warfield, S.K. and Barillot, C., 2018. A three year follow-up study of gadolinium enhanced and non-enhanced regions in multiple sclerosis lesions using a multi-compartment T2 relaxometry model. bioRxiv, p.365379.
- Panagiotaki, E., Schneider, T., Siow, B., Hall, M.G., Lythgoe, M.F. and Alexander, D.C., 2012. Compartment models of the diffusion MR signal in brain white matter: a taxonomy and comparison. Neuroimage, 59(3), pp.2241-2254.
- Stamm, A., Commowick, O., Warfield, S.K. and Vantini, S., 2016, October. Comprehensive Maximum Likelihood Estimation of Diffusion Compartment Models Towards Reliable Mapping of Brain Microstructure. In International Conference on Medical Image Computing and Computer-Assisted Intervention (pp. 622-630). Springer, Cham.
Figures
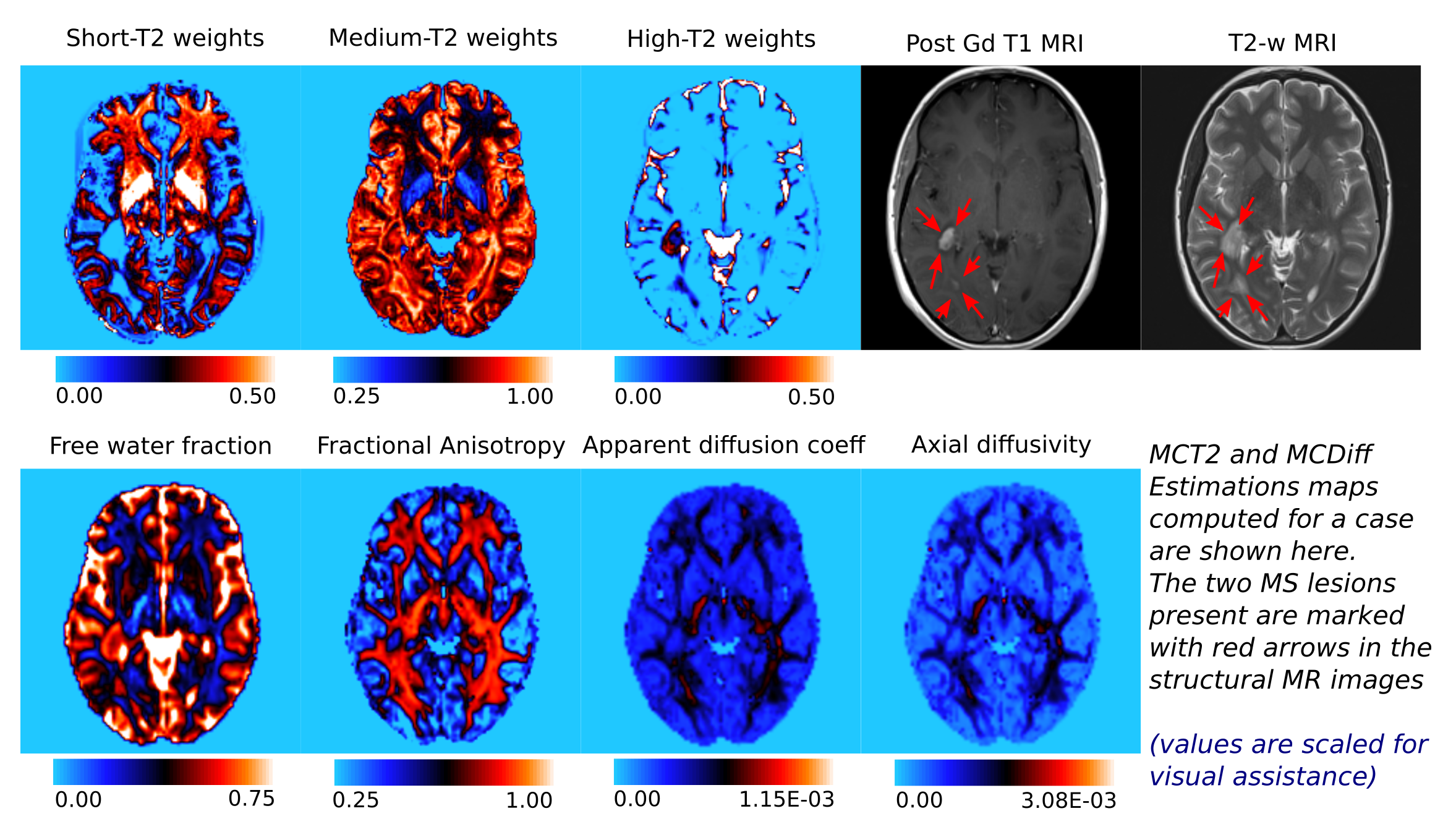
Figure-5:(a) Sensitivity, specificity, positive predictive value (PPV), negative predictive value (NPV) and overall accuracy for the training phase is shown. Since these values are computed over different training sets at each repetition (random shuffle and repeat strategy), the results are shown as notched box plots. (b) Test case had 11 L- and 2 E+ lesions. A majority voting thresholding was performed on the voting score (of 10000 predictions) to predict the lesion category. Whereas the test case decision is performed on 10000 predictions, training phase performance is reported on single instance predictions. This explains the superior test case performance.