3091
Evidence pinpointing of Intervertebral disc herniation with weak supervision1College of Engineering, Peking University, Beijing, China, 2Department of Radiology, Peking University First Hospital, Beijing, China, 3Academy for Advanced Interdisciplinary Studies, Peking University, Beijing, China
Synopsis
Deep learning has shown encouraging performance for lesion detection, but it is limited due to the high requirement of data labeling. In the task of lumbar intervertebral disc herniation recognition, we proposed to develop a recognition method based on axial images, which include more anatomical information about the disc, using a convolutional network. And we attempt to provide possible pathological evidence from the weakly labeled training data (normal/herniated label on image level).
Introduction
Intervertebral disc (IVD) herniation is the most prevalent lumbar disease, which accounts for 40% of low back pain, leading to enormous economic losses. Existing methods were based on mid-sagittal images, causing non-central herniation undetected quite often1,2. Moreover, they usually employed hand-crafted features to form the recognition systems, incapable of dealing with the interclass overlapping of different grading IVDs and intraclass variation. And the systems were limited because only whether there was herniation on image level was obtained, without evidence relating to the presence or absence of pathology. In this study, we propose to develop a disc herniation recognition method based on axial images, which include more anatomical information about the IVD, using a convolutional network. And we attempt to provide possible pathological evidence from the weakly labeled training data (normal/herniated label on image level).Method
In this retrospective study, the labeled data collected from routine clinics consists of T2-weighted MRI scans of 208 patients under varied lumbar diseases, such as degeneration, herniation and scoliosis. There are 1040 individual IVDs, including their corresponding radiological labels of herniation. The annotations of whether there was herniation were assessed by an expert spinal radiologist. The full dataset was split into three datasets as training (70%), validation (10%) and testing (20%).
Lesion detection is an object detection task. Conventional methods for general object detection in the computer vision domain train an object classifier with detailed image annotation, e.g. bounding boxes or manual segmentation of objects. These methods require detailed annotation to indicate exact locations of cancers for training. This requirement is very time-consuming and demands special expertise, prohibiting the acquisition of sufficient training data and in turn limiting its clinical application. In this study, we describe how to generate evidence map by learning a weakly-supervised CNN based on only image-level labels (normal/herniated).
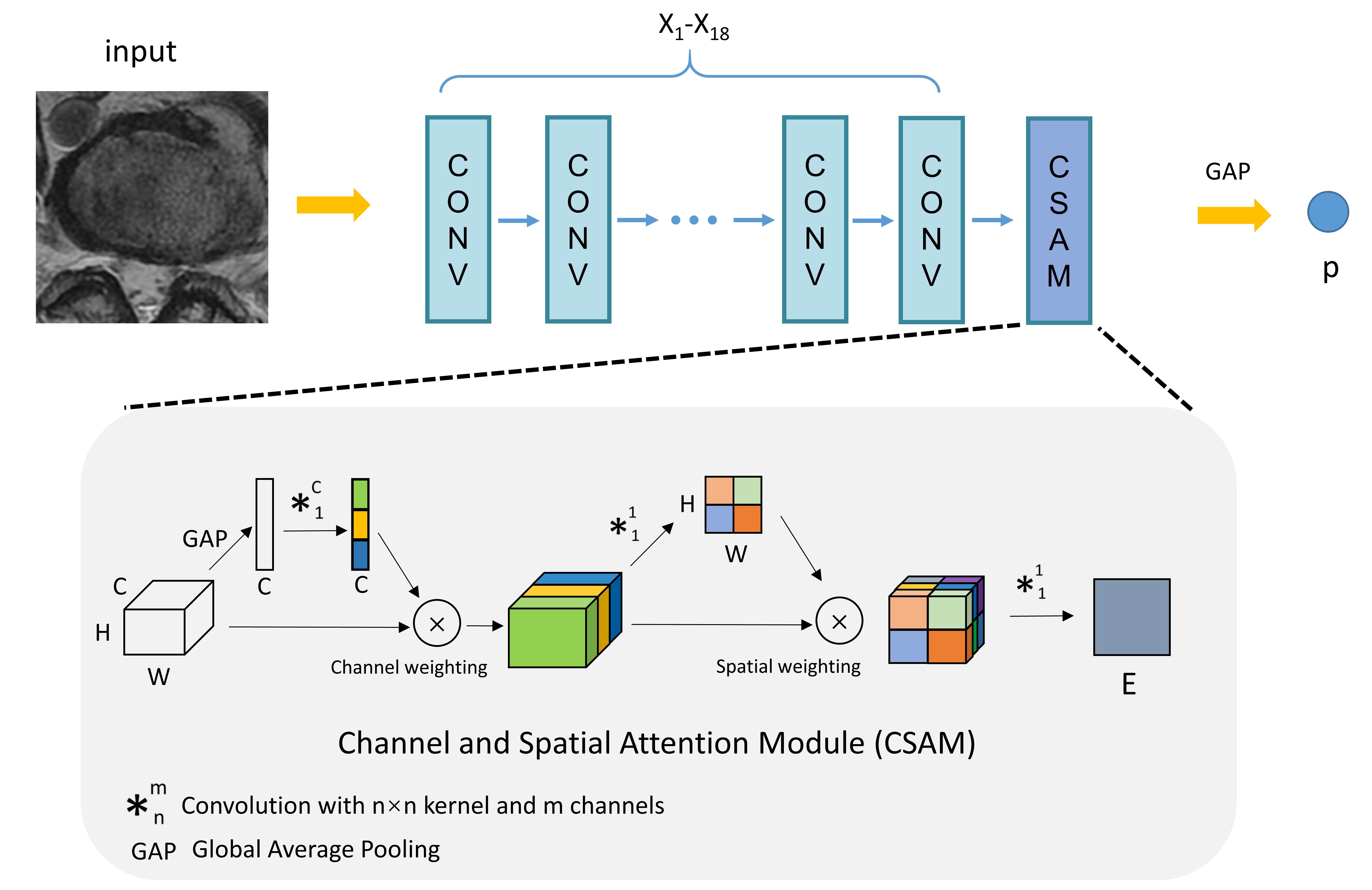
We employed a CNN architecture with residual connection. But different from the standard CNN structure, we removed its fully connected layers and replace them with a channel and spatial attention module instead. After the convolution procedures of $$$X_{1}-X_{18}$$$, the spatial size of the convolutional feature map becomes $$$(W × H)$$$, and the number of feature maps is $$$C$$$. These feature maps are referred as $$$M_{k}(x,y)$$$.
Recently, attention mechanism by explicitly modeling the interdependencies between the channels of feature maps has been proved an effective method to emphasize on useful channels3. In this work, we want to leverage the high performance of SE blocks to emphasize the attention capability and produce evidence map related to pathology. Except for the original SE block, which reweights along the channels, we added a spatial reweighting operation following it. We hypothesize that the pixel-wise spatial information is more informative. This attention could tell where to focus. We constructed the improved attention module by integrating the original channel attention and the proposed spatial attention, termed as channel and spatial attention module (CSAM). This architecture is illustrated in Fig.1. Firstly, the features of $$$X_{18}$$$ is reweighted channel-wise by the original SE block, and then reweighted pixel-wise by the learned spatial weights. We then add a convolution layer to yield a single feature map.
Based on prior studies4 we know that each feature map of $$$X_{18}$$$ highlights visual patterns at spatial locations which correspond to the related object categories. Feature map $$$E$$$ is therefore a channel and spatial weighted feature map of the presence of these visual patterns, from which we can hence identify the spatial locations most relevant to each category (i.e. herniated or non-herniated). Finally, to obtain a single image-level score representing the probability ($$$p$$$) of this image containing herniation, a global average pooling (GAP) was utilized.
Results&Discussion
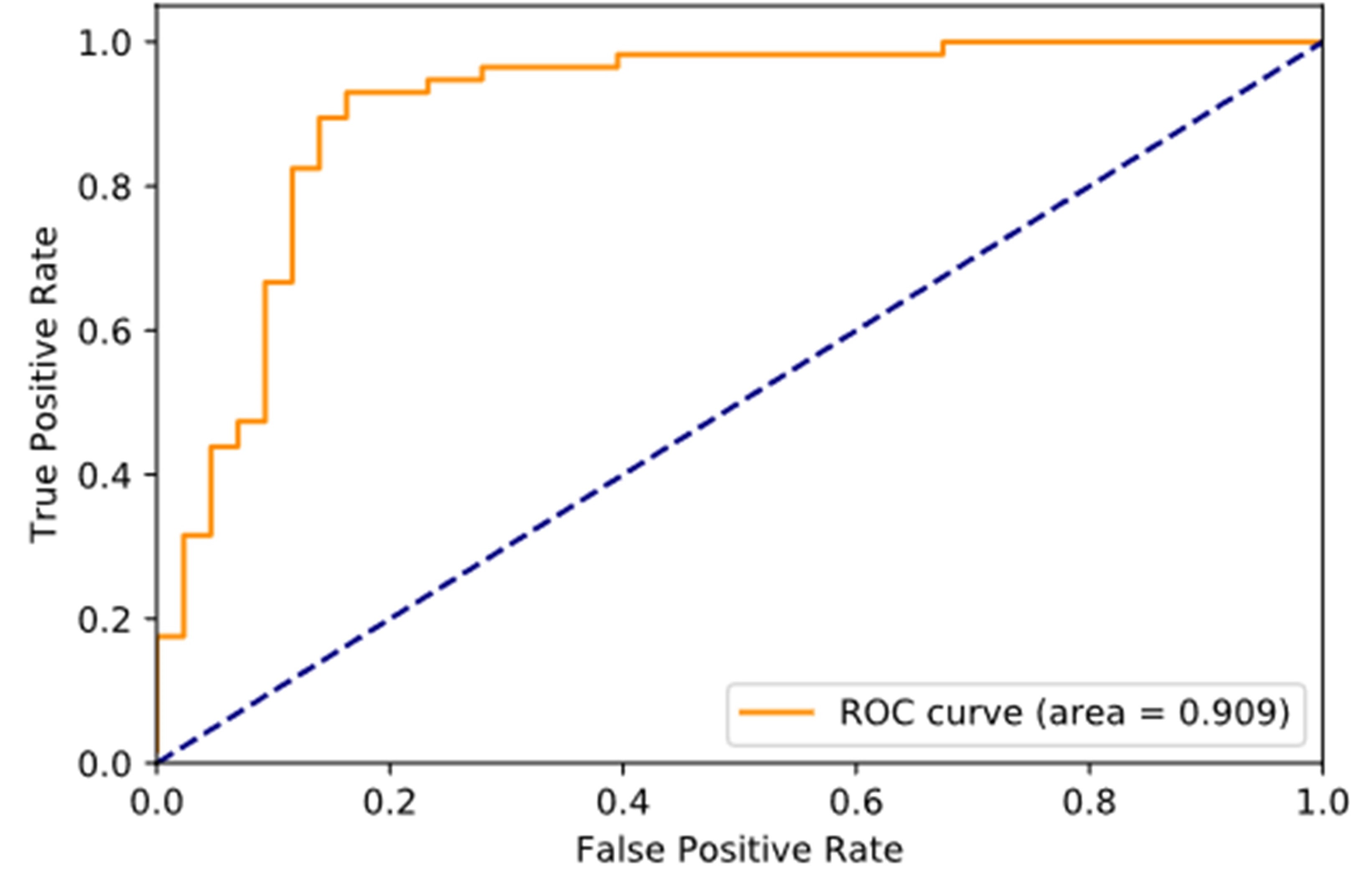
We employed accuracy and ROC curve to evaluate the performance of our CNN model for image-level herniated vs. non-herniated classification. In our experiments, the classification accuracy is 0.88, and the ROC curve is showed as figure 2, obtaining an AUC value of 0.909.
As shown in figure 3, the weakly-supervised model can produce informative evidence map pinpointing the suspicious herniated region, close to the ‘ground truth’ bounding box annotated by a clinician. Unlike conventional methods, using weak supervision, the developed model did not require any lesion location label in training but still produced reliable predictions.
Conclusion
In this study, we proposed a weakly-supervised automated analysis method using deep convolutional network based on axial images for lumbar intervertebral disc herniation. The classification results demonstrated its feasibility for image-level recognition. Encouragingly, the model can also produce reliable evidence map that can aid understanding of the predictions of models trained only on weak class labels.Acknowledgements
No acknowledgement found.References
[1] S. Ghosh, R. S. Alomari, V. Chaudhary, and G. Dhillon, "Composite Features for Automatic Diagnosis of Intervertebral Disc Herniation from Lumbar MRI," (in English), 2011 Annual International Conference of the Ieee Engineering in Medicine and Biology Society (Embc), pp. 5068-5071, 2011.
[2] S. Ghosh, R. S. Alomari, V. Chaudhary, and G. Dhillon, "Computer-Aided Diagnosis for Lumbar Mri Using Heterogeneous Classifiers," (in English), 2011 8th Ieee International Symposium on Biomedical Imaging: From Nano to Macro, pp. 1179-1182, 2011.
[3] J. Hu, L. Shen, and G. Sun, "Squeeze-and-excitation networks," arXiv preprint arXiv:1709.01507, vol. 7, 2017.
[4] B. Zhou, A. Khosla, A. Lapedriza, A. Oliva, and A. Torralba, "Learning deep features for discriminative localization," in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2016, pp. 2921-2929.
Figures